 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Divide: Reconsidering Softmax and Linear Attention
Dec 09, 2024



Widely adopted in modern Vision Transformer designs, Softmax attention can effectively capture long-range visual information; however, it incurs excessive computational cost when dealing with high-resolution inputs. In contrast, linear attention naturally enjoys linear complexity and has great potential to scale up to higher-resolution images. Nonetheless, the unsatisfactory performance of linear attention greatly limits its practical application in various scenarios. In this paper, we take a step forward to close the gap between the linear and Softmax attention with novel theoretical analyses, which demystify the core factors behind the performance deviations. Specifically, we present two key perspectives to understand and alleviate the limitations of linear attention: the injective property and the local modeling ability. Firstly, we prove that linear attention is not injective, which is prone to assign identical attention weights to different query vectors, thus adding to severe semantic confusion since different queries correspond to the same outputs. Secondly, we confirm that effective local modeling is essential for the success of Softmax attention, in which linear attention falls short. The aforementioned two fundamental differences significantly contribute to the disparities between these two attention paradigms, which is demonstrated by our substantial empirical validation in the paper. In addition, more experiment results indicate that linear attention, as long as endowed with these two properties, can outperform Softmax attention across various tasks while maintaining lower computation complexity. Code is available at https://github.com/LeapLabTHU/InLine.
GSVA: Generalized Segmentation via Multimodal Large Language Models
Dec 15, 2023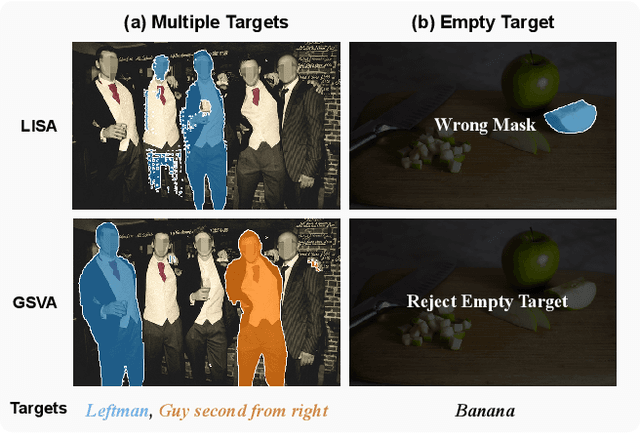
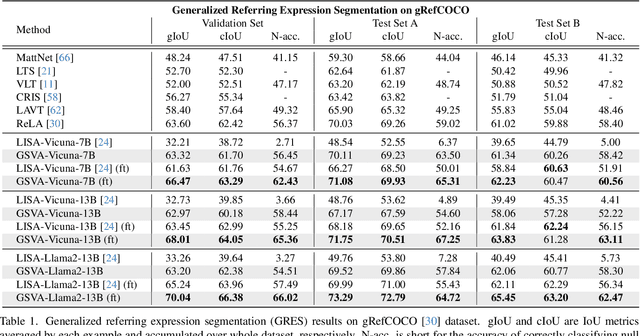
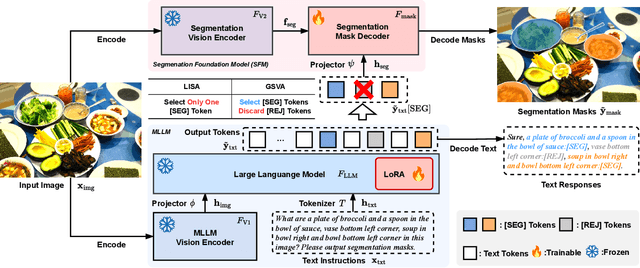
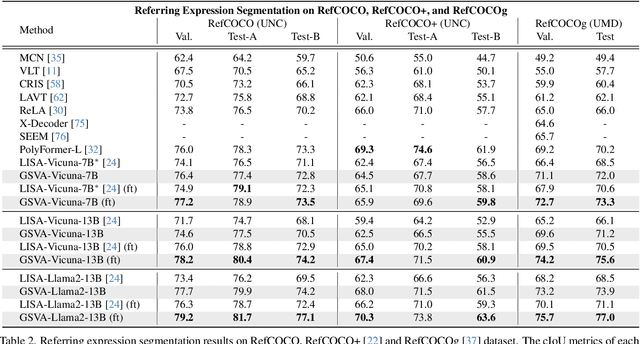
