 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDuoGen: Towards General Purpose Interleaved Multimodal Generation
Feb 03, 2026Interleaved multimodal generation enables capabilities beyond unimodal generation models, such as step-by-step instructional guides, visual planning, and generating visual drafts for reasoning. However, the quality of existing interleaved generation models under general instructions remains limited by insufficient training data and base model capacity. We present DuoGen, a general-purpose interleaved generation framework that systematically addresses data curation, architecture design, and evaluation. On the data side, we build a large-scale, high-quality instruction-tuning dataset by combining multimodal conversations rewritten from curated raw websites, and diverse synthetic examples covering everyday scenarios. Architecturally, DuoGen leverages the strong visual understanding of a pretrained multimodal LLM and the visual generation capabilities of a diffusion transformer (DiT) pretrained on video generation, avoiding costly unimodal pretraining and enabling flexible base model selection. A two-stage decoupled strategy first instruction-tunes the MLLM, then aligns DiT with it using curated interleaved image-text sequences. Across public and newly proposed benchmarks, DuoGen outperforms prior open-source models in text quality, image fidelity, and image-context alignment, and also achieves state-of-the-art performance on text-to-image and image editing among unified generation models. Data and code will be released at https://research.nvidia.com/labs/dir/duogen/.
Cosmos-Transfer1: Conditional World Generation with Adaptive Multimodal Control
Mar 18, 2025We introduce Cosmos-Transfer, a conditional world generation model that can generate world simulations based on multiple spatial control inputs of various modalities such as segmentation, depth, and edge. In the design, the spatial conditional scheme is adaptive and customizable. It allows weighting different conditional inputs differently at different spatial locations. This enables highly controllable world generation and finds use in various world-to-world transfer use cases, including Sim2Real. We conduct extensive evaluations to analyze the proposed model and demonstrate its applications for Physical AI, including robotics Sim2Real and autonomous vehicle data enrichment. We further demonstrate an inference scaling strategy to achieve real-time world generation with an NVIDIA GB200 NVL72 rack. To help accelerate research development in the field, we open-source our models and code at https://github.com/nvidia-cosmos/cosmos-transfer1.
Cosmos-Reason1: From Physical Common Sense To Embodied Reasoning
Mar 18, 2025Physical AI systems need to perceive, understand, and perform complex actions in the physical world. In this paper, we present the Cosmos-Reason1 models that can understand the physical world and generate appropriate embodied decisions (e.g., next step action) in natural language through long chain-of-thought reasoning processes. We begin by defining key capabilities for Physical AI reasoning, with a focus on physical common sense and embodied reasoning. To represent physical common sense, we use a hierarchical ontology that captures fundamental knowledge about space, time, and physics. For embodied reasoning, we rely on a two-dimensional ontology that generalizes across different physical embodiments. Building on these capabilities, we develop two multimodal large language models, Cosmos-Reason1-8B and Cosmos-Reason1-56B. We curate data and train our models in four stages: vision pre-training, general supervised fine-tuning (SFT), Physical AI SFT, and Physical AI reinforcement learning (RL) as the post-training. To evaluate our models, we build comprehensive benchmarks for physical common sense and embodied reasoning according to our ontologies. Evaluation results show that Physical AI SFT and reinforcement learning bring significant improvements. To facilitate the development of Physical AI, we will make our code and pre-trained models available under the NVIDIA Open Model License at https://github.com/nvidia-cosmos/cosmos-reason1.
Cosmos World Foundation Model Platform for Physical AI
Jan 07, 2025



Physical AI needs to be trained digitally first. It needs a digital twin of itself, the policy model, and a digital twin of the world, the world model. In this paper, we present the Cosmos World Foundation Model Platform to help developers build customized world models for their Physical AI setups. We position a world foundation model as a general-purpose world model that can be fine-tuned into customized world models for downstream applications. Our platform covers a video curation pipeline, pre-trained world foundation models, examples of post-training of pre-trained world foundation models, and video tokenizers. To help Physical AI builders solve the most critical problems of our society, we make our platform open-source and our models open-weight with permissive licenses available via https://github.com/NVIDIA/Cosmos.
