 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Auditory Object Recognition via Inception Nucleus
May 25, 2020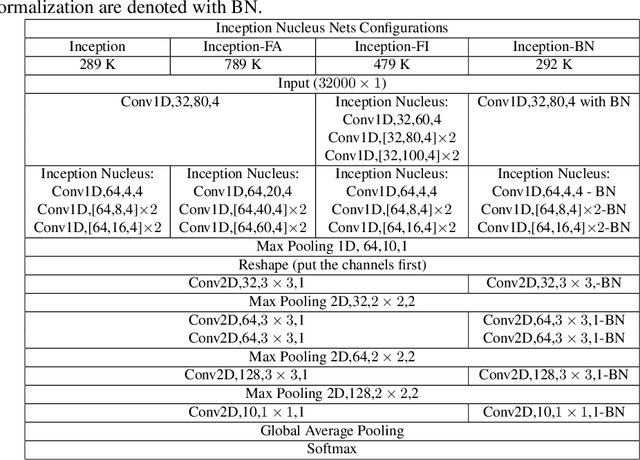
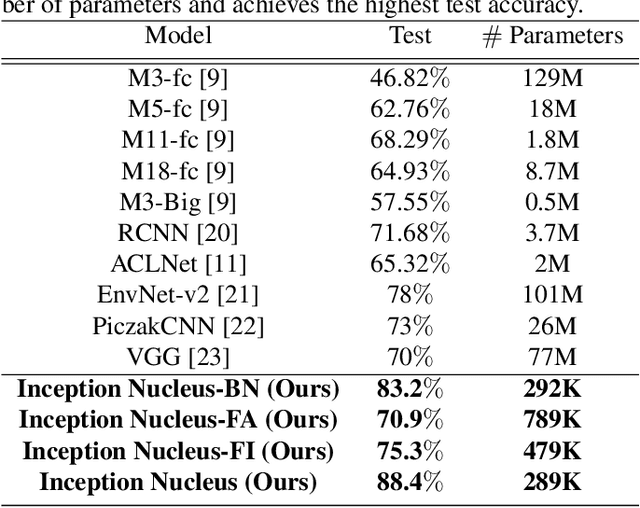


Machine learning approaches to auditory object recognition are traditionally based on engineered features such as those derived from the spectrum or cepstrum. More recently, end-to-end classification systems in image and auditory recognition systems have been developed to learn features jointly with classification and result in improved classification accuracy. In this paper, we propose a novel end-to-end deep neural network to map the raw waveform inputs to sound class labels. Our network includes an "inception nucleus" that optimizes the size of convolutional filters on the fly that results in reducing engineering efforts dramatically. Classification results compared favorably against current state-of-the-art approaches, besting them by 10.4 percentage points on the Urbansound8k dataset. Analyses of learned representations revealed that filters in the earlier hidden layers learned wavelet-like transforms to extract features that were informative for classification.
Ventral-Dorsal Neural Networks: Object Detection via Selective Attention
May 15, 2020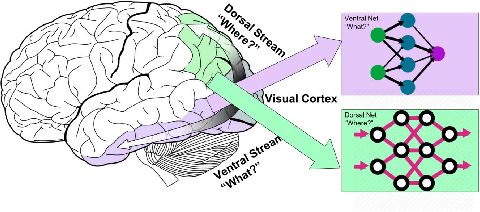
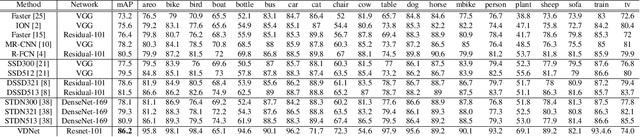
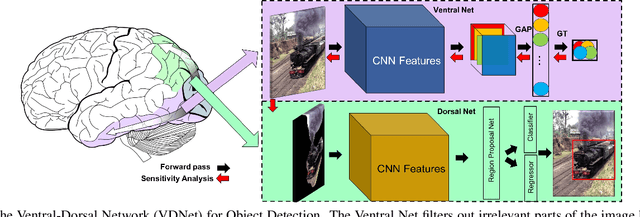

Deep Convolutional Neural Networks (CNNs) have been repeatedly proven to perform well on image classification tasks. Object detection methods, however, are still in need of significant improvements. In this paper, we propose a new framework called Ventral-Dorsal Networks (VDNets) which is inspired by the structure of the human visual system. Roughly, the visual input signal is analyzed along two separate neural streams, one in the temporal lobe and the other in the parietal lobe. The coarse functional distinction between these streams is between object recognition -- the "what" of the signal -- and extracting location related information -- the "where" of the signal. The ventral pathway from primary visual cortex, entering the temporal lobe, is dominated by "what" information, while the dorsal pathway, into the parietal lobe, is dominated by "where" information. Inspired by this structure, we propose the integration of a "Ventral Network" and a "Dorsal Network", which are complementary. Information about object identity can guide localization, and location information can guide attention to relevant image regions, improving object recognition. This new dual network framework sharpens the focus of object detection. Our experimental results reveal that the proposed method outperforms state-of-the-art object detection approaches on PASCAL VOC 2007 by 8% (mAP) and PASCAL VOC 2012 by 3% (mAP). Moreover, a comparison of techniques on Yearbook images displays substantial qualitative and quantitative benefits of VDNet.
