 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePercentMatch: Percentile-based Dynamic Thresholding for Multi-Label Semi-Supervised Classification
Paper and Code
Aug 30, 2022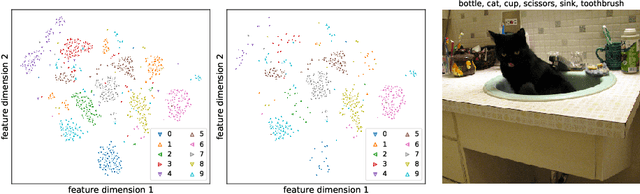
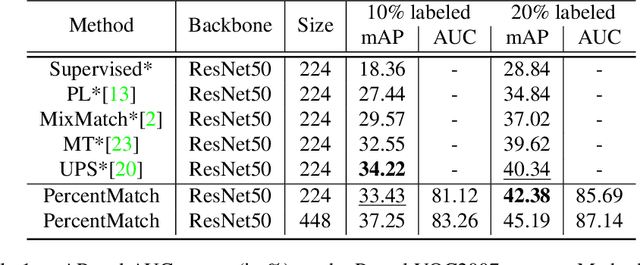
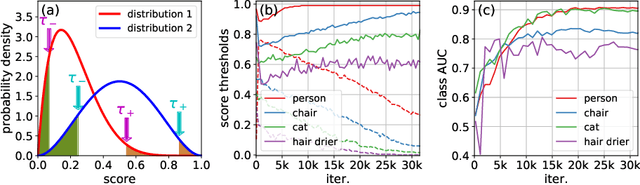
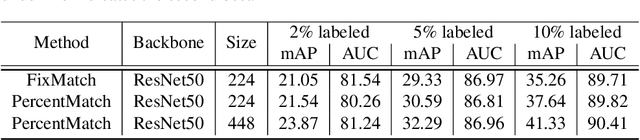
While much of recent study in semi-supervised learning (SSL) has achieved strong performance on single-label classification problems, an equally important yet underexplored problem is how to leverage the advantage of unlabeled data in multi-label classification tasks. To extend the success of SSL to multi-label classification, we first analyze with illustrative examples to get some intuition about the extra challenges exist in multi-label classification. Based on the analysis, we then propose PercentMatch, a percentile-based threshold adjusting scheme, to dynamically alter the score thresholds of positive and negative pseudo-labels for each class during the training, as well as dynamic unlabeled loss weights that further reduces noise from early-stage unlabeled predictions. Without loss of simplicity, we achieve strong performance on Pascal VOC2007 and MS-COCO datasets when compared to recent SSL methods.