LCA-on-the-Line: Benchmarking Out-of-Distribution Generalization with Class Taxonomies
Jul 22, 2024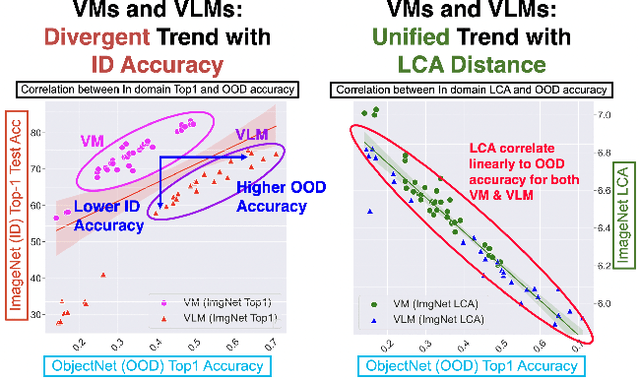
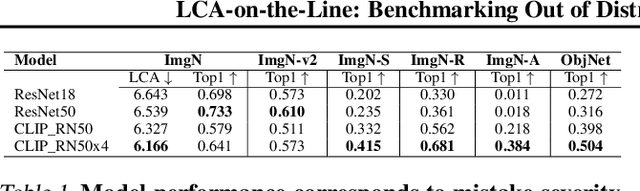
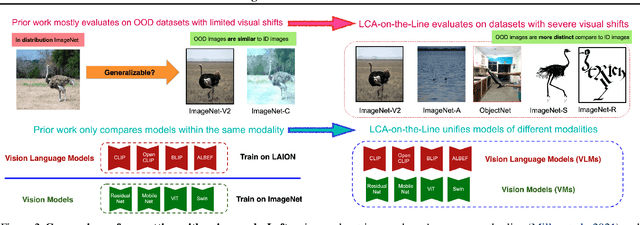
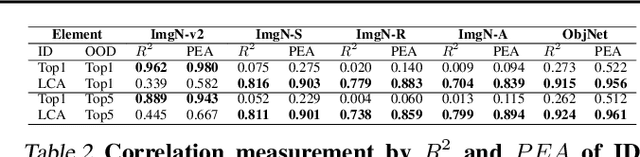
We tackle the challenge of predicting models' Out-of-Distribution (OOD) performance using in-distribution (ID) measurements without requiring OOD data. Existing evaluations with "Effective Robustness", which use ID accuracy as an indicator of OOD accuracy, encounter limitations when models are trained with diverse supervision and distributions, such as class labels (Vision Models, VMs, on ImageNet) and textual descriptions (Visual-Language Models, VLMs, on LAION). VLMs often generalize better to OOD data than VMs despite having similar or lower ID performance. To improve the prediction of models' OOD performance from ID measurements, we introduce the Lowest Common Ancestor (LCA)-on-the-Line framework. This approach revisits the established concept of LCA distance, which measures the hierarchical distance between labels and predictions within a predefined class hierarchy, such as WordNet. We assess 75 models using ImageNet as the ID dataset and five significantly shifted OOD variants, uncovering a strong linear correlation between ID LCA distance and OOD top-1 accuracy. Our method provides a compelling alternative for understanding why VLMs tend to generalize better. Additionally, we propose a technique to construct a taxonomic hierarchy on any dataset using K-means clustering, demonstrating that LCA distance is robust to the constructed taxonomic hierarchy. Moreover, we demonstrate that aligning model predictions with class taxonomies, through soft labels or prompt engineering, can enhance model generalization. Open source code in our Project Page: https://elvishelvis.github.io/papers/lca/.
Better Call SAL: Towards Learning to Segment Anything in Lidar
Mar 19, 2024



We propose $\texttt{SAL}$ ($\texttt{S}$egment $\texttt{A}$nything in $\texttt{L}$idar) method consisting of a text-promptable zero-shot model for segmenting and classifying any object in Lidar, and a pseudo-labeling engine that facilitates model training without manual supervision. While the established paradigm for $\textit{Lidar Panoptic Segmentation}$ (LPS) relies on manual supervision for a handful of object classes defined a priori, we utilize 2D vision foundation models to generate 3D supervision "for free". Our pseudo-labels consist of instance masks and corresponding CLIP tokens, which we lift to Lidar using calibrated multi-modal data. By training our model on these labels, we distill the 2D foundation models into our Lidar $\texttt{SAL}$ model. Even without manual labels, our model achieves $91\%$ in terms of class-agnostic segmentation and $44\%$ in terms of zero-shot LPS of the fully supervised state-of-the-art. Furthermore, we outperform several baselines that do not distill but only lift image features to 3D. More importantly, we demonstrate that $\texttt{SAL}$ supports arbitrary class prompts, can be easily extended to new datasets, and shows significant potential to improve with increasing amounts of self-labeled data.
