 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhyPrompt: RL-based Prompt Refinement for Physically Plausible Text-to-Video Generation
Mar 03, 2026State-of-the-art text-to-video (T2V) generators frequently violate physical laws despite high visual quality. We show this stems from insufficient physical constraints in prompts rather than model limitations: manually adding physics details reliably produces physically plausible videos, but requires expertise and does not scale. We present PhyPrompt, a two-stage reinforcement learning framework that automatically refines prompts for physically realistic generation. First, we fine-tune a large language model on a physics-focused Chain-of-Thought dataset to integrate principles like object motion and force interactions while preserving user intent. Second, we apply Group Relative Policy Optimization with a dynamic reward curriculum that initially prioritizes semantic fidelity, then progressively shifts toward physical commonsense. This curriculum achieves synergistic optimization: PhyPrompt-7B reaches 40.8\% joint success on VideoPhy2 (8.6pp gain), improving physical commonsense by 11pp (55.8\% to 66.8\%) while simultaneously increasing semantic adherence by 4.4pp (43.4\% to 47.8\%). Remarkably, our curriculum exceeds single-objective training on both metrics, demonstrating compositional prompt discovery beyond conventional multi-objective trade-offs. PhyPrompt outperforms GPT-4o (+3.8\% joint) and DeepSeek-V3 (+2.2\%, 100$\times$ larger) using only 7B parameters. The approach transfers zero-shot across diverse T2V architectures (Lavie, VideoCrafter2, CogVideoX-5B) with up to 16.8\% improvement, establishing that domain-specialized reinforcement learning with compositional curricula surpasses general-purpose scaling for physics-aware generation.
Towards Sparse Video Understanding and Reasoning
Feb 14, 2026We present \revise (\underline{Re}asoning with \underline{Vi}deo \underline{S}parsity), a multi-round agent for video question answering (VQA). Instead of uniformly sampling frames, \revise selects a small set of informative frames, maintains a summary-as-state across rounds, and stops early when confident. It supports proprietary vision-language models (VLMs) in a ``plug-and-play'' setting and enables reinforcement fine-tuning for open-source models. For fine-tuning, we introduce EAGER (Evidence-Adjusted Gain for Efficient Reasoning), an annotation-free reward with three terms: (1) Confidence gain: after new frames are added, we reward the increase in the log-odds gap between the correct option and the strongest alternative; (2) Summary sufficiency: at answer time we re-ask using only the last committed summary and reward success; (3) Correct-and-early stop: answering correctly within a small turn budget is rewarded. Across multiple VQA benchmarks, \revise improves accuracy while reducing frames, rounds, and prompt tokens, demonstrating practical sparse video reasoning.
Step by Step Network
Nov 18, 2025Scaling up network depth is a fundamental pursuit in neural architecture design, as theory suggests that deeper models offer exponentially greater capability. Benefiting from the residual connections, modern neural networks can scale up to more than one hundred layers and enjoy wide success. However, as networks continue to deepen, current architectures often struggle to realize their theoretical capacity improvements, calling for more advanced designs to further unleash the potential of deeper networks. In this paper, we identify two key barriers that obstruct residual models from scaling deeper: shortcut degradation and limited width. Shortcut degradation hinders deep-layer learning, while the inherent depth-width trade-off imposes limited width. To mitigate these issues, we propose a generalized residual architecture dubbed Step by Step Network (StepsNet) to bridge the gap between theoretical potential and practical performance of deep models. Specifically, we separate features along the channel dimension and let the model learn progressively via stacking blocks with increasing width. The resulting method mitigates the two identified problems and serves as a versatile macro design applicable to various models. Extensive experiments show that our method consistently outperforms residual models across diverse tasks, including image classification, object detection, semantic segmentation, and language modeling. These results position StepsNet as a superior generalization of the widely adopted residual architecture.