Generalized Referring Expression Segmentation (GRES) extends the scope of classic RES to referring to multiple objects in one expression or identifying the empty targets absent in the image. GRES poses challenges in modeling the complex spatial relationships of the instances in the image and identifying non-existing referents. Recently, Multimodal Large Language Models (MLLMs) have shown tremendous progress in these complicated vision-language tasks. Connecting Large Language Models (LLMs) and vision models, MLLMs are proficient in understanding contexts with visual inputs. Among them, LISA, as a representative, adopts a special [SEG] token to prompt a segmentation mask decoder, e.g., SAM, to enable MLLMs in the RES task. However, existing solutions to of GRES remain unsatisfactory since current segmentation MLLMs cannot properly handle the cases where users might reference multiple subjects in a singular prompt or provide descriptions incongruent with any image target. In this paper, we propose Generalized Segmentation Vision Assistant (GSVA) to address this gap. Specifically, GSVA reuses the [SEG] token to prompt the segmentation model towards supporting multiple mask references simultaneously and innovatively learns to generate a [REJ] token to reject the null targets explicitly. Experiments validate GSVA's efficacy in resolving the GRES issue, marking a notable enhancement and setting a new record on the GRES benchmark gRefCOCO dataset. GSVA also proves effective across various classic referring expression segmentation and comprehension tasks.
DAT++: Spatially Dynamic Vision Transformer with Deformable Attention
Sep 04, 2023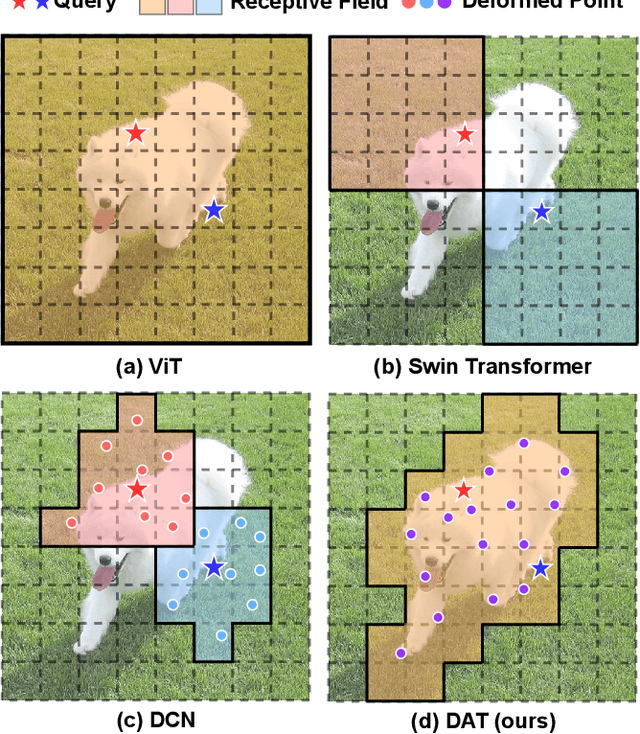
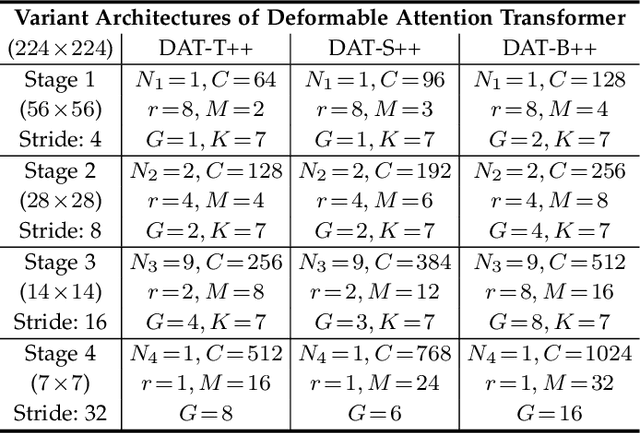
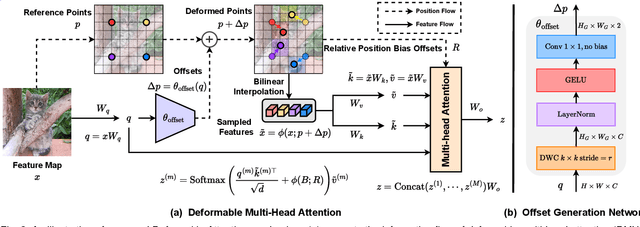
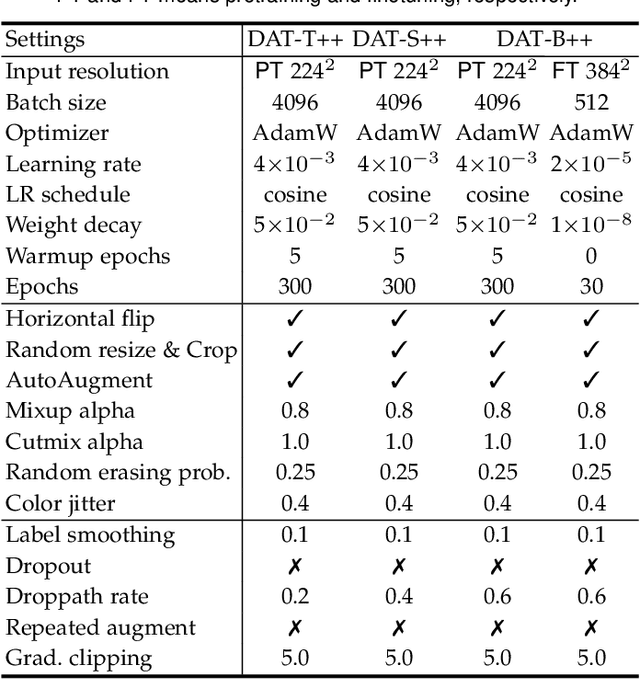
Transformers have shown superior performance on various vision tasks. Their large receptive field endows Transformer models with higher representation power than their CNN counterparts. Nevertheless, simply enlarging the receptive field also raises several concerns. On the one hand, using dense attention in ViT leads to excessive memory and computational cost, and features can be influenced by irrelevant parts that are beyond the region of interests. On the other hand, the handcrafted attention adopted in PVT or Swin Transformer is