 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Automatic Scoring and Feedback using Large Language Models
May 01, 2024Automatic grading and feedback have been long studied using traditional machine learning and deep learning techniques using language models. With the recent accessibility to high performing large language models (LLMs) like LLaMA-2, there is an opportunity to investigate the use of these LLMs for automatic grading and feedback generation. Despite the increase in performance, LLMs require significant computational resources for fine-tuning and additional specific adjustments to enhance their performance for such tasks. To address these issues, Parameter Efficient Fine-tuning (PEFT) methods, such as LoRA and QLoRA, have been adopted to decrease memory and computational requirements in model fine-tuning. This paper explores the efficacy of PEFT-based quantized models, employing classification or regression head, to fine-tune LLMs for automatically assigning continuous numerical grades to short answers and essays, as well as generating corresponding feedback. We conducted experiments on both proprietary and open-source datasets for our tasks. The results show that prediction of grade scores via finetuned LLMs are highly accurate, achieving less than 3% error in grade percentage on average. For providing graded feedback fine-tuned 4-bit quantized LLaMA-2 13B models outperform competitive base models and achieve high similarity with subject matter expert feedback in terms of high BLEU and ROUGE scores and qualitatively in terms of feedback. The findings from this study provide important insights into the impacts of the emerging capabilities of using quantization approaches to fine-tune LLMs for various downstream tasks, such as automatic short answer scoring and feedback generation at comparatively lower costs and latency.
PercentMatch: Percentile-based Dynamic Thresholding for Multi-Label Semi-Supervised Classification
Aug 30, 2022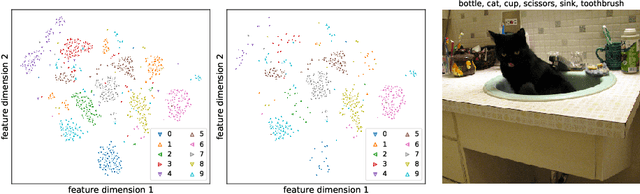
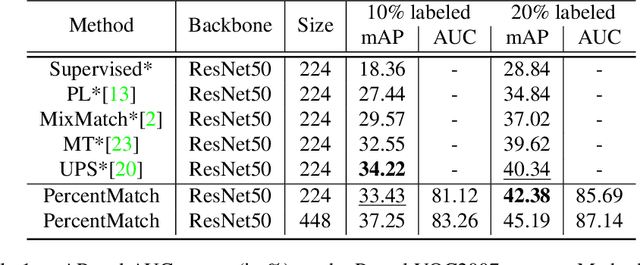
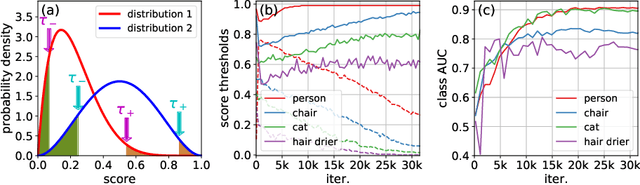
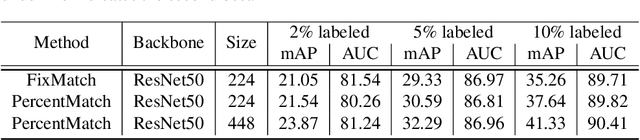
While much of recent study in semi-supervised learning (SSL) has achieved strong performance on single-label classification problems, an equally important yet underexplored problem is how to leverage the advantage of unlabeled data in multi-label classification tasks. To extend the success of SSL to multi-label classification, we first analyze with illustrative examples to get some intuition about the extra challenges exist in multi-label classification. Based on the analysis, we then propose PercentMatch, a percentile-based threshold adjusting scheme, to dynamically alter the score thresholds of positive and negative pseudo-labels for each class during the training, as well as dynamic unlabeled loss weights that further reduces noise from early-stage unlabeled predictions. Without loss of simplicity, we achieve strong performance on Pascal VOC2007 and MS-COCO datasets when compared to recent SSL methods.