Emulating Human-like Adaptive Vision for Efficient and Flexible Machine Visual Perception
Sep 18, 2025Human vision is highly adaptive, efficiently sampling intricate environments by sequentially fixating on task-relevant regions. In contrast, prevailing machine vision models passively process entire scenes at once, resulting in excessive resource demands scaling with spatial-temporal input resolution and model size, yielding critical limitations impeding both future advancements and real-world application. Here we introduce AdaptiveNN, a general framework aiming to drive a paradigm shift from 'passive' to 'active, adaptive' vision models. AdaptiveNN formulates visual perception as a coarse-to-fine sequential decision-making process, progressively identifying and attending to regions pertinent to the task, incrementally combining information across fixations, and actively concluding observation when sufficient. We establish a theory integrating representation learning with self-rewarding reinforcement learning, enabling end-to-end training of the non-differentiable AdaptiveNN without additional supervision on fixation locations. We assess AdaptiveNN on 17 benchmarks spanning 9 tasks, including large-scale visual recognition, fine-grained discrimination, visual search, processing images from real driving and medical scenarios, language-driven embodied AI, and side-by-side comparisons with humans. AdaptiveNN achieves up to 28x inference cost reduction without sacrificing accuracy, flexibly adapts to varying task demands and resource budgets without retraining, and provides enhanced interpretability via its fixation patterns, demonstrating a promising avenue toward efficient, flexible, and interpretable computer vision. Furthermore, AdaptiveNN exhibits closely human-like perceptual behaviors in many cases, revealing its potential as a valuable tool for investigating visual cognition. Code is available at https://github.com/LeapLabTHU/AdaptiveNN.
Bridging the Divide: Reconsidering Softmax and Linear Attention
Dec 09, 2024



Widely adopted in modern Vision Transformer designs, Softmax attention can effectively capture long-range visual information; however, it incurs excessive computational cost when dealing with high-resolution inputs. In contrast, linear attention naturally enjoys linear complexity and has great potential to scale up to higher-resolution images. Nonetheless, the unsatisfactory performance of linear attention greatly limits its practical application in various scenarios. In this paper, we take a step forward to close the gap between the linear and Softmax attention with novel theoretical analyses, which demystify the core factors behind the performance deviations. Specifically, we present two key perspectives to understand and alleviate the limitations of linear attention: the injective property and the local modeling ability. Firstly, we prove that linear attention is not injective, which is prone to assign identical attention weights to different query vectors, thus adding to severe semantic confusion since different queries correspond to the same outputs. Secondly, we confirm that effective local modeling is essential for the success of Softmax attention, in which linear attention falls short. The aforementioned two fundamental differences significantly contribute to the disparities between these two attention paradigms, which is demonstrated by our substantial empirical validation in the paper. In addition, more experiment results indicate that linear attention, as long as endowed with these two properties, can outperform Softmax attention across various tasks while maintaining lower computation complexity. Code is available at https://github.com/LeapLabTHU/InLine.