WW-Nets: Dual Neural Networks for Object Detection
May 15, 2020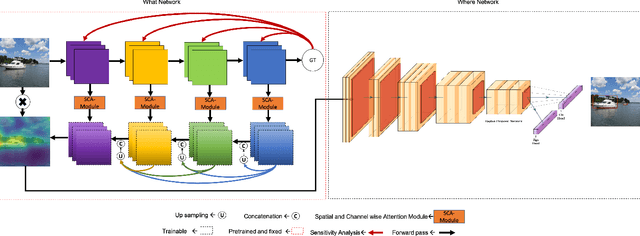

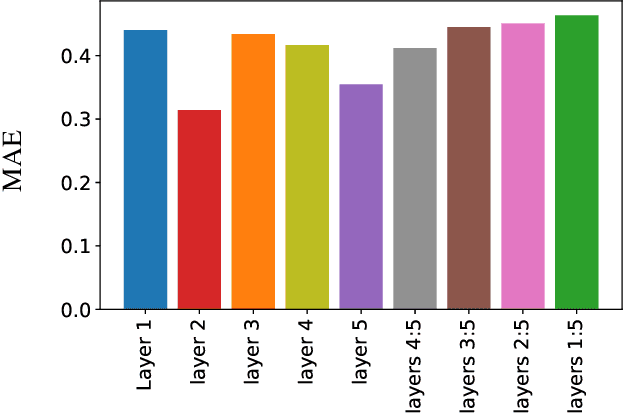
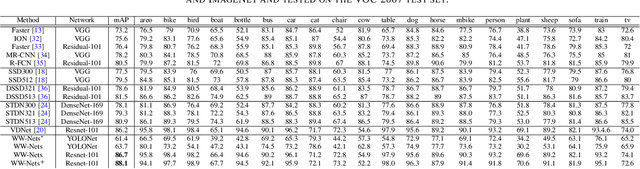
We propose a new deep convolutional neural network framework that uses object location knowledge implicit in network connection weights to guide selective attention in object detection tasks. Our approach is called What-Where Nets (WW-Nets), and it is inspired by the structure of human visual pathways. In the brain, vision incorporates two separate streams, one in the temporal lobe and the other in the parietal lobe, called the ventral stream and the dorsal stream, respectively. The ventral pathway from primary visual cortex is dominated by "what" information, while the dorsal pathway is dominated by "where" information. Inspired by this structure, we have proposed an object detection framework involving the integration of a "What Network" and a "Where Network". The aim of the What Network is to provide selective attention to the relevant parts of the input image. The Where Network uses this information to locate and classify objects of interest. In this paper, we compare this approach to state-of-the-art algorithms on the PASCAL VOC 2007 and 2012 and COCO object detection challenge datasets. Also, we compare out approach to human "ground-truth" attention. We report the results of an eye-tracking experiment on human subjects using images from PASCAL VOC 2007, and we demonstrate interesting relationships between human overt attention and information processing in our WW-Nets. Finally, we provide evidence that our proposed method performs favorably in comparison to other object detection approaches, often by a large margin. The code and the eye-tracking ground-truth dataset can be found at: https://github.com/mkebrahimpour.