Ventral-Dorsal Neural Networks: Object Detection via Selective Attention
May 15, 2020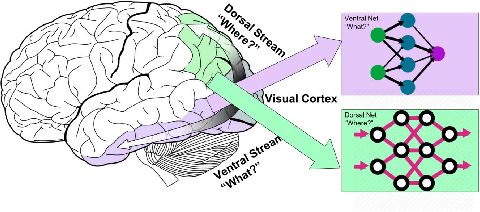
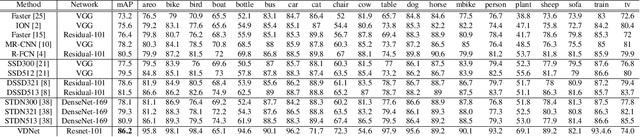
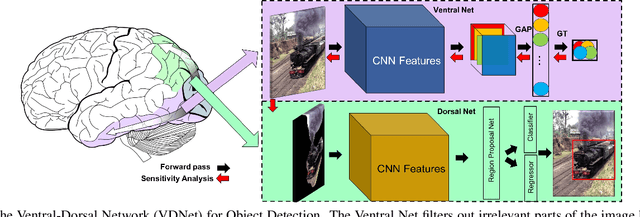

Deep Convolutional Neural Networks (CNNs) have been repeatedly proven to perform well on image classification tasks. Object detection methods, however, are still in need of significant improvements. In this paper, we propose a new framework called Ventral-Dorsal Networks (VDNets) which is inspired by the structure of the human visual system. Roughly, the visual input signal is analyzed along two separate neural streams, one in the temporal lobe and the other in the parietal lobe. The coarse functional distinction between these streams is between object recognition -- the "what" of the signal -- and extracting location related information -- the "where" of the signal. The ventral pathway from primary visual cortex, entering the temporal lobe, is dominated by "what" information, while the dorsal pathway, into the parietal lobe, is dominated by "where" information. Inspired by this structure, we propose the integration of a "Ventral Network" and a "Dorsal Network", which are complementary. Information about object identity can guide localization, and location information can guide attention to relevant image regions, improving object recognition. This new dual network framework sharpens the focus of object detection. Our experimental results reveal that the proposed method outperforms state-of-the-art object detection approaches on PASCAL VOC 2007 by 8% (mAP) and PASCAL VOC 2012 by 3% (mAP). Moreover, a comparison of techniques on Yearbook images displays substantial qualitative and quantitative benefits of VDNet.
Illegible Text to Readable Text: An Image-to-Image Transformation using Conditional Sliced Wasserstein Adversarial Networks
Oct 11, 2019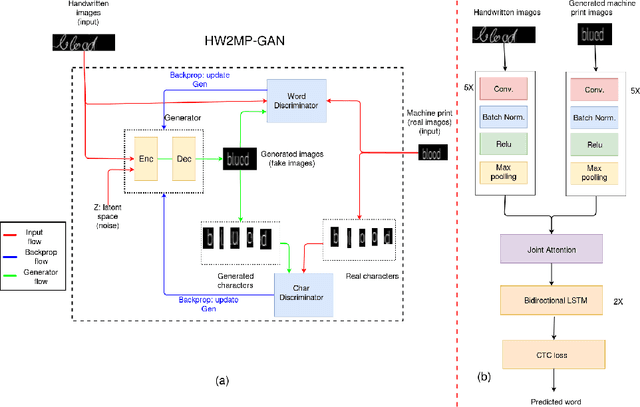
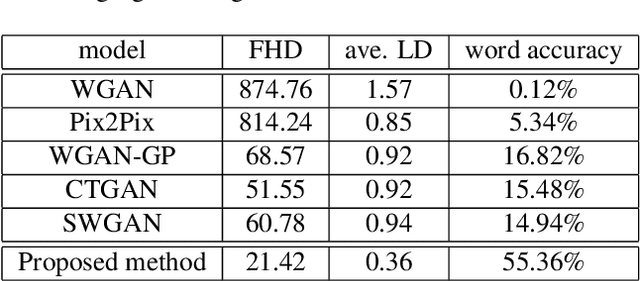


Automatic text recognition from ancient handwritten record images is an important problem in the genealogy domain. However, critical challenges such as varying noise conditions, vanishing texts, and variations in handwriting make the recognition task difficult. We tackle this problem by developing a handwritten-to-machine-print conditional Generative Adversarial network (HW2MP-GAN) model that formulates handwritten recognition as a text-Image-to-text-Image translation problem where a given image, typically in an illegible form, is converted into another image, close to its machine-print form. The proposed model consists of three-components including a generator, and word-level and character-level discriminators. The model incorporates Sliced Wasserstein distance (SWD) and U-Net architectures in HW2MP-GAN for better quality image-to-image transformation. Our experiments reveal that HW2MP-GAN outperforms state-of-the-art baseline cGAN models by almost 30 in Frechet Handwritten Distance (FHD), 0.6 on average Levenshtein distance and 39% in word accuracy for image-to-image translation on IAM database. Further, HW2MP-GAN improves handwritten recognition word accuracy by 1.3% compared to baseline handwritten recognition models on the IAM database.
