 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS3-CoT: Self-Sampled Succinct Reasoning Enables Efficient Chain-of-Thought LLMs
Feb 02, 2026Large language models (LLMs) equipped with chain-of-thought (CoT) achieve strong performance and offer a window into LLM behavior. However, recent evidence suggests that improvements in CoT capabilities often come with redundant reasoning processes, motivating a key question: Can LLMs acquire a fast-thinking mode analogous to human System 1 reasoning? To explore this, our study presents a self-sampling framework based on activation steering for efficient CoT learning. Our method can induce style-aligned and variable-length reasoning traces from target LLMs themselves without any teacher guidance, thereby alleviating a central bottleneck of SFT-based methods-the scarcity of high-quality supervision data. Using filtered data by gold answers, we perform SFT for efficient CoT learning with (i) a human-like dual-cognitive system, and (ii) a progressive compression curriculum. Furthermore, we explore a self-evolution regime in which SFT is driven solely by prediction-consistent data of variable-length variants, eliminating the need for gold answers. Extensive experiments on math benchmarks, together with cross-domain generalization tests in medicine, show that our method yields stable improvements for both general and R1-style LLMs. Our data and model checkpoints can be found at https://github.com/DYR1/S3-CoT.
From Latent Signals to Reflection Behavior: Tracing Meta-Cognitive Activation Trajectory in R1-Style LLMs
Feb 02, 2026R1-style LLMs have attracted growing attention for their capacity for self-reflection, yet the internal mechanisms underlying such behavior remain unclear. To bridge this gap, we anchor on the onset of reflection behavior and trace its layer-wise activation trajectory. Using the logit lens to read out token-level semantics, we uncover a structured progression: (i) Latent-control layers, where an approximate linear direction encodes the semantics of thinking budget; (ii) Semantic-pivot layers, where discourse-level cues, including turning-point and summarization cues, surface and dominate the probability mass; and (iii) Behavior-overt layers, where the likelihood of reflection-behavior tokens begins to rise until they become highly likely to be sampled. Moreover, our targeted interventions uncover a causal chain across these stages: prompt-level semantics modulate the projection of activations along latent-control directions, thereby inducing competition between turning-point and summarization cues in semantic-pivot layers, which in turn regulates the sampling likelihood of reflection-behavior tokens in behavior-overt layers. Collectively, our findings suggest a human-like meta-cognitive process-progressing from latent monitoring, to discourse-level regulation, and to finally overt self-reflection. Our analysis code can be found at https://github.com/DYR1/S3-CoT.
Constrained Gaussian Process Motion Planning via Stein Variational Newton Inference
Apr 07, 2025Gaussian Process Motion Planning (GPMP) is a widely used framework for generating smooth trajectories within a limited compute time--an essential requirement in many robotic applications. However, traditional GPMP approaches often struggle with enforcing hard nonlinear constraints and rely on Maximum a Posteriori (MAP) solutions that disregard the full Bayesian posterior. This limits planning diversity and ultimately hampers decision-making. Recent efforts to integrate Stein Variational Gradient Descent (SVGD) into motion planning have shown promise in handling complex constraints. Nonetheless, these methods still face persistent challenges, such as difficulties in strictly enforcing constraints and inefficiencies when the probabilistic inference problem is poorly conditioned. To address these issues, we propose a novel constrained Stein Variational Gaussian Process Motion Planning (cSGPMP) framework, incorporating a GPMP prior specifically designed for trajectory optimization under hard constraints. Our approach improves the efficiency of particle-based inference while explicitly handling nonlinear constraints. This advancement significantly broadens the applicability of GPMP to motion planning scenarios demanding robust Bayesian inference, strict constraint adherence, and computational efficiency within a limited time. We validate our method on standard benchmarks, achieving an average success rate of 98.57% across 350 planning tasks, significantly outperforming competitive baselines. This demonstrates the ability of our method to discover and use diverse trajectory modes, enhancing flexibility and adaptability in complex environments, and delivering significant improvements over standard baselines without incurring major computational costs.