Training an Open-Vocabulary Monocular 3D Object Detection Model without 3D Data
Nov 23, 2024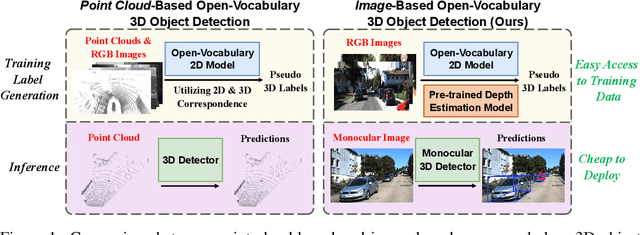
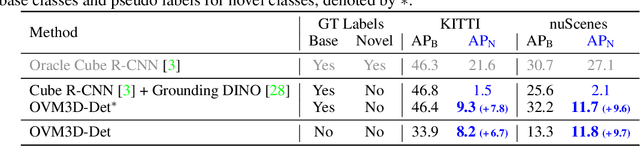
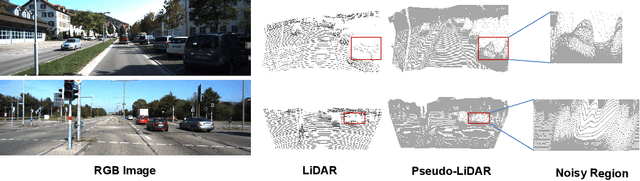
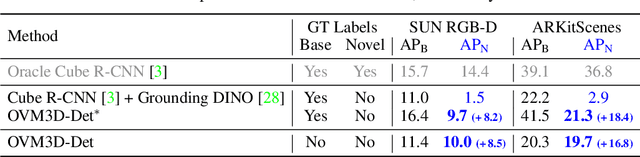
Open-vocabulary 3D object detection has recently attracted considerable attention due to its broad applications in autonomous driving and robotics, which aims to effectively recognize novel classes in previously unseen domains. However, existing point cloud-based open-vocabulary 3D detection models are limited by their high deployment costs. In this work, we propose a novel open-vocabulary monocular 3D object detection framework, dubbed OVM3D-Det, which trains detectors using only RGB images, making it both cost-effective and scalable to publicly available data. Unlike traditional methods, OVM3D-Det does not require high-precision LiDAR or 3D sensor data for either input or generating 3D bounding boxes. Instead, it employs open-vocabulary 2D models and pseudo-LiDAR to automatically label 3D objects in RGB images, fostering the learning of open-vocabulary monocular 3D detectors. However, training 3D models with labels directly derived from pseudo-LiDAR is inadequate due to imprecise boxes estimated from noisy point clouds and severely occluded objects. To address these issues, we introduce two innovative designs: adaptive pseudo-LiDAR erosion and bounding box refinement with prior knowledge from large language models. These techniques effectively calibrate the 3D labels and enable RGB-only training for 3D detectors. Extensive experiments demonstrate the superiority of OVM3D-Det over baselines in both indoor and outdoor scenarios. The code will be released.
Efficient Diffusion Transformer with Step-wise Dynamic Attention Mediators