SeMoLi: What Moves Together Belongs Together
Feb 29, 2024



We tackle semi-supervised object detection based on motion cues. Recent results suggest that heuristic-based clustering methods in conjunction with object trackers can be used to pseudo-label instances of moving objects and use these as supervisory signals to train 3D object detectors in Lidar data without manual supervision. We re-think this approach and suggest that both, object detection, as well as motion-inspired pseudo-labeling, can be tackled in a data-driven manner. We leverage recent advances in scene flow estimation to obtain point trajectories from which we extract long-term, class-agnostic motion patterns. Revisiting correlation clustering in the context of message passing networks, we learn to group those motion patterns to cluster points to object instances. By estimating the full extent of the objects, we obtain per-scan 3D bounding boxes that we use to supervise a Lidar object detection network. Our method not only outperforms prior heuristic-based approaches (57.5 AP, +14 improvement over prior work), more importantly, we show we can pseudo-label and train object detectors across datasets.
Lidar Panoptic Segmentation and Tracking without Bells and Whistles
Oct 19, 2023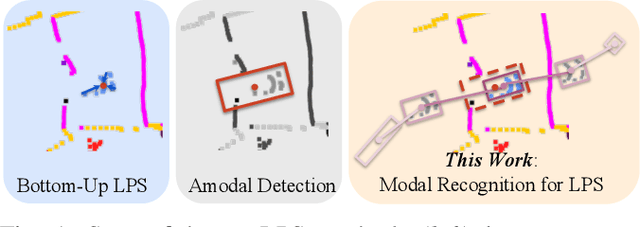
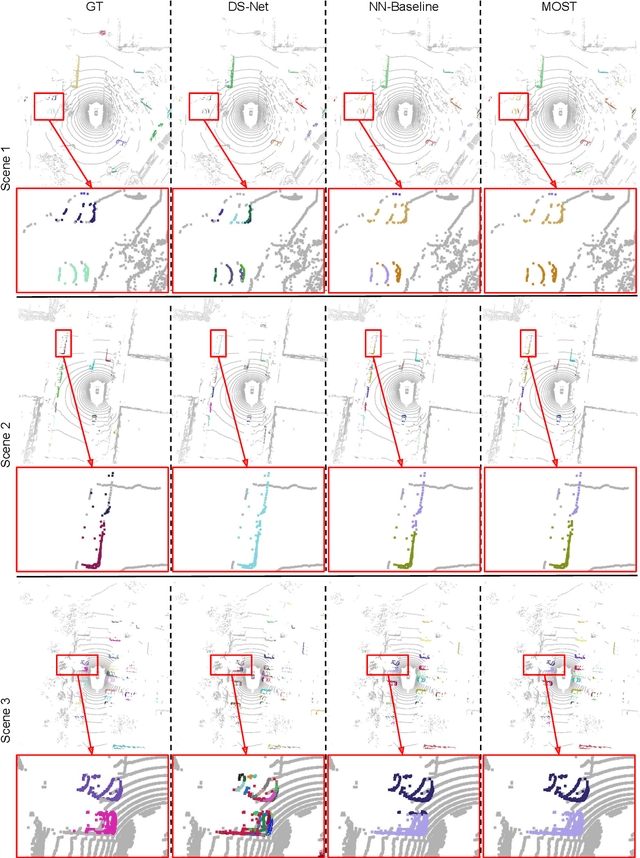
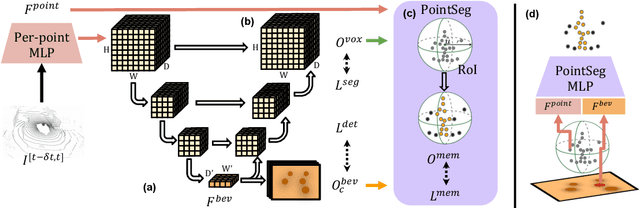
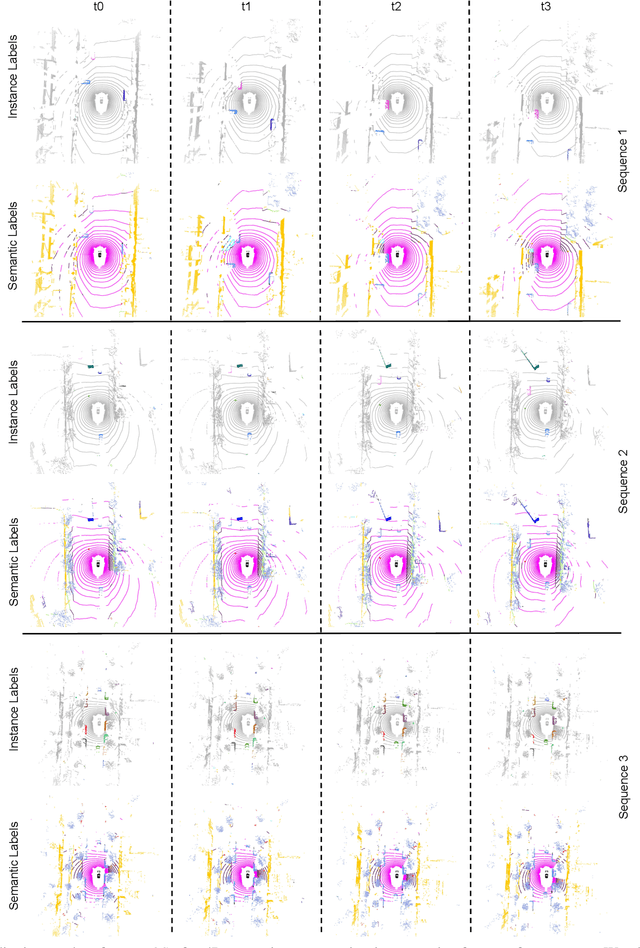
State-of-the-art lidar panoptic segmentation (LPS) methods follow bottom-up segmentation-centric fashion wherein they build upon semantic segmentation networks by utilizing clustering to obtain object instances. In this paper, we re-think this approach and propose a surprisingly simple yet effective detection-centric network for both LPS and tracking. Our network is modular by design and optimized for all aspects of both the panoptic segmentation and tracking task. One of the core components of our network is the object instance detection branch, which we train using point-level (modal) annotations, as available in segmentation-centric datasets. In the absence of amodal (cuboid) annotations, we regress modal centroids and object extent using trajectory-level supervision that provides information about object size, which cannot be inferred from single scans due to occlusions and the sparse nature of the lidar data. We obtain fine-grained instance segments by learning to associate lidar points with detected centroids. We evaluate our method on several 3D/4D LPS benchmarks and observe that our model establishes a new state-of-the-art among open-sourced models, outperforming recent query-based models.
Thinking Like an Annotator: Generation of Dataset Labeling Instructions