Efficient Exploration through Intrinsic Motivation Learning for Unsupervised Subgoal Discovery in Model-Free Hierarchical Reinforcement Learning
Nov 18, 2019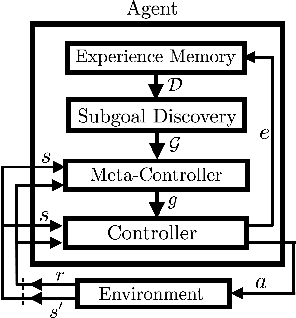

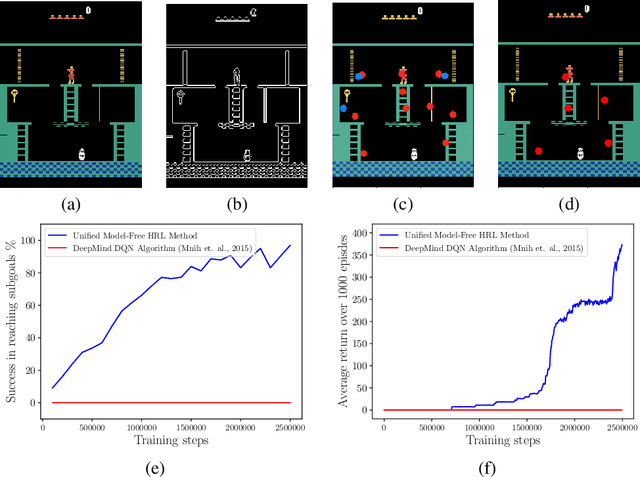
Efficient exploration for automatic subgoal discovery is a challenging problem in Hierarchical Reinforcement Learning (HRL). In this paper, we show that intrinsic motivation learning increases the efficiency of exploration, leading to successful subgoal discovery. We introduce a model-free subgoal discovery method based on unsupervised learning over a limited memory of agent's experiences during intrinsic motivation. Additionally, we offer a unified approach to learning representations in model-free HRL.
Learning sparse representations in reinforcement learning
Sep 04, 2019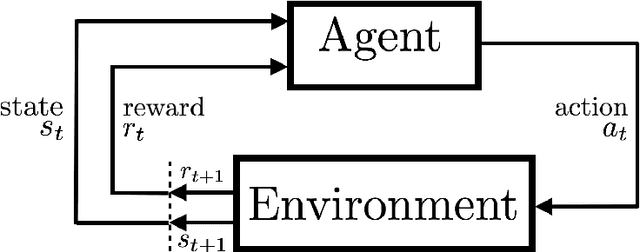

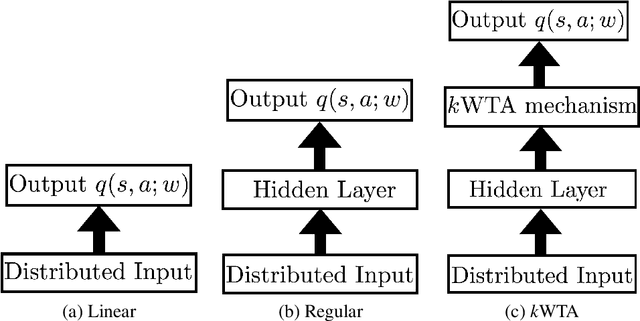
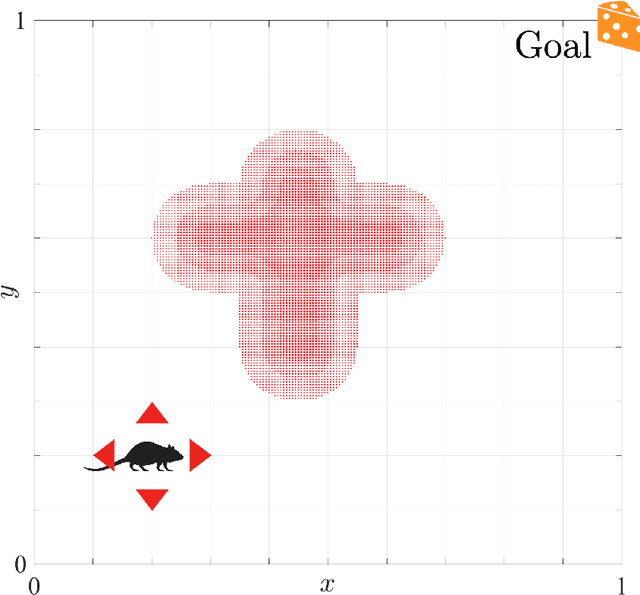
Reinforcement learning (RL) algorithms allow artificial agents to improve their selection of actions to increase rewarding experiences in their environments. Temporal Difference (TD) Learning -- a model-free RL method -- is a leading account of the midbrain dopamine system and the basal ganglia in reinforcement learning. These algorithms typically learn a mapping from the agent's current sensed state to a selected action (known as a policy function) via learning a value function (expected future rewards). TD Learning methods have been very successful on a broad range of control tasks, but learning can become intractably slow as the state space of the environment grows. This has motivated methods that learn internal representations of the agent's state, effectively reducing the size of the state space and restructuring state representations in order to support generalization. However, TD Learning coupled with an artificial neural network, as a function approximator, has been shown to fail to learn some fairly simple control tasks, challenging this explanation of reward-based learning. We hypothesize that such failures do not arise in the brain because of the ubiquitous presence of lateral inhibition in the cortex, producing sparse distributed internal representations that support the learning of expected future reward. The sparse conjunctive representations can avoid catastrophic interference while still supporting generalization. We provide support for this conjecture through computational simulations, demonstrating the benefits of learned sparse representations for three problematic classic control tasks: Puddle-world, Mountain-car, and Acrobot.