Aug 11, 2024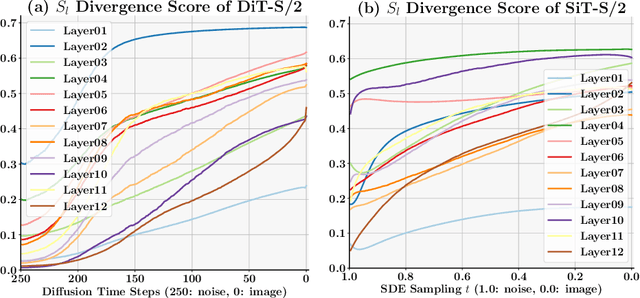
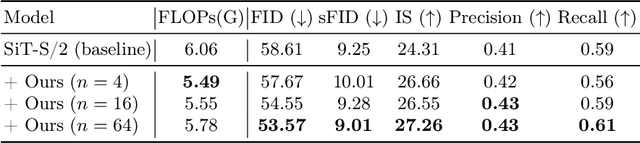
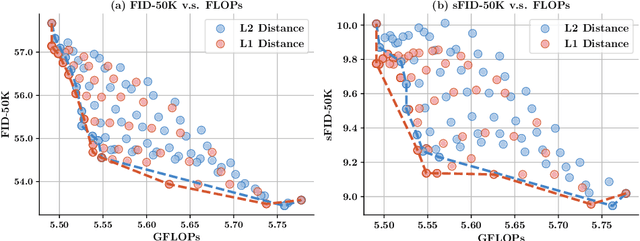
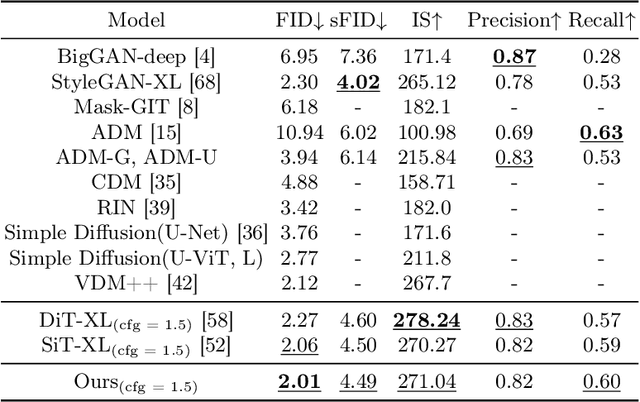
This paper identifies significant redundancy in the query-key interactions within self-attention mechanisms of diffusion transformer models, particularly during the early stages of denoising diffusion steps. In response to this observation, we present a novel diffusion transformer framework incorporating an additional set of mediator tokens to engage with queries and keys separately. By modulating the number of mediator tokens during the denoising generation phases, our model initiates the denoising process with a precise, non-ambiguous stage and gradually transitions to a phase enriched with detail. Concurrently, integrating mediator tokens simplifies the attention module's complexity to a linear scale, enhancing the efficiency of global attention processes. Additionally, we propose a time-step dynamic mediator token adjustment mechanism that further decreases the required computational FLOPs for generation, simultaneously facilitating the generation of high-quality images within the constraints of varied inference budgets. Extensive experiments demonstrate that the proposed method can improve the generated image quality while also reducing the inference cost of diffusion transformers. When integrated with the recent work SiT, our method achieves a state-of-the-art FID score of 2.01. The source code is available at https://github.com/LeapLabTHU/Attention-Mediators.
Demystify Mamba in Vision: A Linear Attention Perspective
May 26, 2024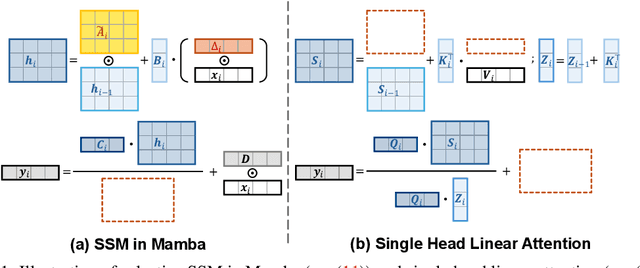
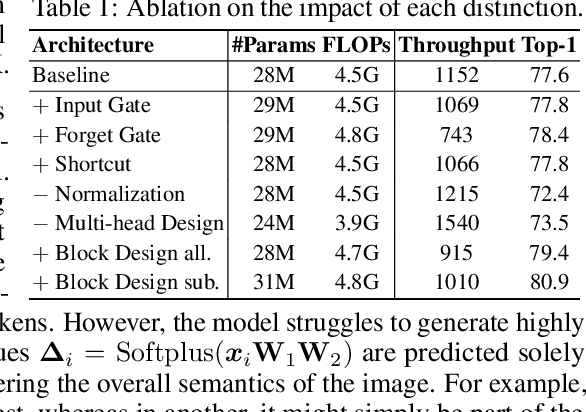
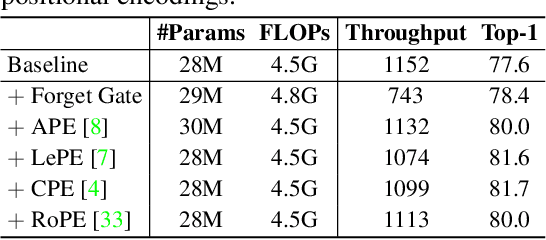
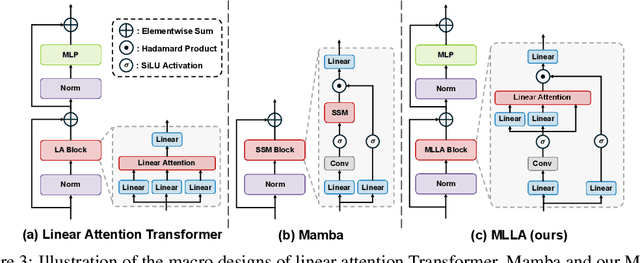
