 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaussianMorphing: Mesh-Guided 3D Gaussians for Semantic-Aware Object Morphing
Oct 02, 2025We introduce GaussianMorphing, a novel framework for semantic-aware 3D shape and texture morphing from multi-view images. Previous approaches usually rely on point clouds or require pre-defined homeomorphic mappings for untextured data. Our method overcomes these limitations by leveraging mesh-guided 3D Gaussian Splatting (3DGS) for high-fidelity geometry and appearance modeling. The core of our framework is a unified deformation strategy that anchors 3DGaussians to reconstructed mesh patches, ensuring geometrically consistent transformations while preserving texture fidelity through topology-aware constraints. In parallel, our framework establishes unsupervised semantic correspondence by using the mesh topology as a geometric prior and maintains structural integrity via physically plausible point trajectories. This integrated approach preserves both local detail and global semantic coherence throughout the morphing process with out requiring labeled data. On our proposed TexMorph benchmark, GaussianMorphing substantially outperforms prior 2D/3D methods, reducing color consistency error ($\Delta E$) by 22.2% and EI by 26.2%. Project page: https://baiyunshu.github.io/GAUSSIANMORPHING.github.io/
FilmComposer: LLM-Driven Music Production for Silent Film Clips
Mar 11, 2025
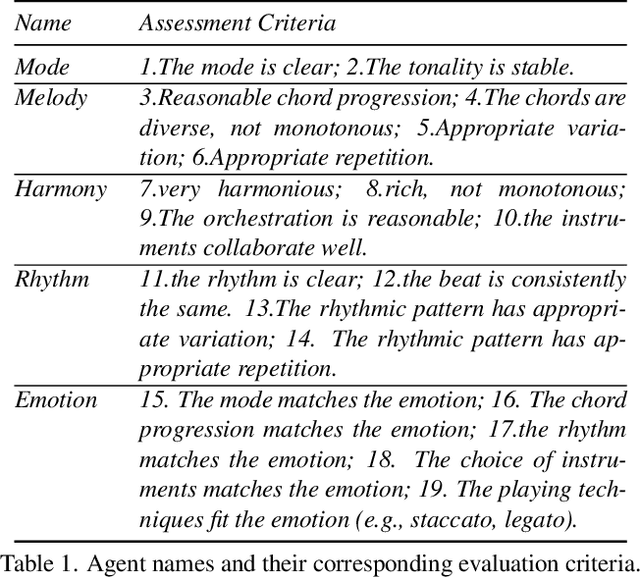
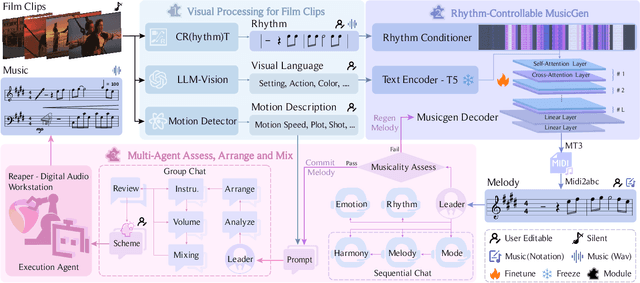
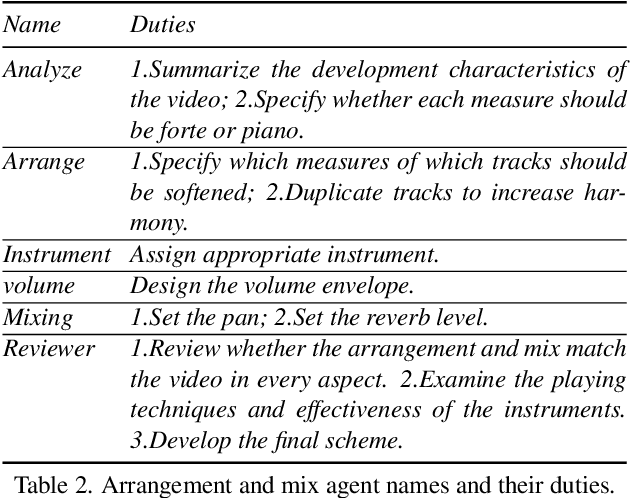
In this work, we implement music production for silent film clips using LLM-driven method. Given the strong professional demands of film music production, we propose the FilmComposer, simulating the actual workflows of professional musicians. FilmComposer is the first to combine large generative models with a multi-agent approach, leveraging the advantages of both waveform music and symbolic music generation. Additionally, FilmComposer is the first to focus on the three core elements of music production for film-audio quality, musicality, and musical development-and introduces various controls, such as rhythm, semantics, and visuals, to enhance these key aspects. Specifically, FilmComposer consists of the visual processing module, rhythm-controllable MusicGen, and multi-agent assessment, arrangement and mix. In addition, our framework can seamlessly integrate into the actual music production pipeline and allows user intervention in every step, providing strong interactivity and a high degree of creative freedom. Furthermore, we propose MusicPro-7k which includes 7,418 film clips, music, description, rhythm spots and main melody, considering the lack of a professional and high-quality film music dataset. Finally, both the standard metrics and the new specialized metrics we propose demonstrate that the music generated by our model achieves state-of-the-art performance in terms of quality, consistency with video, diversity, musicality, and musical development. Project page: https://apple-jun.github.io/FilmComposer.github.io/
AniGaussian: Animatable Gaussian Avatar with Pose-guided Deformation
Feb 24, 2025

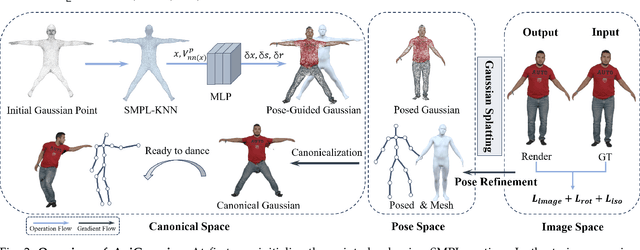

Recent advancements in Gaussian-based human body reconstruction have achieved notable success in creating animatable avatars. However, there are ongoing challenges to fully exploit the SMPL model's prior knowledge and enhance the visual fidelity of these models to achieve more refined avatar reconstructions. In this paper, we introduce AniGaussian which addresses the above issues with two insights. First, we propose an innovative pose guided deformation strategy that effectively constrains the dynamic Gaussian avatar with SMPL pose guidance, ensuring that the reconstructed model not only captures the detailed surface nuances but also maintains anatomical correctness across a wide