data agnostic and may limit the ability to model long-range relations. To solve this dilemma, we propose a novel deformable multi-head attention module, where the positions of key and value pairs in self-attention are adaptively allocated in a data-dependent way. This flexible scheme enables the proposed deformable attention to dynamically focus on relevant regions while maintains the representation power of global attention. On this basis, we present Deformable Attention Transformer (DAT), a general vision backbone efficient and effective for visual recognition. We further build an enhanced version DAT++. Extensive experiments show that our DAT++ achieves state-of-the-art results on various visual recognition benchmarks, with 85.9% ImageNet accuracy, 54.5 and 47.0 MS-COCO instance segmentation mAP, and 51.5 ADE20K semantic segmentation mIoU.
FLatten Transformer: Vision Transformer using Focused Linear Attention
Aug 01, 2023The quadratic computation complexity of self-attention has been a persistent challenge when applying Transformer models to vision tasks. Linear attention, on the other hand, offers a much more efficient alternative with its linear complexity by approximating the Softmax operation through carefully designed mapping functions. However, current linear attention approaches either suffer from significant performance degradation or introduce additional computation overhead from the mapping functions. In this paper, we propose a novel Focused Linear Attention module to achieve both high efficiency and expressiveness. Specifically, we first analyze the factors contributing to the performance degradation of linear attention from two perspectives: the focus ability and feature diversity. To overcome these limitations, we introduce a simple yet effective mapping function and an efficient rank restoration module to enhance the expressiveness of self-attention while maintaining low computation complexity. Extensive experiments show that our linear attention module is applicable to a variety of advanced vision Transformers, and achieves consistently improved performances on multiple benchmarks. Code is available at https://github.com/LeapLabTHU/FLatten-Transformer.