Image captioning with weakly-supervised attention penalty
Mar 06, 2019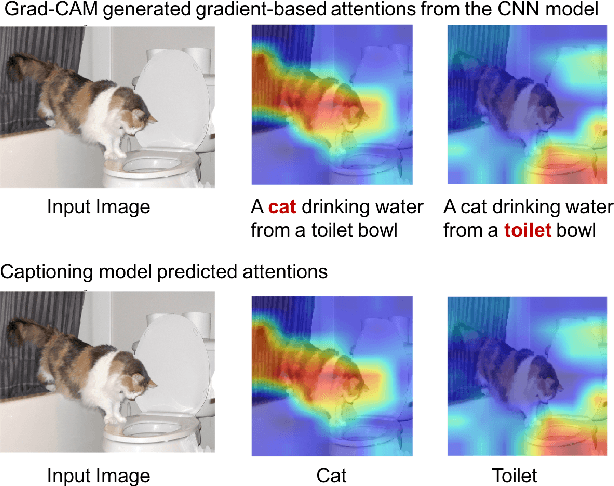
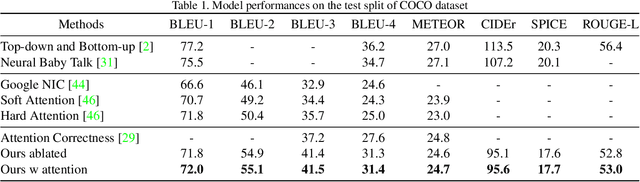
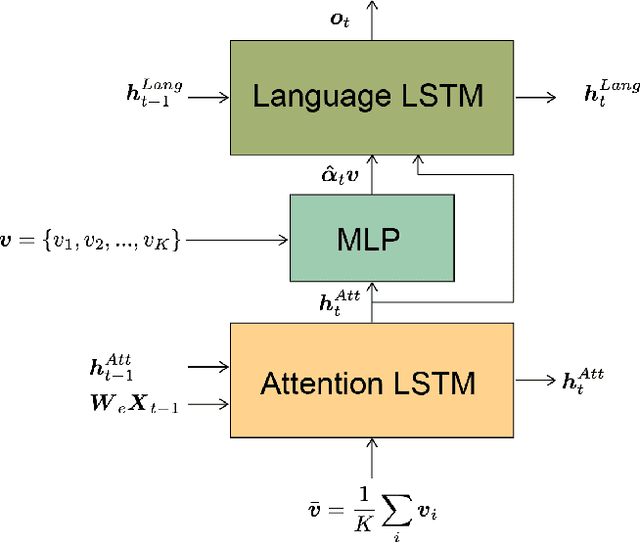

Stories are essential for genealogy research since they can help build emotional connections with people. A lot of family stories are reserved in historical photos and albums. Recent development on image captioning models makes it feasible to "tell stories" for photos automatically. The attention mechanism has been widely adopted in many state-of-the-art encoder-decoder based image captioning models, since it can bridge the gap between the visual part and the language part. Most existing captioning models implicitly trained attention modules with word-likelihood loss. Meanwhile, lots of studies have investigated intrinsic attentions for visual models using gradient-based approaches. Ideally, attention maps predicted by captioning models should be consistent with intrinsic attentions from visual models for any given visual concept. However, no work has been done to align implicitly learned attention maps with intrinsic visual attentions. In this paper, we proposed a novel model that measured consistency between captioning predicted attentions and intrinsic visual attentions. This alignment loss allows explicit attention correction without using any expensive bounding box annotations. We developed and evaluated our model on COCO dataset as well as a genealogical dataset from Ancestry.com Operations Inc., which contains billions of historical photos. The proposed model achieved better performances on all commonly used language evaluation metrics for both datasets.
