 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOmniTransfer: All-in-one Framework for Spatio-temporal Video Transfer
Jan 20, 2026Videos convey richer information than images or text, capturing both spatial and temporal dynamics. However, most existing video customization methods rely on reference images or task-specific temporal priors, failing to fully exploit the rich spatio-temporal information inherent in videos, thereby limiting flexibility and generalization in video generation. To address these limitations, we propose OmniTransfer, a unified framework for spatio-temporal video transfer. It leverages multi-view information across frames to enhance appearance consistency and exploits temporal cues to enable fine-grained temporal control. To unify various video transfer tasks, OmniTransfer incorporates three key designs: Task-aware Positional Bias that adaptively leverages reference video information to improve temporal alignment or appearance consistency; Reference-decoupled Causal Learning separating reference and target branches to enable precise reference transfer while improving efficiency; and Task-adaptive Multimodal Alignment using multimodal semantic guidance to dynamically distinguish and tackle different tasks. Extensive experiments show that OmniTransfer outperforms existing methods in appearance (ID and style) and temporal transfer (camera movement and video effects), while matching pose-guided methods in motion transfer without using pose, establishing a new paradigm for flexible, high-fidelity video generation.
DreamStyle: A Unified Framework for Video Stylization
Jan 06, 2026Video stylization, an important downstream task of video generation models, has not yet been thoroughly explored. Its input style conditions typically include text, style image, and stylized first frame. Each condition has a characteristic advantage: text is more flexible, style image provides a more accurate visual anchor, and stylized first frame makes long-video stylization feasible. However, existing methods are largely confined to a single type of style condition, which limits their scope of application. Additionally, their lack of high-quality datasets leads to style inconsistency and temporal flicker. To address these limitations, we introduce DreamStyle, a unified framework for video stylization, supporting (1) text-guided, (2) style-image-guided, and (3) first-frame-guided video stylization, accompanied by a well-designed data curation pipeline to acquire high-quality paired video data. DreamStyle is built on a vanilla Image-to-Video (I2V) model and trained using a Low-Rank Adaptation (LoRA) with token-specific up matrices that reduces the confusion among different condition tokens. Both qualitative and quantitative evaluations demonstrate that DreamStyle is competent in all three video stylization tasks, and outperforms the competitors in style consistency and video quality.
GaussianMorphing: Mesh-Guided 3D Gaussians for Semantic-Aware Object Morphing
Oct 02, 2025We introduce GaussianMorphing, a novel framework for semantic-aware 3D shape and texture morphing from multi-view images. Previous approaches usually rely on point clouds or require pre-defined homeomorphic mappings for untextured data. Our method overcomes these limitations by leveraging mesh-guided 3D Gaussian Splatting (3DGS) for high-fidelity geometry and appearance modeling. The core of our framework is a unified deformation strategy that anchors 3DGaussians to reconstructed mesh patches, ensuring geometrically consistent transformations while preserving texture fidelity through topology-aware constraints. In parallel, our framework establishes unsupervised semantic correspondence by using the mesh topology as a geometric prior and maintains structural integrity via physically plausible point trajectories. This integrated approach preserves both local detail and global semantic coherence throughout the morphing process with out requiring labeled data. On our proposed TexMorph benchmark, GaussianMorphing substantially outperforms prior 2D/3D methods, reducing color consistency error ($\Delta E$) by 22.2% and EI by 26.2%. Project page: https://baiyunshu.github.io/GAUSSIANMORPHING.github.io/
GTAD: Global Temporal Aggregation Denoising Learning for 3D Semantic Occupancy Prediction
Jul 28, 2025Accurately perceiving dynamic environments is a fundamental task for autonomous driving and robotic systems. Existing methods inadequately utilize temporal information, relying mainly on local temporal interactions between adjacent frames and failing to leverage global sequence information effectively. To address this limitation, we investigate how to effectively aggregate global temporal features from temporal sequences, aiming to achieve occupancy representations that efficiently utilize global temporal information from historical observations. For this purpose, we propose a global temporal aggregation denoising network named GTAD, introducing a global temporal information aggregation framework as a new paradigm for holistic 3D scene understanding. Our method employs an in-model latent denoising network to aggregate local temporal features from the current moment and global temporal features from historical sequences. This approach enables the effective perception of both fine-grained temporal information from adjacent frames and global temporal patterns from historical observations. As a result, it provides a more coherent and comprehensive understanding of the environment. Extensive experiments on the nuScenes and Occ3D-nuScenes benchmark and ablation studies demonstrate the superiority of our method.