Dynamic Perceiver for Efficient Visual Recognition
Jun 20, 2023



Early exiting has become a promising approach to improving the inference efficiency of deep networks. By structuring models with multiple classifiers (exits), predictions for ``easy'' samples can be generated at earlier exits, negating the need for executing deeper layers. Current multi-exit networks typically implement linear classifiers at intermediate layers, compelling low-level features to encapsulate high-level semantics. This sub-optimal design invariably undermines the performance of later exits. In this paper, we propose Dynamic Perceiver (Dyn-Perceiver) to decouple the feature extraction procedure and the early classification task with a novel dual-branch architecture. A feature branch serves to extract image features, while a classification branch processes a latent code assigned for classification tasks. Bi-directional cross-attention layers are established to progressively fuse the information of both branches. Early exits are placed exclusively within the classification branch, thus eliminating the need for linear separability in low-level features. Dyn-Perceiver constitutes a versatile and adaptable framework that can be built upon various architectures. Experiments on image classification, action recognition, and object detection demonstrate that our method significantly improves the inference efficiency of different backbones, outperforming numerous competitive approaches across a broad range of computational budgets. Evaluation on both CPU and GPU platforms substantiate the superior practical efficiency of Dyn-Perceiver. Code is available at https://www.github.com/LeapLabTHU/Dynamic_Perceiver.
Slide-Transformer: Hierarchical Vision Transformer with Local Self-Attention
Apr 09, 2023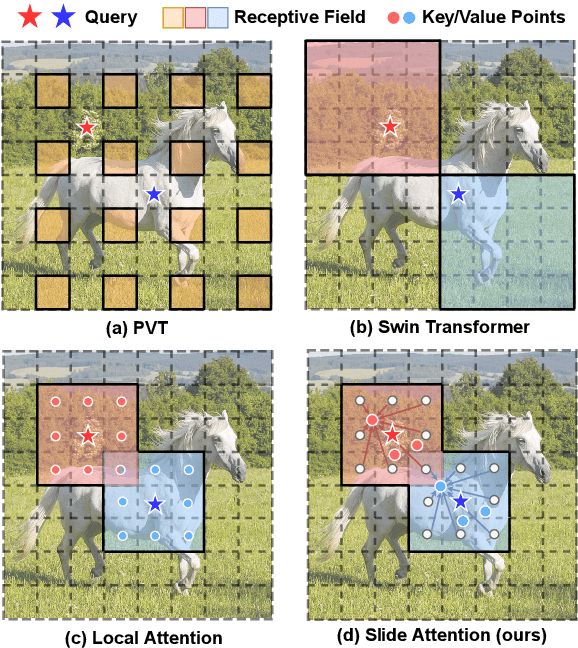
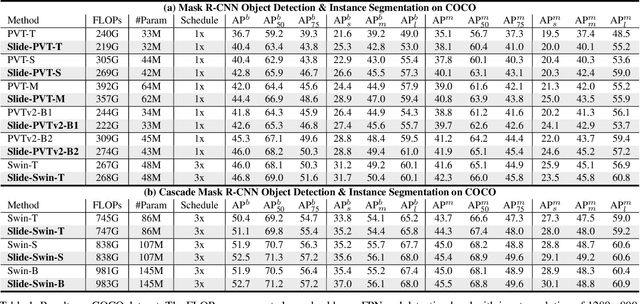
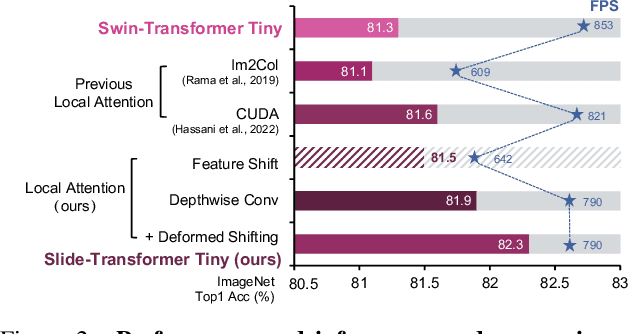
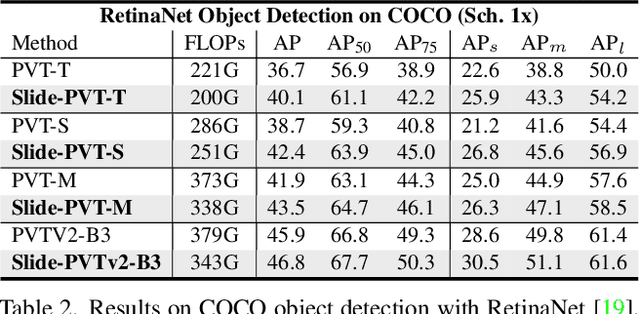