range of motions. Second, we tackle the expressiveness limitations of Gaussian models in representing dynamic human bodies. We incorporate rigid-based priors from previous works to enhance the dynamic transform capabilities of the Gaussian model. Furthermore, we introduce a split-with-scale strategy that significantly improves geometry quality. The ablative study experiment demonstrates the effectiveness of our innovative model design. Through extensive comparisons with existing methods, AniGaussian demonstrates superior performance in both qualitative result and quantitative metrics.
Infinite Motion: Extended Motion Generation via Long Text Instructions
Jul 11, 2024



In the realm of motion generation, the creation of long-duration, high-quality motion sequences remains a significant challenge. This paper presents our groundbreaking work on "Infinite Motion", a novel approach that leverages long text to extended motion generation, effectively bridging the gap between short and long-duration motion synthesis. Our core insight is the strategic extension and reassembly of existing high-quality text-motion datasets, which has led to the creation of a novel benchmark dataset to facilitate the training of models for extended motion sequences. A key innovation of our model is its ability to accept arbitrary lengths of text as input, enabling the generation of motion sequences tailored to specific narratives or scenarios. Furthermore, we incorporate the timestamp design for text which allows precise editing of local segments within the generated sequences, offering unparalleled control and flexibility in motion synthesis. We further demonstrate the versatility and practical utility of "Infinite Motion" through three specific applications: natural language interactive editing, motion sequence editing within long sequences and splicing of independent motion sequences. Each application highlights the adaptability of our approach and broadens the spectrum of possibilities for research and development in motion generation. Through extensive experiments, we demonstrate the superior performance of our model in generating long sequence motions compared to existing methods.Project page: https://shuochengzhai.github.io/Infinite-motion.github.io/
PIG: Prompt Images Guidance for Night-Time Scene Parsing
Jun 15, 2024



Night-time scene parsing aims to extract pixel-level semantic information in night images, aiding downstream tasks in understanding scene object distribution. Due to limited labeled night image datasets, unsupervised domain adaptation (UDA) has become the predominant method for studying night scenes. UDA typically relies on paired day-night image pairs to guide adaptation, but this approach hampers dataset construction and restricts generalization across night scenes in different datasets. Moreover, UDA, focusing on network architecture and training strategies, faces difficulties in handling classes with few domain similarities. In this paper, we leverage Prompt Images Guidance (PIG) to enhance UDA with supplementary night knowledge. We propose a Night-Focused Network (NFNet) to learn night-specific features from both target domain images and prompt images. To generate high-quality pseudo-labels, we propose Pseudo-label Fusion via Domain Similarity Guidance (FDSG). Classes with fewer domain similarities are predicted by NFNet, which excels in parsing night features, while classes with more domain similarities are predicted by UDA, which has rich labeled semantics. Additionally, we propose two data augmentation strategies: the Prompt Mixture Strategy (PMS) and the Alternate Mask Strategy (AMS), aimed at mitigating the overfitting of the NFNet to a few prompt images. We conduct extensive experiments on four night-time datasets: NightCity, NightCity+, Dark Zurich, and ACDC. The results indicate that utilizing PIG can enhance the parsing accuracy of UDA.