Clustering With Pairwise Relationships: A Generative Approach
May 06, 2018
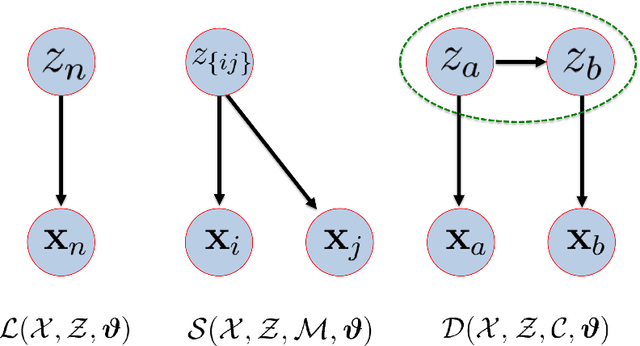
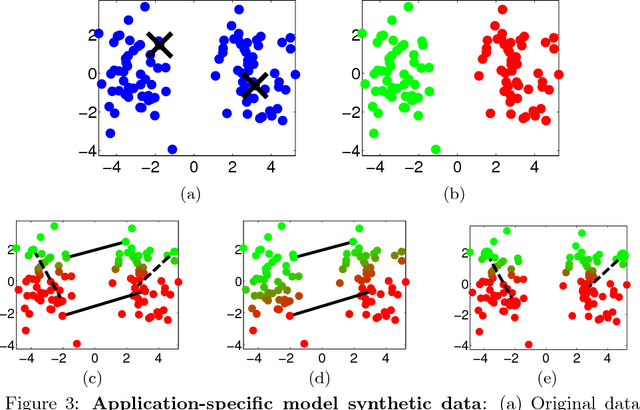
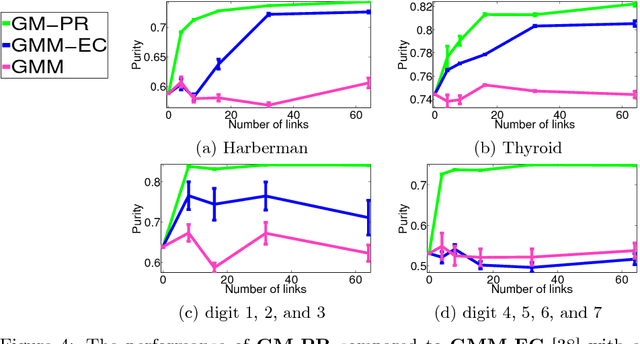
Semi-supervised learning (SSL) has become important in current data analysis applications, where the amount of unlabeled data is growing exponentially and user input remains limited by logistics and expense. Constrained clustering, as a subclass of SSL, makes use of user input in the form of relationships between data points (e.g., pairs of data points belonging to the same class or different classes) and can remarkably improve the performance of unsupervised clustering in order to reflect user-defined knowledge of the relationships between particular data points. Existing algorithms incorporate such user input, heuristically, as either hard constraints or soft penalties, which are separate from any generative or statistical aspect of the clustering model; this results in formulations that are suboptimal and not sufficiently general. In this paper, we propose a principled, generative approach to probabilistically model, without ad hoc penalties, the joint distribution given by user-defined pairwise relations. The proposed model accounts for general underlying distributions without assuming a specific form and relies on expectation-maximization for model fitting. For distributions in a standard form, the proposed approach results in a closed-form solution for updated parameters.