Generalized Activation via Multivariate Projection
Sep 29, 2023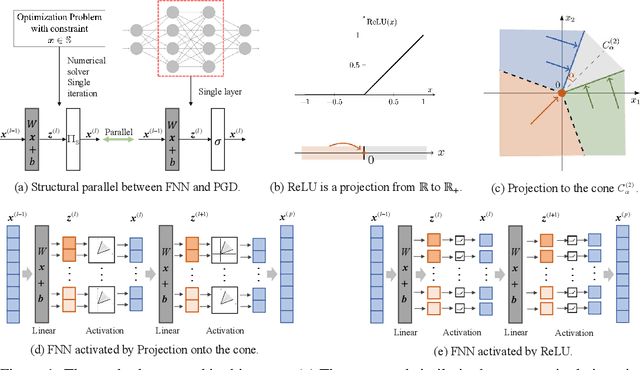
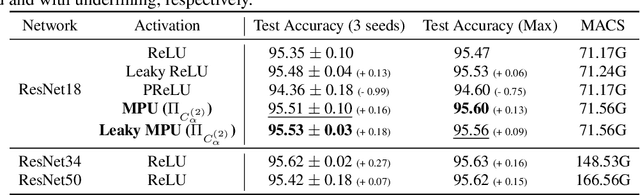
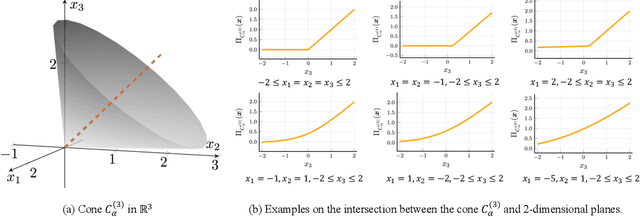
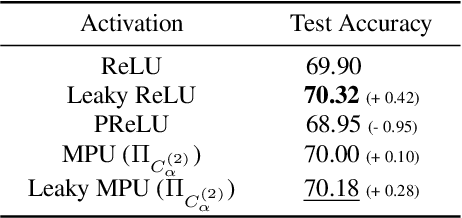
Activation functions are essential to introduce nonlinearity into neural networks, with the Rectified Linear Unit (ReLU) often favored for its simplicity and effectiveness. Motivated by the structural similarity between a shallow Feedforward Neural Network (FNN) and a single iteration of the Projected Gradient Descent (PGD) algorithm, a standard approach for solving constrained optimization problems, we consider ReLU as a projection from R onto the nonnegative half-line R+. Building on this interpretation, we extend ReLU by substituting it with a generalized projection operator onto a convex cone, such as the Second-Order Cone (SOC) projection, thereby naturally extending it to a Multivariate Projection Unit (MPU), an activation function with multiple inputs and multiple outputs. We further provide a mathematical proof establishing that FNNs activated by SOC projections outperform those utilizing ReLU in terms of expressive power. Experimental evaluations on widely-adopted architectures further corroborate MPU's effectiveness against a broader range of existing activation functions.
Consecutive Inertia Drift of Autonomous RC Car via Primitive-based Planning and Data-driven Control
Jun 21, 2023



Inertia drift is an aggressive transitional driving maneuver, which is challenging due to the high nonlinearity of the system and the stringent requirement on control and planning performance. This paper presents a solution for the consecutive inertia drift of an autonomous RC car based on primitive-based planning and data-driven control. The planner generates complex paths via the concatenation of path segments called primitives, and the controller eases the burden on feedback by interpolating between multiple real trajectories with different initial conditions into one near-feasible reference trajectory. The proposed strategy is capable of drifting through various paths containing consecutive turns, which is validated in both simulation and reality.
A Multi-resolution Model for Histopathology Image Classification and Localization with Multiple Instance Learning
Nov 05, 2020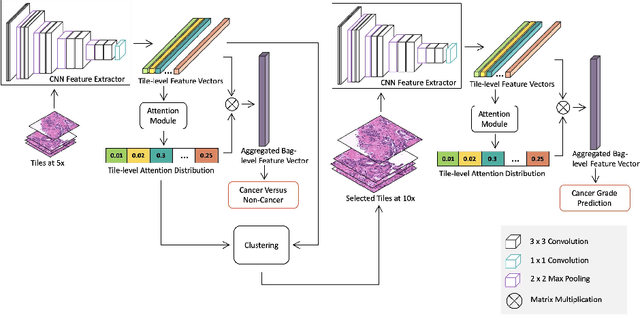
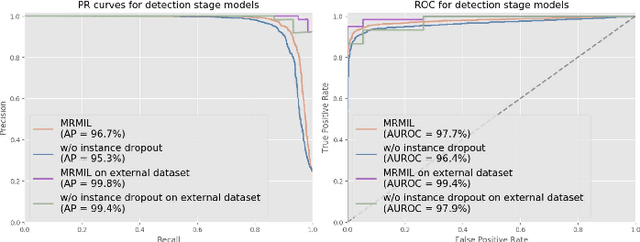
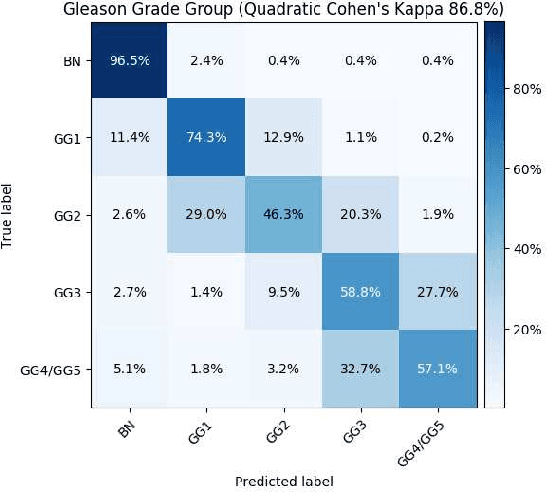
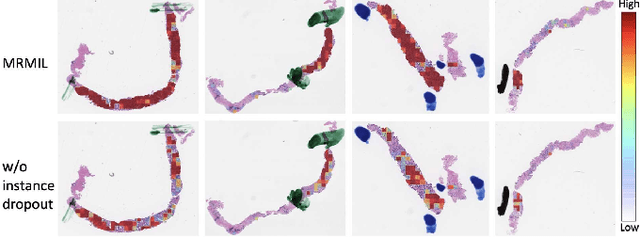