Self-attention mechanism has been a key factor in the recent progress of Vision Transformer (ViT), which enables adaptive feature extraction from global contexts. However, existing self-attention methods either adopt sparse global attention or window attention to reduce the computation complexity, which may compromise the local feature learning or subject to some handcrafted designs. In contrast, local attention, which restricts the receptive field of each query to its own neighboring pixels, enjoys the benefits of both convolution and self-attention, namely local inductive bias and dynamic feature selection. Nevertheless, current local attention modules either use inefficient Im2Col function or rely on specific CUDA kernels that are hard to generalize to devices without CUDA support. In this paper, we propose a novel local attention module, Slide Attention, which leverages common convolution operations to achieve high efficiency, flexibility and generalizability. Specifically, we first re-interpret the column-based Im2Col function from a new row-based perspective and use Depthwise Convolution as an efficient substitution. On this basis, we propose a deformed shifting module based on the re-parameterization technique, which further relaxes the fixed key/value positions to deformed features in the local region. In this way, our module realizes the local attention paradigm in both efficient and flexible manner. Extensive experiments show that our slide attention module is applicable to a variety of advanced Vision Transformer models and compatible with various hardware devices, and achieves consistently improved performances on comprehensive benchmarks. Code is available at https://github.com/LeapLabTHU/Slide-Transformer.
Joint Representation Learning for Text and 3D Point Cloud
Jan 18, 2023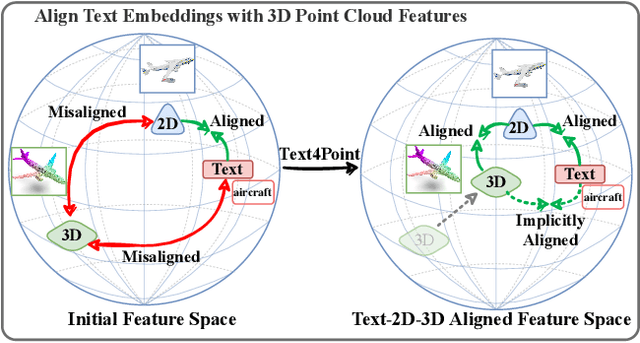
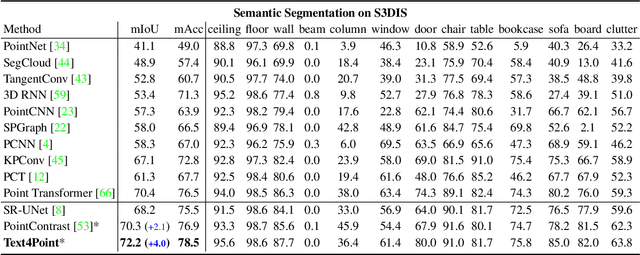
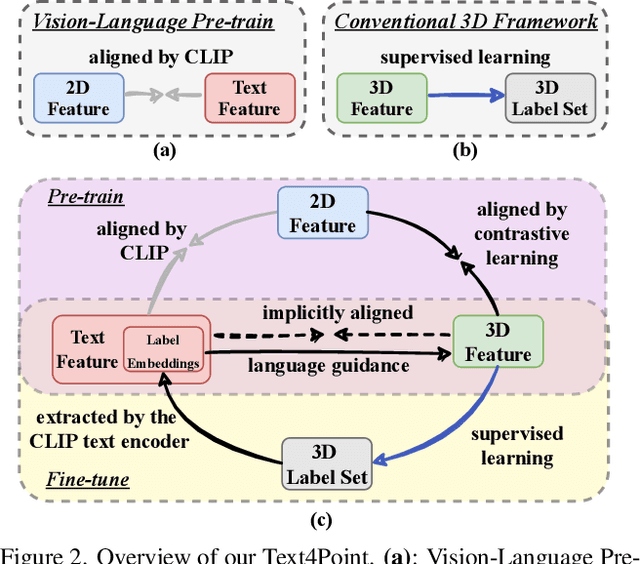
