 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Zoom and Unzoom
Mar 27, 2023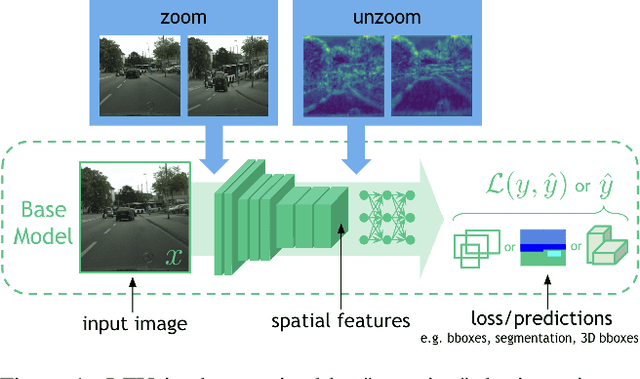



Many perception systems in mobile computing, autonomous navigation, and AR/VR face strict compute constraints that are particularly challenging for high-resolution input images. Previous works propose nonuniform downsamplers that "learn to zoom" on salient image regions, reducing compute while retaining task-relevant image information. However, for tasks with spatial labels (such as 2D/3D object detection and semantic segmentation), such distortions may harm performance. In this work (LZU), we "learn to zoom" in on the input image, compute spatial features, and then "unzoom" to revert any deformations. To enable efficient and differentiable unzooming, we approximate the zooming warp with a piecewise bilinear mapping that is invertible. LZU can be applied to any task with 2D spatial input and any model with 2D spatial features, and we demonstrate this versatility by evaluating on a variety of tasks and datasets: object detection on Argoverse-HD, semantic segmentation on Cityscapes, and monocular 3D object detection on nuScenes. Interestingly, we observe boosts in performance even when high-resolution sensor data is unavailable, implying that LZU can be used to "learn to upsample" as well.
FOVEA: Foveated Image Magnification for Autonomous Navigation
Aug 27, 2021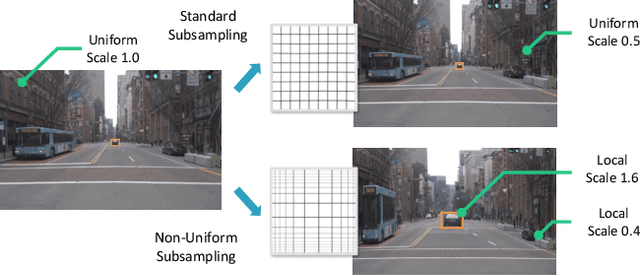

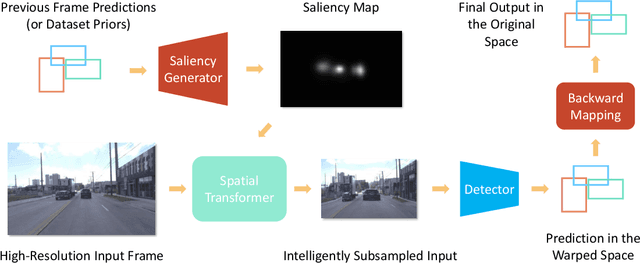
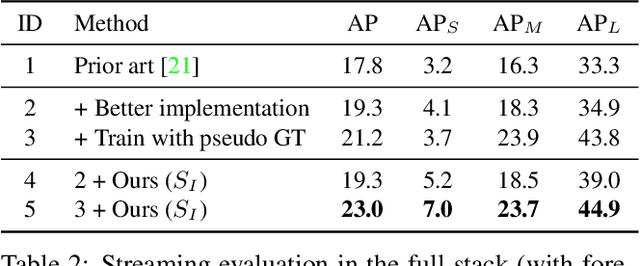
Efficient processing of high-resolution video streams is safety-critical for many robotics applications such as autonomous driving. Image downsampling is a commonly adopted technique to ensure the latency constraint is met. However, this naive approach greatly restricts an object detector's capability to identify small objects. In this paper, we propose an attentional approach that elastically magnifies certain regions while maintaining a small input canvas. The magnified regions are those that are believed to have a high probability of containing an object, whose signal can come from a dataset-wide prior or frame-level prior computed from recent object predictions. The magnification is implemented by a KDE-based mapping to transform the bounding boxes into warping parameters, which are then fed into an image sampler with anti-cropping regularization. The detector is then fed with the warped image and we apply a differentiable backward mapping to get bounding box outputs in the original space. Our regional magnification allows algorithms to make better use of high-resolution input without incurring the cost of high-resolution processing. On the autonomous driving datasets Argoverse-HD and BDD100K, we show our proposed method boosts the detection AP over standard Faster R-CNN, with and without finetuning. Additionally, building on top of the previous state-of-the-art in streaming detection, our method sets a new record for streaming AP on Argoverse-HD (from 17.8 to 23.0 on a GTX 1080 Ti GPU), suggesting that it has achieved a superior accuracy-latency tradeoff.