Learning Representations in Model-Free Hierarchical Reinforcement Learning
Oct 25, 2018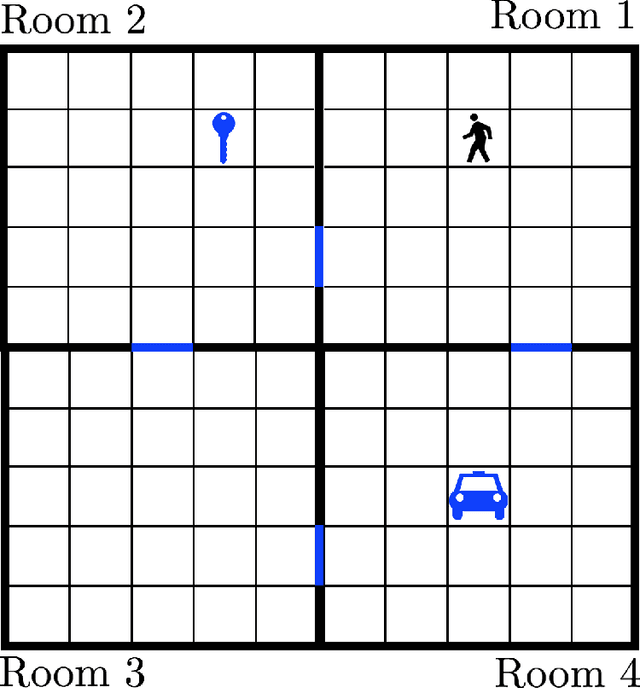
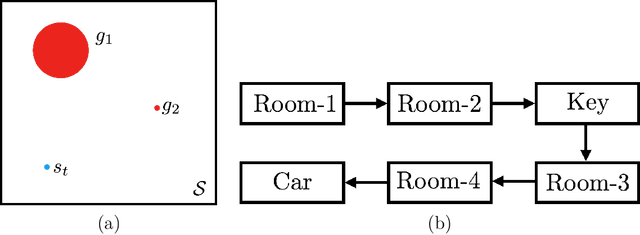
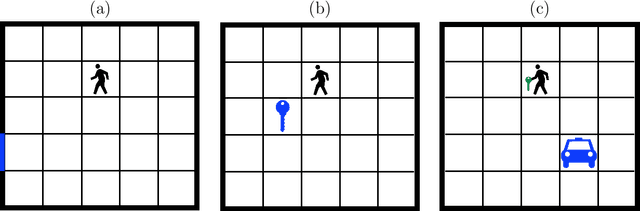

Common approaches to Reinforcement Learning (RL) are seriously challenged by large-scale applications involving huge state spaces and sparse delayed reward feedback. Hierarchical Reinforcement Learning (HRL) methods attempt to address this scalability issue by learning action selection policies at multiple levels of temporal abstraction. Abstraction can be had by identifying a relatively small set of states that are likely to be useful as subgoals, in concert with the learning of corresponding skill policies to achieve those subgoals. Many approaches to subgoal discovery in HRL depend on the analysis of a model of the environment, but the need to learn such a model introduces its own problems of scale. Once subgoals are identified, skills may be learned through intrinsic motivation, introducing an internal reward signal marking subgoal attainment. In this paper, we present a novel model-free method for subgoal discovery using incremental unsupervised learning over a small memory of the most recent experiences of the agent. When combined with an intrinsic motivation learning mechanism, this method learns subgoals and skills together, based on experiences in the environment. Thus, we offer an original approach to HRL that does not require the acquisition of a model of the environment, suitable for large-scale applications. We demonstrate the efficiency of our method on two RL problems with sparse delayed feedback: a variant of the rooms environment and the ATARI 2600 game called Montezuma's Revenge.