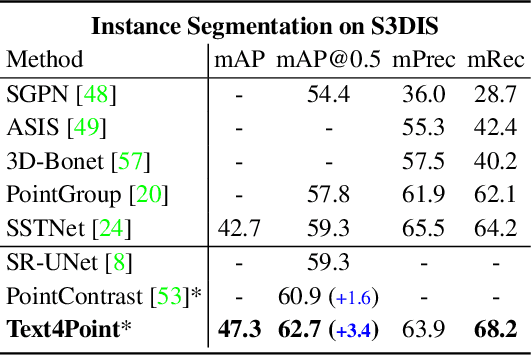
Recent advancements in vision-language pre-training (e.g. CLIP) have shown that vision models can benefit from language supervision. While many models using language modality have achieved great success on 2D vision tasks, the joint representation learning of 3D point cloud with text remains under-explored due to the difficulty of 3D-Text data pair acquisition and the irregularity of 3D data structure. In this paper, we propose a novel Text4Point framework to construct language-guided 3D point cloud models. The key idea is utilizing 2D images as a bridge to connect the point cloud and the language modalities. The proposed Text4Point follows the pre-training and fine-tuning paradigm. During the pre-training stage, we establish the correspondence of images and point clouds based on the readily available RGB-D data and use contrastive learning to align the image and point cloud representations. Together with the well-aligned image and text features achieved by CLIP, the point cloud features are implicitly aligned with the text embeddings. Further, we propose a Text Querying Module to integrate language information into 3D representation learning by querying text embeddings with point cloud features. For fine-tuning, the model learns task-specific 3D representations under informative language guidance from the label set without 2D images. Extensive experiments demonstrate that our model shows consistent improvement on various downstream tasks, such as point cloud semantic segmentation, instance segmentation, and object detection. The code will be available here: https://github.com/LeapLabTHU/Text4Point
Contrastive Language-Image Pre-Training with Knowledge Graphs
Oct 17, 2022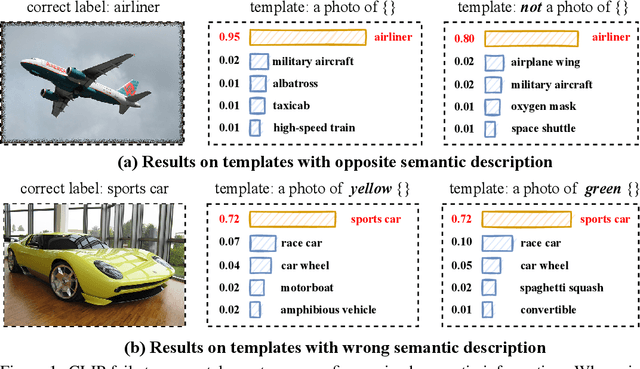
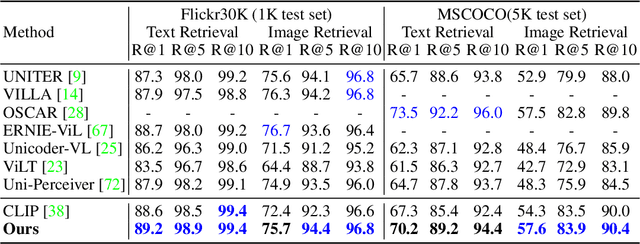
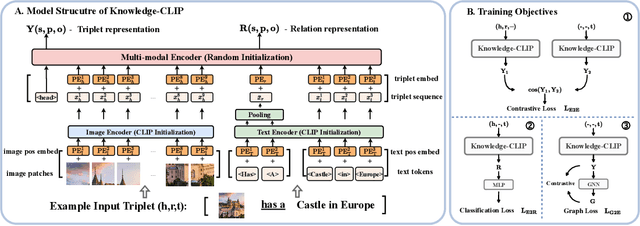
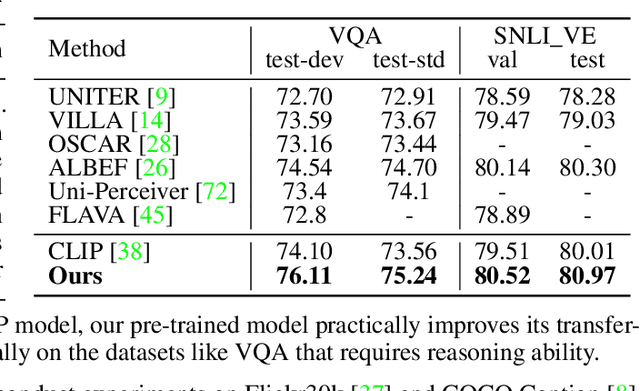