GaussianBody: Clothed Human Reconstruction via 3d Gaussian Splatting
Jan 27, 2024In this work, we propose a novel clothed human reconstruction method called GaussianBody, based on 3D Gaussian Splatting. Compared with the costly neural radiance based models, 3D Gaussian Splatting has recently demonstrated great performance in terms of training time and rendering quality. However, applying the static 3D Gaussian Splatting model to the dynamic human reconstruction problem is non-trivial due to complicated non-rigid deformations and rich cloth details. To address these challenges, our method considers explicit pose-guided deformation to associate dynamic Gaussians across the canonical space and the observation space, introducing a physically-based prior with regularized transformations helps mitigate ambiguity between the two spaces. During the training process, we further propose a pose refinement strategy to update the pose regression for compensating the inaccurate initial estimation and a split-with-scale mechanism to enhance the density of regressed point clouds. The experiments validate that our method can achieve state-of-the-art photorealistic novel-view rendering results with high-quality details for dynamic clothed human bodies, along with explicit geometry reconstruction.
SonicVisionLM: Playing Sound with Vision Language Models
Jan 27, 2024



There has been a growing interest in the task of generating sound for silent videos, primarily because of its practicality in streamlining video post-production. However, existing methods for video-sound generation attempt to directly create sound from visual representations, which can be challenging due to the difficulty of aligning visual representations with audio representations. In this paper, we present SonicVisionLM, a novel framework aimed at generating a wide range of sound effects by leveraging vision language models. Instead of generating audio directly from video, we use the capabilities of powerful vision language models (VLMs). When provided with a silent video, our approach first identifies events within the video using a VLM to suggest possible sounds that match the video content. This shift in approach transforms the challenging task of aligning image and audio into more well-studied sub-problems of aligning image-to-text and text-to-audio through the popular diffusion models. To improve the quality of audio recommendations with LLMs, we have collected an extensive dataset that maps text descriptions to specific sound effects and developed temporally controlled audio adapters. Our approach surpasses current state-of-the-art methods for converting video to audio, resulting in enhanced synchronization with the visuals and improved alignment between audio and video components. Project page: https://yusiissy.github.io/SonicVisionLM.github.io/
Hierarchical Fashion Design with Multi-stage Diffusion Models
Jan 20, 2024

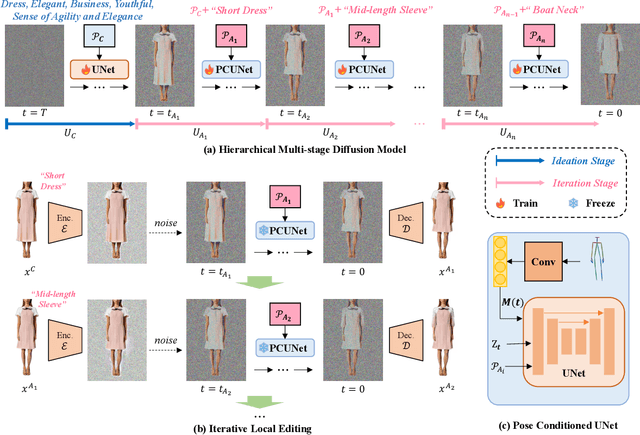

Cross-modal fashion synthesis and editing offer intelligent support to fashion designers by enabling the automatic generation and local modification of design drafts.While current diffusion models demonstrate commendable stability and controllability in image synthesis,they still face significant challenges in generating fashion design from abstract design elements and fine-grained editing.Abstract sensory expressions, \eg office, business, and party, form the high-level design concepts, while measurable aspects like sleeve length, collar type, and pant length are considered the low-level attributes of clothing.Controlling and editing fashion images using lengthy text descriptions poses a difficulty.In this paper, we propose HieraFashDiff,a novel fashion design method using the shared multi-stage diffusion model encompassing high-level design concepts and low-level clothing attributes in a hierarchical structure.Specifically, we categorized the input text into different levels and fed them in different time step to the diffusion model according to the criteria of professional clothing designers.HieraFashDiff allows designers to add low-level attributes after high-level prompts for interactive editing incrementally.In addition, we design a differentiable loss function in the sampling process with a mask to keep non-edit areas.Comprehensive experiments performed on our newly conducted Hierarchical fashion dataset,demonstrate that our proposed method outperforms other state-of-the-art competitors.