Histopathological images provide rich information for disease diagnosis. Large numbers of histopathological images have been digitized into high resolution whole slide images, opening opportunities in developing computational image analysis tools to reduce pathologists' workload and potentially improve inter- and intra- observer agreement. Most previous work on whole slide image analysis has focused on classification or segmentation of small pre-selected regions-of-interest, which requires fine-grained annotation and is non-trivial to extend for large-scale whole slide analysis. In this paper, we proposed a multi-resolution multiple instance learning model that leverages saliency maps to detect suspicious regions for fine-grained grade prediction. Instead of relying on expensive region- or pixel-level annotations, our model can be trained end-to-end with only slide-level labels. The model is developed on a large-scale prostate biopsy dataset containing 20,229 slides from 830 patients. The model achieved 92.7% accuracy, 81.8% Cohen's Kappa for benign, low grade (i.e. Grade group 1) and high grade (i.e. Grade group >= 2) prediction, an area under the receiver operating characteristic curve (AUROC) of 98.2% and an average precision (AP) of 97.4% for differentiating malignant and benign slides. The model obtained an AUROC of 99.4% and an AP of 99.8% for cancer detection on an external dataset.
Ventral-Dorsal Neural Networks: Object Detection via Selective Attention
May 15, 2020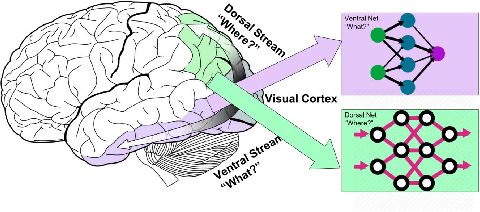
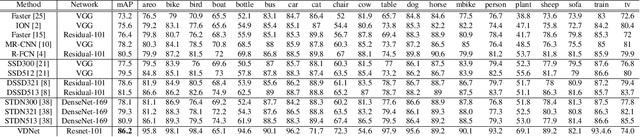
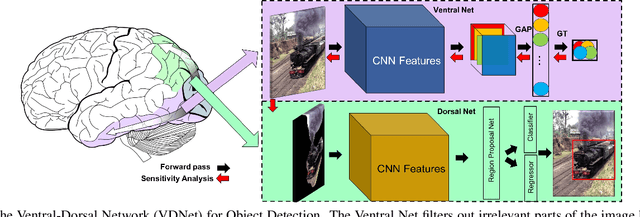

Deep Convolutional Neural Networks (CNNs) have been repeatedly proven to perform well on image classification tasks. Object detection methods, however, are still in need of significant improvements. In this paper, we propose a new framework called Ventral-Dorsal Networks (VDNets) which is inspired by the structure of the human visual system. Roughly, the visual input signal is analyzed along two separate neural streams, one in the temporal lobe and the other in the parietal lobe. The coarse functional distinction between these streams is between object recognition -- the "what" of the signal -- and extracting location related information -- the "where" of the signal. The ventral pathway from primary visual cortex, entering the temporal lobe, is dominated by "what" information, while the dorsal pathway, into the parietal lobe, is dominated by "where" information. Inspired by this structure, we propose the integration of a "Ventral Network" and a "Dorsal Network", which are complementary. Information about object identity can guide localization, and location information can guide attention to relevant image regions, improving object recognition. This new dual network framework sharpens the focus of object detection. Our experimental results reveal that the proposed method outperforms state-of-the-art object detection approaches on PASCAL VOC 2007 by 8% (mAP) and PASCAL VOC 2012 by 3% (mAP). Moreover, a comparison of techniques on Yearbook images displays substantial qualitative and quantitative benefits of VDNet.