Jun 24, 2023Large-scale datasets are essential to modern day deep learning. Advocates argue that understanding these methods requires dataset transparency (e.g. "dataset curation, motivation, composition, collection process, etc..."). However, almost no one has suggested the release of the detailed definitions and visual category examples provided to annotators - information critical to understanding the structure of the annotations present in each dataset. These labels are at the heart of public datasets, yet few datasets include the instructions that were used to generate them. We introduce a new task, Labeling Instruction Generation, to address missing publicly available labeling instructions. In Labeling Instruction Generation, we take a reasonably annotated dataset and: 1) generate a set of examples that are visually representative of each category in the dataset; 2) provide a text label that corresponds to each of the examples. We introduce a framework that requires no model training to solve this task and includes a newly created rapid retrieval system that leverages a large, pre-trained vision and language model. This framework acts as a proxy to human annotators that can help to both generate a final labeling instruction set and evaluate its quality. Our framework generates multiple diverse visual and text representations of dataset categories. The optimized instruction set outperforms our strongest baseline across 5 folds by 7.06 mAP for NuImages and 12.9 mAP for COCO.
Fast Neural Scene Flow
Apr 20, 2023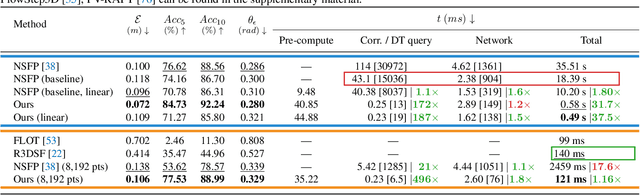



Neural Scene Flow Prior (NSFP) is of significant interest to the vision community due to its inherent robustness to out-of-distribution (OOD) effects and its ability to deal with dense lidar points. The approach utilizes a coordinate neural network to estimate scene flow at runtime, without any training. However, it is up to 100 times slower than current state-of-the-art learning methods. In other applications such as image, video, and radiance function reconstruction innovations in speeding up the runtime performance of coordinate networks have centered upon architectural changes. In this paper, we demonstrate that scene flow is different -- with the dominant computational bottleneck stemming from the loss function itself (i.e., Chamfer distance). Further, we rediscover the distance transform (DT) as an efficient, correspondence-free loss function that dramatically speeds up the runtime optimization. Our fast neural scene flow (FNSF) approach reports for the first time real-time performance comparable to learning methods, without any training or OOD bias on two of the largest open autonomous driving (AV) lidar datasets Waymo Open and Argoverse.