High-fidelity Generalized Emotional Talking Face Generation with Multi-modal Emotion Space Learning
May 04, 2023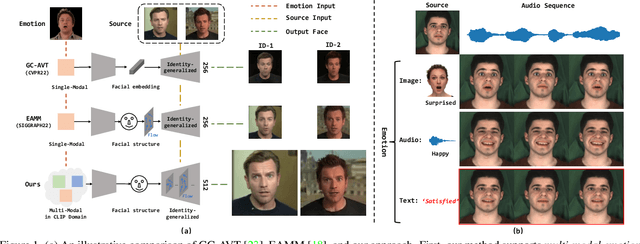
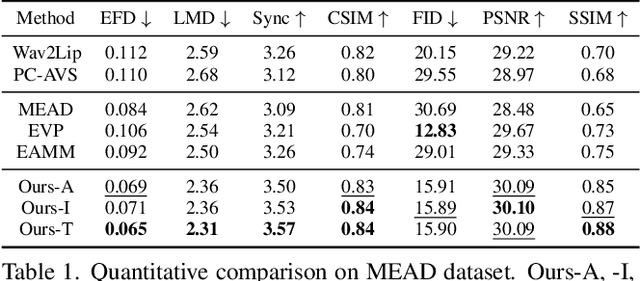
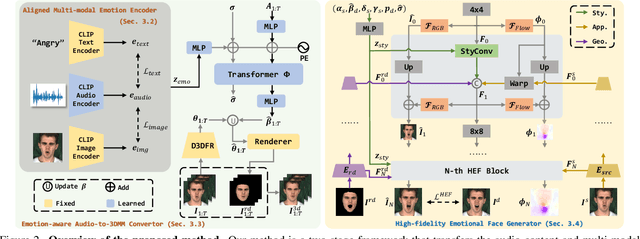
Recently, emotional talking face generation has received considerable attention. However, existing methods only adopt one-hot coding, image, or audio as emotion conditions, thus lacking flexible control in practical applications and failing to handle unseen emotion styles due to limited semantics. They either ignore the one-shot setting or the quality of generated faces. In this paper, we propose a more flexible and generalized framework. Specifically, we supplement the emotion style in text prompts and use an Aligned Multi-modal Emotion encoder to embed the text, image, and audio emotion modality into a unified space, which inherits rich semantic prior from CLIP. Consequently, effective multi-modal emotion space learning helps our method support arbitrary emotion modality during testing and could generalize to unseen emotion styles. Besides, an Emotion-aware Audio-to-3DMM Convertor is proposed to connect the emotion condition and the audio sequence to structural representation. A followed style-based High-fidelity Emotional Face generator is designed to generate arbitrary high-resolution realistic identities. Our texture generator hierarchically learns flow fields and animated faces in a residual manner. Extensive experiments demonstrate the flexibility and generalization of our method in emotion control and the effectiveness of high-quality face synthesis.