DreamO: A Unified Framework for Image Customization
Apr 23, 2025Recently, extensive research on image customization (e.g., identity, subject, style, background, etc.) demonstrates strong customization capabilities in large-scale generative models. However, most approaches are designed for specific tasks, restricting their generalizability to combine different types of condition. Developing a unified framework for image customization remains an open challenge. In this paper, we present DreamO, an image customization framework designed to support a wide range of tasks while facilitating seamless integration of multiple conditions. Specifically, DreamO utilizes a diffusion transformer (DiT) framework to uniformly process input of different types. During training, we construct a large-scale training dataset that includes various customization tasks, and we introduce a feature routing constraint to facilitate the precise querying of relevant information from reference images. Additionally, we design a placeholder strategy that associates specific placeholders with conditions at particular positions, enabling control over the placement of conditions in the generated results. Moreover, we employ a progressive training strategy consisting of three stages: an initial stage focused on simple tasks with limited data to establish baseline consistency, a full-scale training stage to comprehensively enhance the customization capabilities, and a final quality alignment stage to correct quality biases introduced by low-quality data. Extensive experiments demonstrate that the proposed DreamO can effectively perform various image customization tasks with high quality and flexibly integrate different types of control conditions.
FilmComposer: LLM-Driven Music Production for Silent Film Clips
Mar 11, 2025
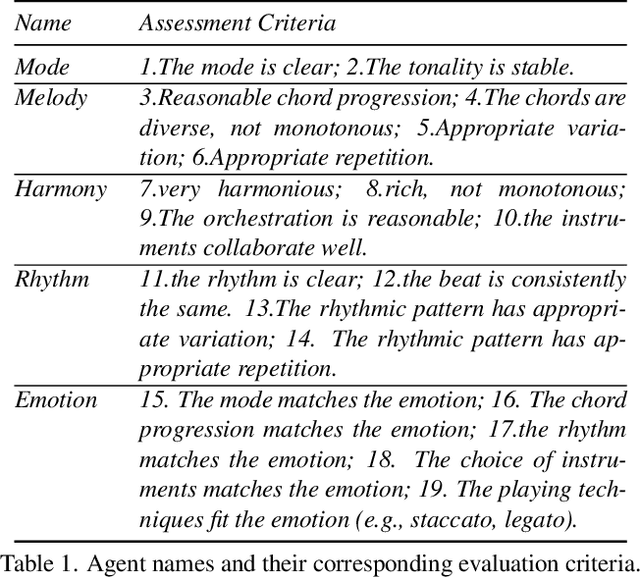
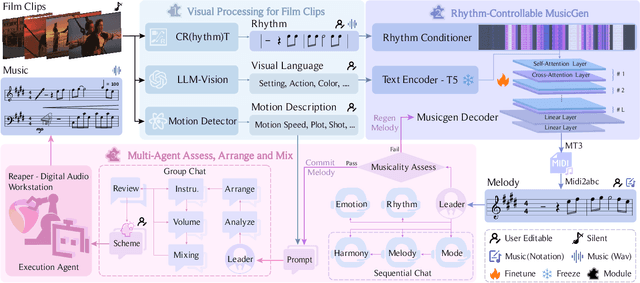
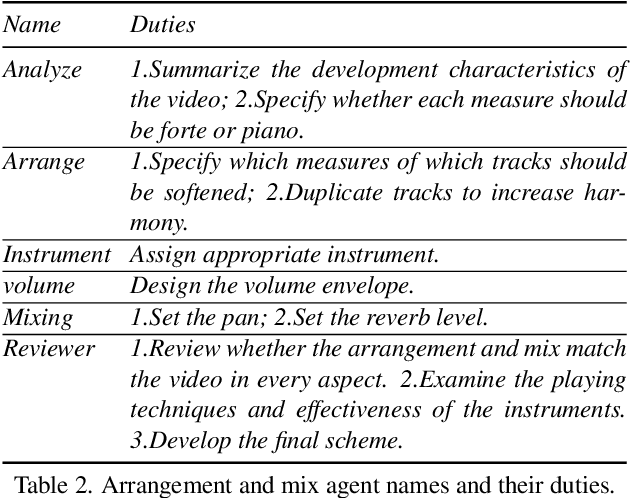
In this work, we implement music production for silent film clips using LLM-driven method. Given the strong professional demands of film music production, we propose the FilmComposer, simulating the actual workflows of professional musicians. FilmComposer is the first to combine large generative models with a multi-agent approach, leveraging the advantages of both waveform music and symbolic music generation. Additionally, FilmComposer is the first to focus on the three core elements of music production for film-audio quality, musicality, and musical development-and introduces various controls, such as rhythm, semantics, and visuals, to enhance these key aspects. Specifically, FilmComposer consists of the visual processing module, rhythm-controllable MusicGen, and multi-agent assessment, arrangement and mix. In addition, our framework can seamlessly integrate into the actual music production pipeline and allows user intervention in every step, providing strong interactivity and a high degree of creative freedom. Furthermore, we propose MusicPro-7k which includes 7,418 film clips, music, description, rhythm spots and main melody, considering the lack of a professional and high-quality film music dataset. Finally, both the standard metrics and the new specialized metrics we propose demonstrate that the music generated by our model achieves state-of-the-art performance in terms of quality, consistency with video, diversity, musicality, and musical development. Project page: https://apple-jun.github.io/FilmComposer.github.io/
StageDesigner: Artistic Stage Generation for Scenography via Theater Scripts
Mar 04, 2025In this work, we introduce StageDesigner, the first comprehensive framework for artistic stage generation using large language models combined with layout-controlled diffusion models. Given the professional requirements of stage scenography, StageDesigner simulates the workflows of seasoned artists to generate immersive 3D stage scenes. Specifically, our approach is divided into three primary modules: Script Analysis, which extracts thematic and spatial cues from input scripts; Foreground Generation, which constructs and arranges essential 3D objects; and Background Generation, which produces a harmonious background aligned with the narrative atmosphere and maintains spatial coherence by managing occlusions between foreground and background elements. Furthermore, we introduce the StagePro-V1 dataset, a dedicated dataset with 276 unique stage scenes spanning different historical styles and annotated with scripts, images, and detailed 3D layouts, specifically tailored for this task. Finally, evaluations using both standard and newly proposed metrics, along with extensive user studies, demonstrate the effectiveness of StageDesigner. Project can be found at: https://deadsmither5.github.io/2025/01/03/StageDesigner/