Hierarchical Graphical Models for Multigroup Shape Analysis using Expectation Maximization with Sampling in Kendall's Shape Space
Jan 10, 2013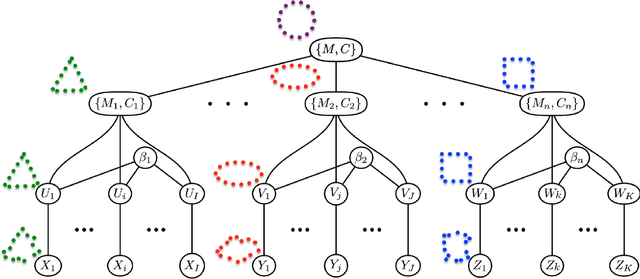
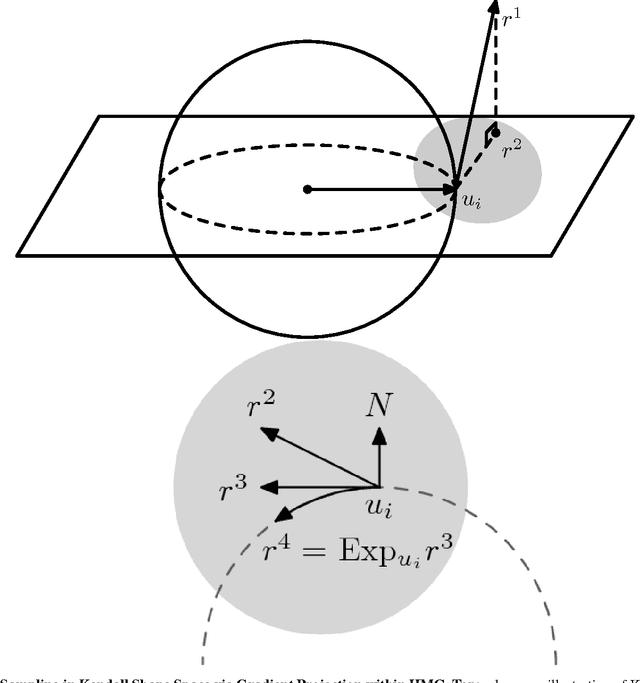

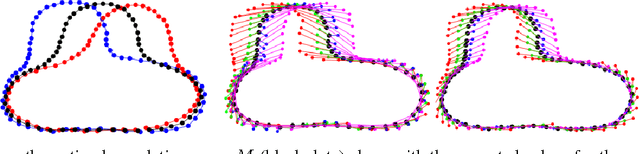
This paper proposes a novel framework for multi-group shape analysis relying on a hierarchical graphical statistical model on shapes within a population.The framework represents individual shapes as point setsmodulo translation, rotation, and scale, following the notion in Kendall shape space.While individual shapes are derived from their group shape model, each group shape model is derived from a single population shape model. The hierarchical model follows the natural organization of population data and the top level in the hierarchy provides a common frame of reference for multigroup shape analysis, e.g. classification and hypothesis testing. Unlike typical shape-modeling approaches, the proposed model is a generative model that defines a joint distribution of object-boundary data and the shape-model variables. Furthermore, it naturally enforces optimal correspondences during the process of model fitting and thereby subsumes the so-called correspondence problem. The proposed inference scheme employs an expectation maximization (EM) algorithm that treats the individual and group shape variables as hidden random variables and integrates them out before estimating the parameters (population mean and variance and the group variances). The underpinning of the EM algorithm is the sampling of pointsets, in Kendall shape space, from their posterior distribution, for which we exploit a highly-efficient scheme based on Hamiltonian Monte Carlo simulation. Experiments in this paper use the fitted hierarchical model to perform (1) hypothesis testing for comparison between pairs of groups using permutation testing and (2) classification for image retrieval. The paper validates the proposed framework on simulated data and demonstrates results on real data.