Joint Representation Learning for Text and 3D Point Cloud
Jan 18, 2023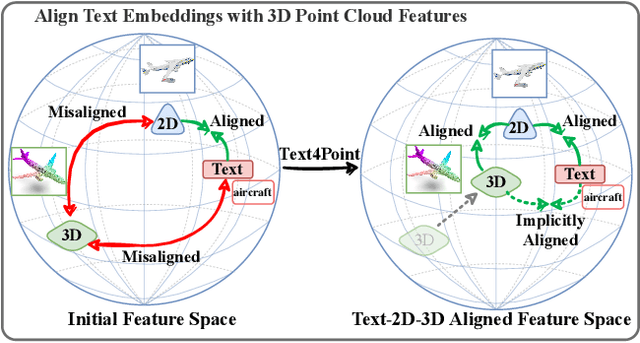
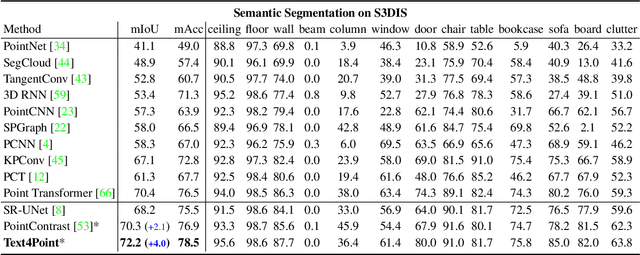
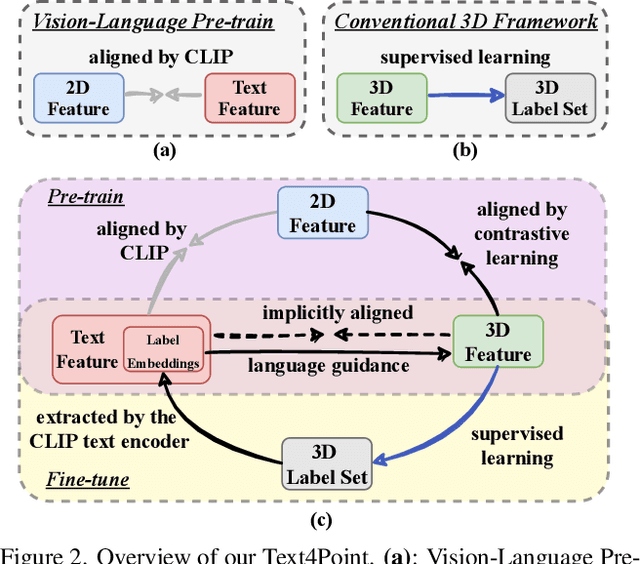
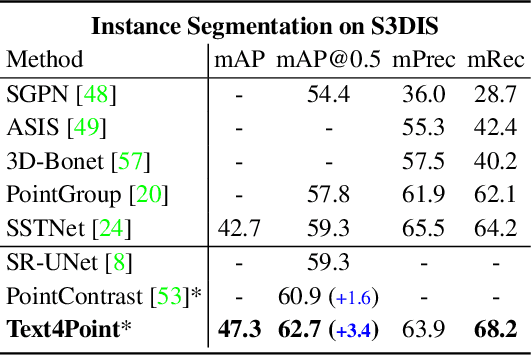
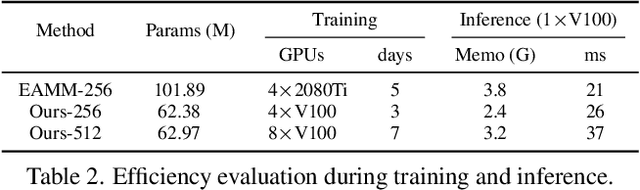
Recent advancements in vision-language pre-training (e.g. CLIP) have shown that vision models can benefit from language supervision. While many models using language modality have achieved great success on 2D vision tasks, the joint representation learning of 3D point cloud with text remains under-explored due to the difficulty of 3D-Text data pair acquisition and the irregularity of 3D data structure. In this paper, we propose a novel Text4Point framework to construct language-guided 3D point cloud models. The key idea is utilizing 2D images as a bridge to connect the point cloud and the language modalities. The proposed Text4Point follows the pre-training and fine-tuning paradigm. During the pre-training stage, we establish the correspondence of images and point clouds based on the readily available RGB-D data and use contrastive learning to align the image and point cloud representations. Together with the well-aligned image and text features achieved by CLIP, the point cloud features are implicitly aligned with the text embeddings. Further, we propose a Text Querying Module to integrate language information into 3D representation learning by querying text embeddings with point cloud features. For fine-tuning, the model learns task-specific 3D representations under informative language guidance from the label set without 2D images. Extensive experiments demonstrate that our model shows consistent improvement on various downstream tasks, such as point cloud semantic segmentation, instance segmentation, and object detection. The code will be available here: https://github.com/LeapLabTHU/Text4Point