 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-dimensional representation of infant and adult vocalization acoustics
Apr 25, 2022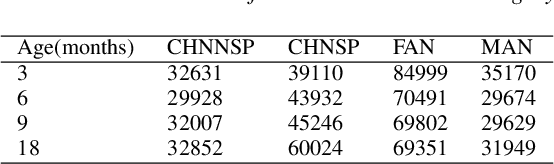
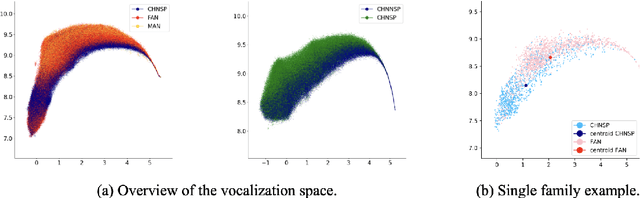
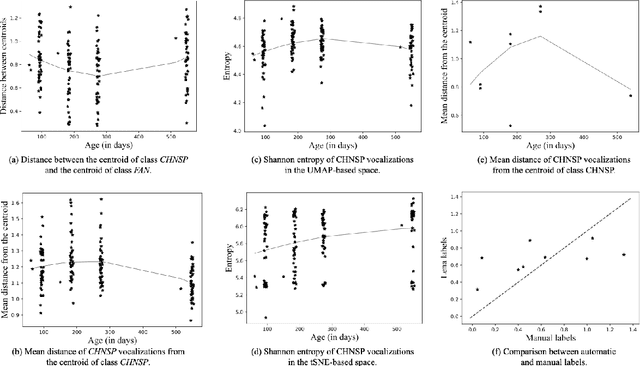
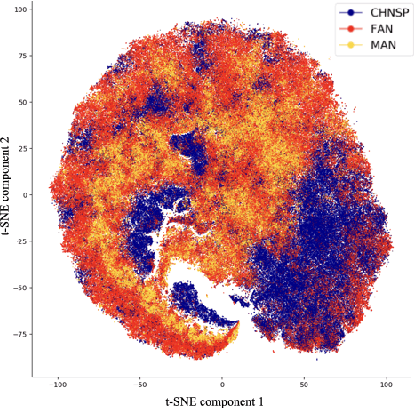
During the first years of life, infant vocalizations change considerably, as infants develop the vocalization skills that enable them to produce speech sounds. Characterizations based on specific acoustic features, protophone categories, or phonetic transcription are able to provide a representation of the sounds infants make at different ages and in different contexts but do not fully describe how sounds are perceived by listeners, can be inefficient to obtain at large scales, and are difficult to visualize in two dimensions without additional statistical processing. Machine-learning-based approaches provide the opportunity to complement these characterizations with purely data-driven representations of infant sounds. Here, we use spectral features extraction and unsupervised machine learning, specifically Uniform Manifold Approximation (UMAP), to obtain a novel 2-dimensional spatial representation of infant and caregiver vocalizations extracted from day-long home recordings. UMAP yields a continuous and well-distributed space conducive to certain analyses of infant vocal development. For instance, we found that the dispersion of infant vocalization acoustics within the 2-D space over a day increased from 3 to 9 months, and then decreased from 9 to 18 months. The method also permits analysis of similarity between infant and adult vocalizations, which also shows changes with infant age.
Image-based eeg classification of brain responses to song recordings
Jan 31, 2022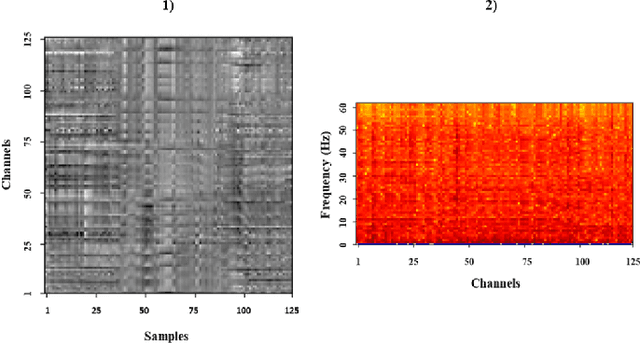
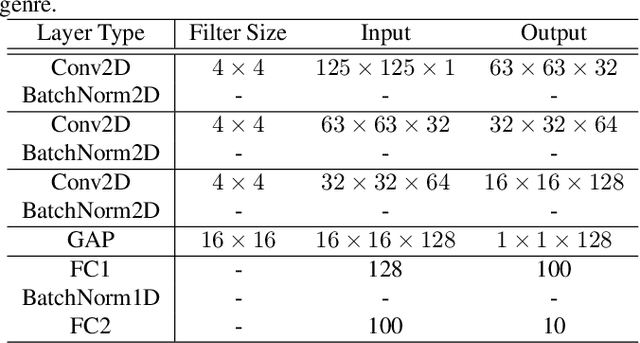
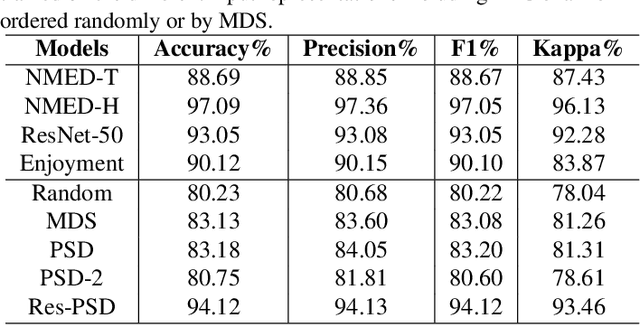
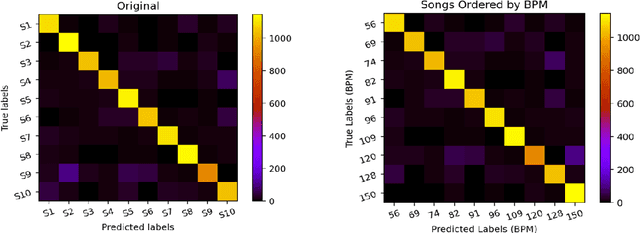