Mamba is an effective state space model with linear computation complexity. It has recently shown impressive efficiency in dealing with high-resolution inputs across various vision tasks. In this paper, we reveal that the powerful Mamba model shares surprising similarities with linear attention Transformer, which typically underperform conventional Transformer in practice. By exploring the similarities and disparities between the effective Mamba and subpar linear attention Transformer, we provide comprehensive analyses to demystify the key factors behind Mamba's success. Specifically, we reformulate the selective state space model and linear attention within a unified formulation, rephrasing Mamba as a variant of linear attention Transformer with six major distinctions: input gate, forget gate, shortcut, no attention normalization, single-head, and modified block design. For each design, we meticulously analyze its pros and cons, and empirically evaluate its impact on model performance in vision tasks. Interestingly, the results highlight the forget gate and block design as the core contributors to Mamba's success, while the other four designs are less crucial. Based on these findings, we propose a Mamba-Like Linear Attention (MLLA) model by incorporating the merits of these two key designs into linear attention. The resulting model outperforms various vision Mamba models in both image classification and high-resolution dense prediction tasks, while enjoying parallelizable computation and fast inference speed. Code is available at https://github.com/LeapLabTHU/MLLA.
Agent Attention: On the Integration of Softmax and Linear Attention
Dec 22, 2023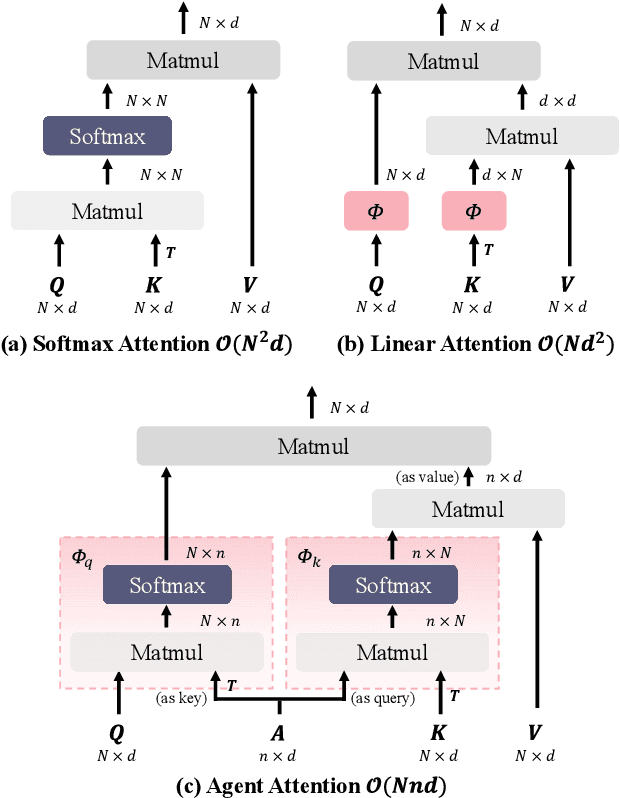
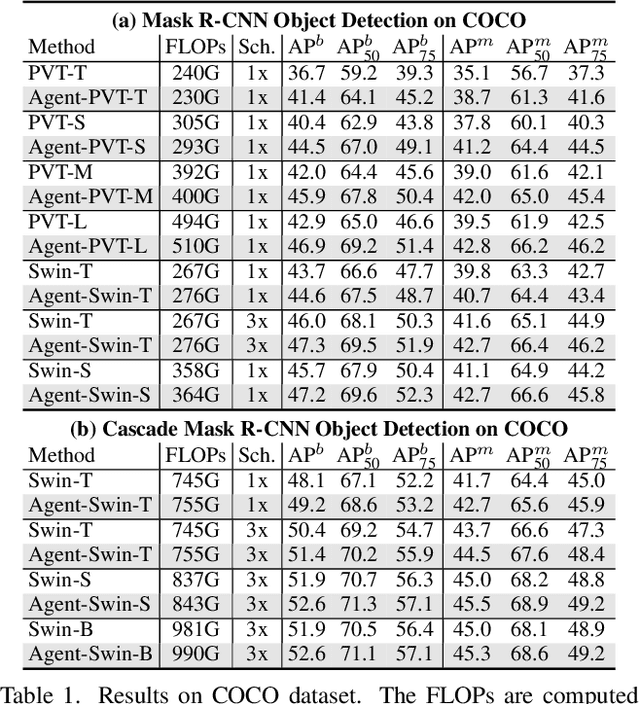
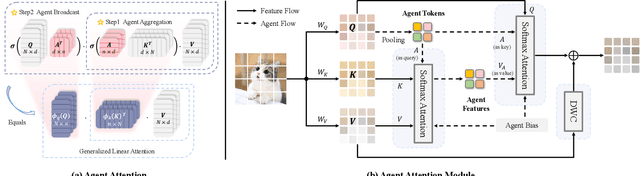