Semi-supervised Learning using Adversarial Training with Good and Bad Samples
Oct 18, 2019



In this work, we investigate semi-supervised learning (SSL) for image classification using adversarial training. Previous results have illustrated that generative adversarial networks (GANs) can be used for multiple purposes. Triple-GAN, which aims to jointly optimize model components by incorporating three players, generates suitable image-label pairs to compensate for the lack of labeled data in SSL with improved benchmark performance. Conversely, Bad (or complementary) GAN, optimizes generation to produce complementary data-label pairs and force a classifier's decision boundary to lie between data manifolds. Although it generally outperforms Triple-GAN, Bad GAN is highly sensitive to the amount of labeled data used for training. Unifying these two approaches, we present unified-GAN (UGAN), a novel framework that enables a classifier to simultaneously learn from both good and bad samples through adversarial training. We perform extensive experiments on various datasets and demonstrate that UGAN: 1) achieves state-of-the-art performance among other deep generative models, and 2) is robust to variations in the amount of labeled data used for training.
An attention-based multi-resolution model for prostate whole slide imageclassification and localization
May 30, 2019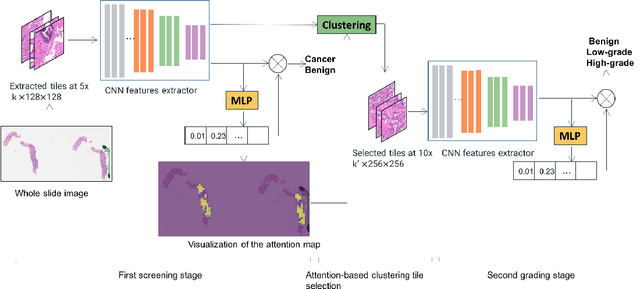

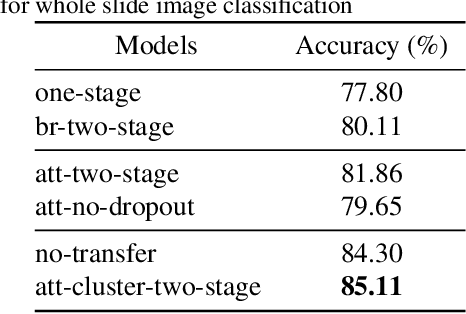
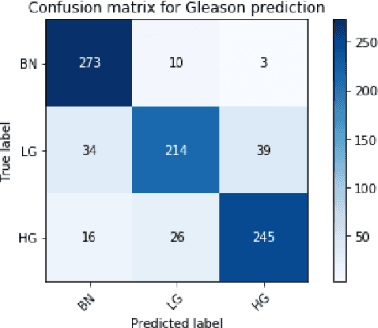
Histology review is often used as the `gold standard' for disease diagnosis. Computer aided diagnosis tools can potentially help improve current pathology workflows by reducing examination time and interobserver variability. Previous work in cancer grading has focused mainly on classifying pre-defined regions of interest (ROIs), or relied on large amounts of fine-grained labels. In this paper, we propose a two-stage attention-based multiple instance learning model for slide-level cancer grading and weakly-supervised ROI detection and demonstrate its use in prostate cancer. Compared with existing Gleason classification models, our model goes a step further by utilizing visualized saliency maps to select informative tiles for fine-grained grade classification. The model was primarily developed on a large-scale whole slide dataset consisting of 3,521 prostate biopsy slides with only slide-level labels from 718 patients. The model achieved state-of-the-art performance for prostate cancer grading with an accuracy of 85.11\% for classifying benign, low-grade (Gleason grade 3+3 or 3+4), and high-grade (Gleason grade 4+3 or higher) slides on an independent test set.
Semi-supervised learning based on generative adversarial network: a comparison between good GAN and bad GAN approach
May 17, 2019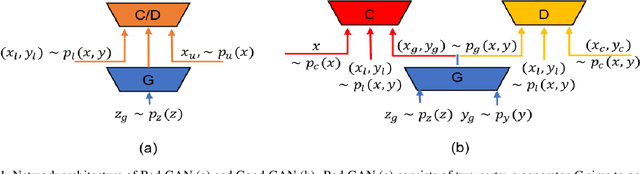



Recently, semi-supervised learning methods based on generative adversarial networks (GANs) have received much attention. Among them, two distinct approaches have achieved competitive results on a variety of benchmark datasets. Bad GAN learns a classifier with unrealistic samples distributed on the complement of the support of the input data. Conversely, Triple GAN consists of a three-player game that tries to leverage good generated samples to boost classification results. In this paper, we perform a comprehensive comparison of these two approaches on different benchmark datasets. We demonstrate their different properties on image generation, and sensitivity to the amount of labeled data provided. By comprehensively comparing these two methods, we hope to shed light on the future of GAN-based semi-supervised learning.