Classifying EEG responses to naturalistic acoustic stimuli is of theoretical and practical importance, but standard approaches are limited by processing individual channels separately on very short sound segments (a few seconds or less). Recent developments have shown classification for music stimuli (~2 mins) by extracting spectral components from EEG and using convolutional neural networks (CNNs). This paper proposes an efficient method to map raw EEG signals to individual songs listened for end-to-end classification. EEG channels are treated as a dimension of a [Channel x Sample] image tile, and images are classified using CNNs. Our experimental results (88.7%) compete with state-of-the-art methods (85.0%), yet our classification task is more challenging by processing longer stimuli that were similar to each other in perceptual quality, and were unfamiliar to participants. We also adopt a transfer learning scheme using a pre-trained ResNet-50, confirming the effectiveness of transfer learning despite image domains unrelated from each other.
End-to-End Auditory Object Recognition via Inception Nucleus
May 25, 2020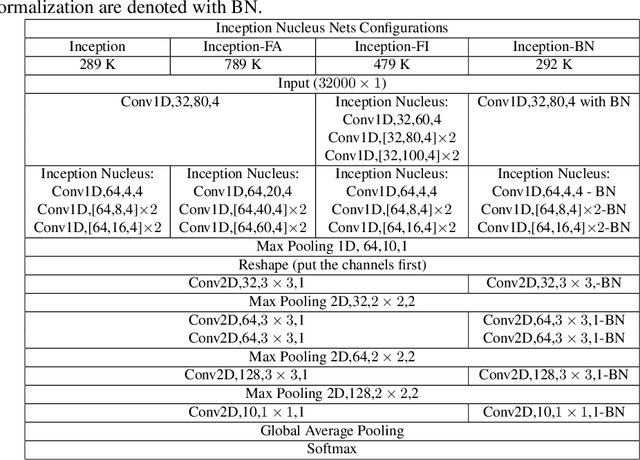
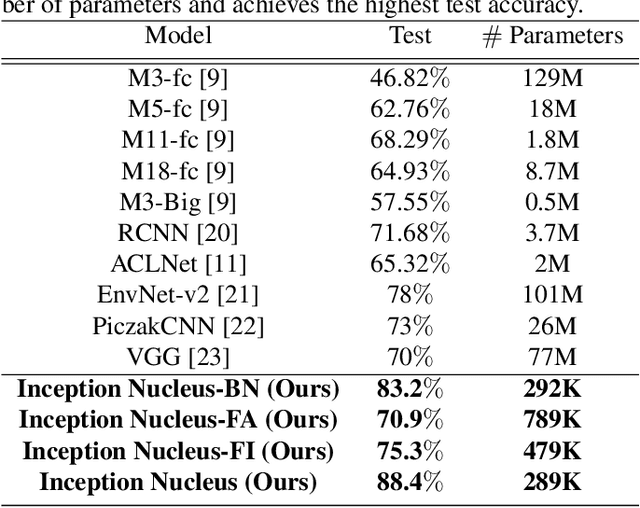


Machine learning approaches to auditory object recognition are traditionally based on engineered features such as those derived from the spectrum or cepstrum. More recently, end-to-end classification systems in image and auditory recognition systems have been developed to learn features jointly with classification and result in improved classification accuracy. In this paper, we propose a novel end-to-end deep neural network to map the raw waveform inputs to sound class labels. Our network includes an "inception nucleus" that optimizes the size of convolutional filters on the fly that results in reducing engineering efforts dramatically. Classification results compared favorably against current state-of-the-art approaches, besting them by 10.4 percentage points on the Urbansound8k dataset. Analyses of learned representations revealed that filters in the earlier hidden layers learned wavelet-like transforms to extract features that were informative for classification.