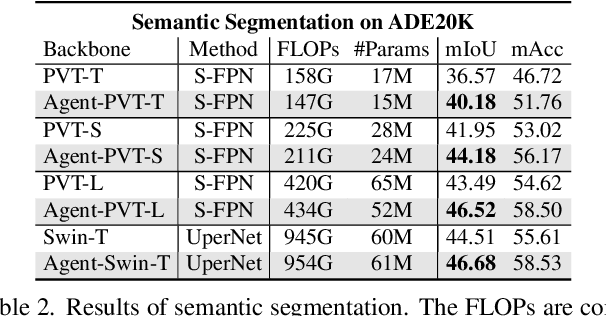
The attention module is the key component in Transformers. While the global attention mechanism offers high expressiveness, its excessive computational cost restricts its applicability in various scenarios. In this paper, we propose a novel attention paradigm, Agent Attention, to strike a favorable balance between computational efficiency and representation power. Specifically, the Agent Attention, denoted as a quadruple $(Q, A, K, V)$, introduces an additional set of agent tokens $A$ into the conventional attention module. The agent tokens first act as the agent for the query tokens $Q$ to aggregate information from $K$ and $V$, and then broadcast the information back to $Q$. Given the number of agent tokens can be designed to be much smaller than the number of query tokens, the agent attention is significantly more efficient than the widely adopted Softmax attention, while preserving global context modelling capability. Interestingly, we show that the proposed agent attention is equivalent to a generalized form of linear attention. Therefore, agent attention seamlessly integrates the powerful Softmax attention and the highly efficient linear attention. Extensive experiments demonstrate the effectiveness of agent attention with various vision Transformers and across diverse vision tasks, including image classification, object detection, semantic segmentation and image generation. Notably, agent attention has shown remarkable performance in high-resolution scenarios, owning to its linear attention nature. For instance, when applied to Stable Diffusion, our agent attention accelerates generation and substantially enhances image generation quality without any additional training. Code is available at https://github.com/LeapLabTHU/Agent-Attention.