AniGaussian: Animatable Gaussian Avatar with Pose-guided Deformation
Feb 24, 2025

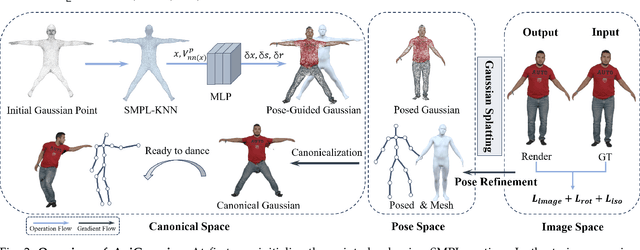

Recent advancements in Gaussian-based human body reconstruction have achieved notable success in creating animatable avatars. However, there are ongoing challenges to fully exploit the SMPL model's prior knowledge and enhance the visual fidelity of these models to achieve more refined avatar reconstructions. In this paper, we introduce AniGaussian which addresses the above issues with two insights. First, we propose an innovative pose guided deformation strategy that effectively constrains the dynamic Gaussian avatar with SMPL pose guidance, ensuring that the reconstructed model not only captures the detailed surface nuances but also maintains anatomical correctness across a wide range of motions. Second, we tackle the expressiveness limitations of Gaussian models in representing dynamic human bodies. We incorporate rigid-based priors from previous works to enhance the dynamic transform capabilities of the Gaussian model. Furthermore, we introduce a split-with-scale strategy that significantly improves geometry quality. The ablative study experiment demonstrates the effectiveness of our innovative model design. Through extensive comparisons with existing methods, AniGaussian demonstrates superior performance in both qualitative result and quantitative metrics.
ArtNVG: Content-Style Separated Artistic Neighboring-View Gaussian Stylization
Dec 25, 2024



As demand from the film and gaming industries for 3D scenes with target styles grows, the importance of advanced 3D stylization techniques increases. However, recent methods often struggle to maintain local consistency in color and texture throughout stylized scenes, which is essential for maintaining aesthetic coherence. To solve this problem, this paper introduces ArtNVG, an innovative 3D stylization framework that efficiently generates stylized 3D scenes by leveraging reference style images. Built on 3D Gaussian Splatting (3DGS), ArtNVG achieves rapid optimization and rendering while upholding high reconstruction quality. Our framework realizes high-quality 3D stylization by incorporating two pivotal techniques: Content-Style Separated Control and Attention-based Neighboring-View Alignment. Content-Style Separated Control uses the CSGO model and the Tile ControlNet to decouple the content and style control, reducing risks of information leakage. Concurrently, Attention-based Neighboring-View Alignment ensures consistency of local colors and textures across neighboring views, significantly improving visual quality. Extensive experiments validate that ArtNVG surpasses existing methods, delivering superior results in content preservation, style alignment, and local consistency.
Infinite Motion: Extended Motion Generation via Long Text Instructions
Jul 11, 2024



In the realm of motion generation, the creation of long-duration, high-quality motion sequences remains a significant challenge. This paper presents our groundbreaking work on "Infinite Motion", a novel approach that leverages long text to extended motion generation, effectively bridging the gap between short and long-duration motion synthesis. Our core insight is the strategic extension and reassembly of existing high-quality text-motion datasets, which has led to the creation of a novel benchmark dataset to facilitate the training of models for extended motion sequences. A key innovation of our model is its ability to accept arbitrary lengths of text as input, enabling the generation of motion sequences tailored to specific narratives or scenarios. Furthermore, we incorporate the timestamp design for text which allows precise editing of local segments within the generated sequences, offering unparalleled control and flexibility in motion synthesis. We further demonstrate the versatility and practical utility of "Infinite Motion" through three specific applications: natural language interactive editing, motion sequence editing within long sequences and splicing of independent motion sequences. Each application highlights the adaptability of our approach and broadens the spectrum of possibilities for research and development in motion generation. Through extensive experiments, we demonstrate the superior performance of our model in generating long sequence motions compared to existing methods.Project page: https://shuochengzhai.github.io/Infinite-motion.github.io/