 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWW-Nets: Dual Neural Networks for Object Detection
Paper and Code
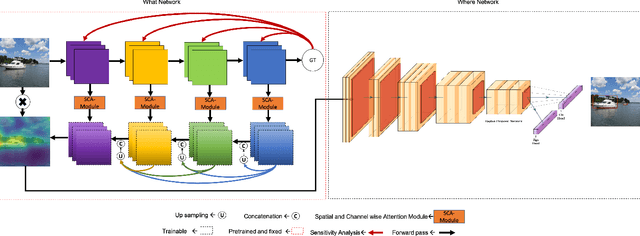

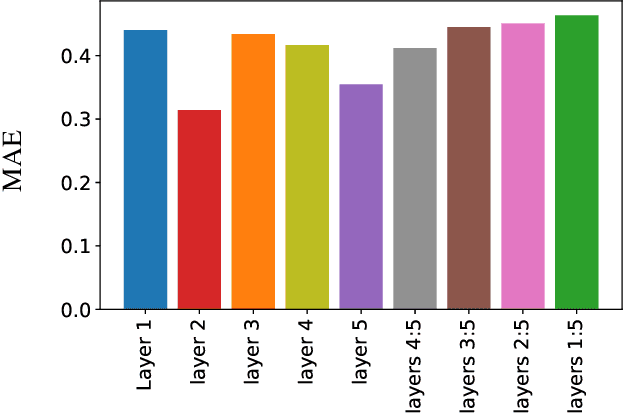
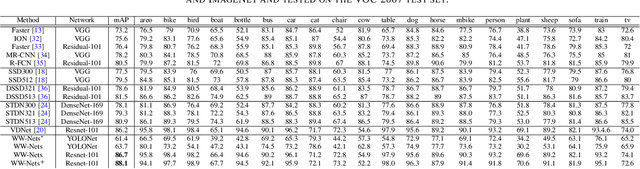
We propose a new deep convolutional neural network framework that uses object location knowledge implicit in network connection weights to guide selective attention in object detection tasks. Our approach is called What-Where Nets (WW-Nets), and it is inspired by the structure of human visual pathways. In the brain, vision incorporates two separate streams, one in the temporal lobe and the other in the parietal lobe, called the ventral stream and the dorsal stream, respectively. The ventral pathway from primary visual cortex is dominated by "what" information, while the dorsal pathway is dominated by "where" information. Inspired by this structure, we have proposed an object detection framework involving the integration of a "What Network" and a "Where Network". The aim of the What Network is to provide selective attention to the relevant parts of the input image. The Where Network uses this information to locate and classify objects of interest. In this paper, we compare this approach to state-of-the-art algorithms on the PASCAL VOC 2007 and 2012 and COCO object detection challenge datasets. Also, we compare out approach to human "ground-truth" attention. We report the results of an eye-tracking experiment on human subjects using images from PASCAL VOC 2007, and we demonstrate interesting relationships between human overt attention and information processing in our WW-Nets. Finally, we provide evidence that our proposed method performs favorably in comparison to other object detection approaches, often by a large margin. The code and the eye-tracking ground-truth dataset can be found at: https://github.com/mkebrahimpour.