 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHierarchical Fashion Design with Multi-stage Diffusion Models
Jan 20, 2024

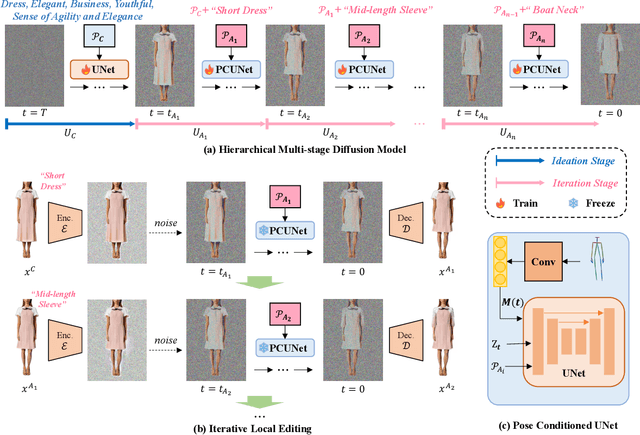

Cross-modal fashion synthesis and editing offer intelligent support to fashion designers by enabling the automatic generation and local modification of design drafts.While current diffusion models demonstrate commendable stability and controllability in image synthesis,they still face significant challenges in generating fashion design from abstract design elements and fine-grained editing.Abstract sensory expressions, \eg office, business, and party, form the high-level design concepts, while measurable aspects like sleeve length, collar type, and pant length are considered the low-level attributes of clothing.Controlling and editing fashion images using lengthy text descriptions poses a difficulty.In this paper, we propose HieraFashDiff,a novel fashion design method using the shared multi-stage diffusion model encompassing high-level design concepts and low-level clothing attributes in a hierarchical structure.Specifically, we categorized the input text into different levels and fed them in different time step to the diffusion model according to the criteria of professional clothing designers.HieraFashDiff allows designers to add low-level attributes after high-level prompts for interactive editing incrementally.In addition, we design a differentiable loss function in the sampling process with a mask to keep non-edit areas.Comprehensive experiments performed on our newly conducted Hierarchical fashion dataset,demonstrate that our proposed method outperforms other state-of-the-art competitors.