GSVA: Generalized Segmentation via Multimodal Large Language Models
Dec 15, 2023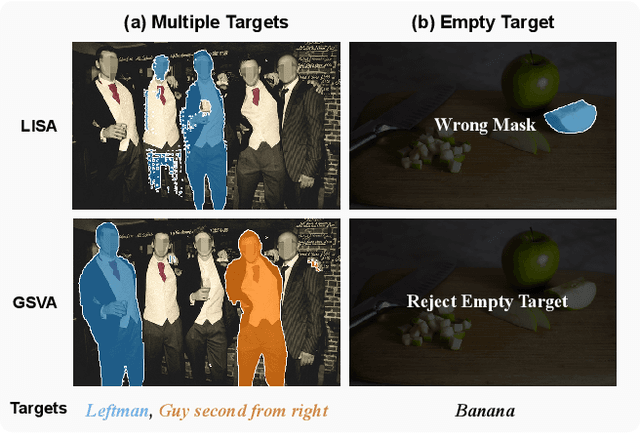
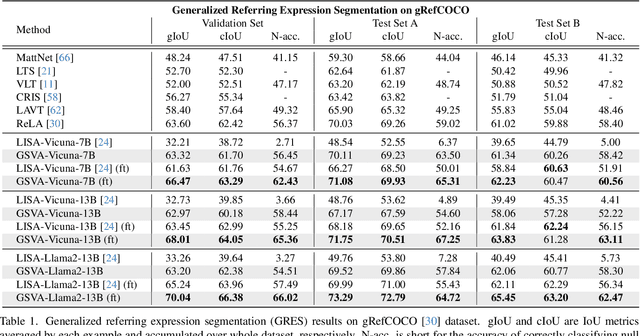
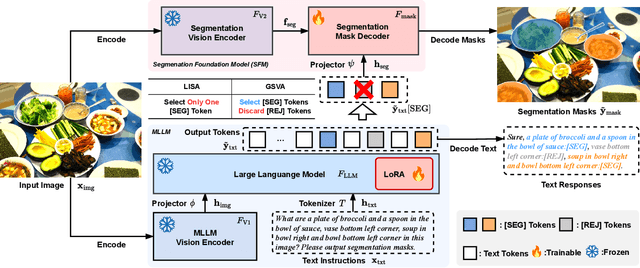
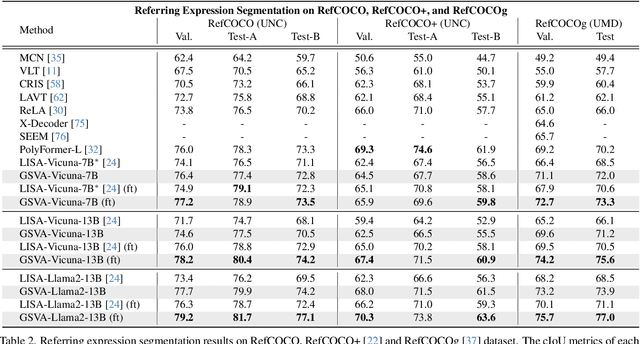
Generalized Referring Expression Segmentation (GRES) extends the scope of classic RES to referring to multiple objects in one expression or identifying the empty targets absent in the image. GRES poses challenges in modeling the complex spatial relationships of the instances in the image and identifying non-existing referents. Recently, Multimodal Large Language Models (MLLMs) have shown tremendous progress in these complicated vision-language tasks. Connecting Large Language Models (LLMs) and vision models, MLLMs are proficient in understanding contexts with visual inputs. Among them, LISA, as a representative, adopts a special [SEG] token to prompt a segmentation mask decoder, e.g., SAM, to enable MLLMs in the RES task. However, existing solutions to of GRES remain unsatisfactory since current segmentation MLLMs cannot properly handle the cases where users might reference multiple subjects in a singular prompt or provide descriptions incongruent with any image target. In this paper, we propose Generalized Segmentation Vision Assistant (GSVA) to address this gap. Specifically, GSVA reuses the [SEG] token to prompt the segmentation model towards supporting multiple mask references simultaneously and innovatively learns to generate a [REJ] token to reject the null targets explicitly. Experiments validate GSVA's efficacy in resolving the GRES issue, marking a notable enhancement and setting a new record on the GRES benchmark gRefCOCO dataset. GSVA also proves effective across various classic referring expression segmentation and comprehension tasks.