Recent years have witnessed the fast development of large-scale pre-training frameworks that can extract multi-modal representations in a unified form and achieve promising performances when transferred to downstream tasks. Nevertheless, existing approaches mainly focus on pre-training with simple image-text pairs, while neglecting the semantic connections between concepts from different modalities. In this paper, we propose a knowledge-based pre-training framework, dubbed Knowledge-CLIP, which injects semantic information into the widely used CLIP model. Through introducing knowledge-based objectives in the pre-training process and utilizing different types of knowledge graphs as training data, our model can semantically align the representations in vision and language with higher quality, and enhance the reasoning ability across scenarios and modalities. Extensive experiments on various vision-language downstream tasks demonstrate the effectiveness of Knowledge-CLIP compared with the original CLIP and competitive baselines.
ActiveNeRF: Learning where to See with Uncertainty Estimation
Sep 18, 2022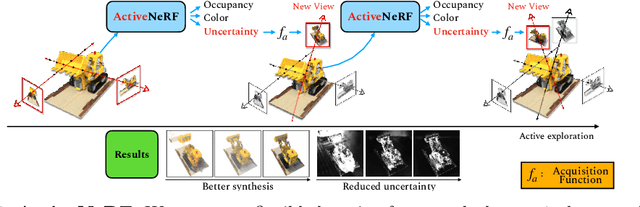
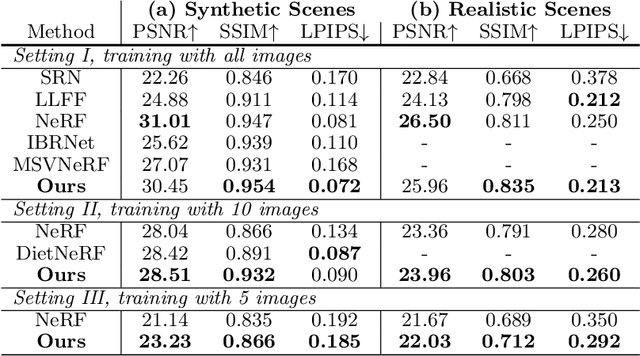

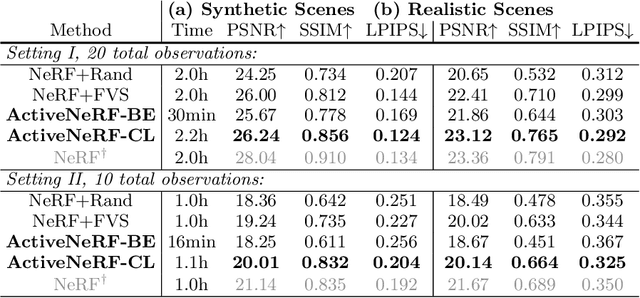
Recently, Neural Radiance Fields (NeRF) has shown promising performances on reconstructing 3D scenes and synthesizing novel views from a sparse set of 2D images. Albeit effective, the performance of NeRF is highly influenced by the quality of training samples. With limited posed images from the scene, NeRF fails to generalize well to novel views and may collapse to trivial solutions in unobserved regions. This makes NeRF impractical under resource-constrained scenarios. In this paper, we present a novel learning framework, ActiveNeRF, aiming to model a 3D scene with a constrained input budget. Specifically, we first incorporate uncertainty estimation into a NeRF model, which ensures robustness under few observations and provides an interpretation of how NeRF understands the scene. On this basis, we propose to supplement the existing training set with newly captured samples based on an active learning scheme. By evaluating the reduction of uncertainty given new inputs, we select the samples that bring the most information gain. In this way, the quality of novel view synthesis can be improved with minimal additional resources. Extensive experiments validate the performance of our model on both realistic and synthetic scenes, especially with scarcer training data. Code will be released at \url{https://github.com/LeapLabTHU/ActiveNeRF}.
Vision Transformer with Deformable Attention
Jan 03, 2022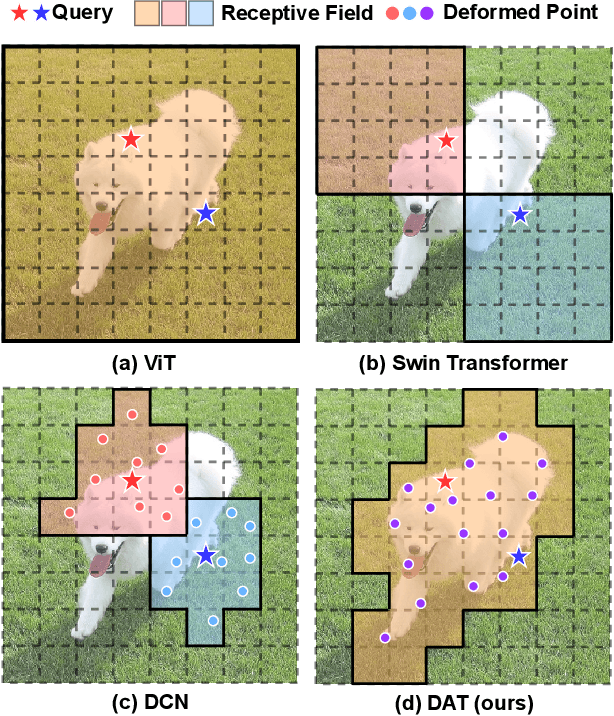



Transformers have recently shown superior performances on various vision tasks. The large, sometimes even global, receptive field endows Transformer models with higher representation power over their CNN counterparts. Nevertheless, simply enlarging receptive field also gives rise to several concerns. On the one hand, using dense attention e.g., in ViT, leads to excessive memory and computational cost, and features can be influenced by irrelevant parts which are beyond the region of interests. On the other hand, the sparse attention adopted in PVT or Swin Transformer is data agnostic and may limit the ability to model long range relations. To mitigate these issues, we propose a novel deformable self-attention module, where the positions of key and value pairs in self-attention are selected in a data-dependent way. This flexible scheme enables the self-attention module to focus on relevant regions and capture more informative features. On this basis, we present Deformable Attention Transformer, a general backbone model with deformable attention for both image classification and dense prediction tasks. Extensive experiments show that our models achieve consistently improved results on comprehensive benchmarks. Code is available at https://github.com/LeapLabTHU/DAT.