 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Behavior Cloning Improves Causal Reasoning: An Open Model for Real-Time Video Game Playing
Jan 08, 2026Behavior cloning is enjoying a resurgence in popularity as scaling both model and data sizes proves to provide a strong starting point for many tasks of interest. In this work, we introduce an open recipe for training a video game playing foundation model designed for inference in realtime on a consumer GPU. We release all data (8300+ hours of high quality human gameplay), training and inference code, and pretrained checkpoints under an open license. We show that our best model is capable of playing a variety of 3D video games at a level competitive with human play. We use this recipe to systematically examine the scaling laws of behavior cloning to understand how the model's performance and causal reasoning varies with model and data scale. We first show in a simple toy problem that, for some types of causal reasoning, increasing both the amount of training data and the depth of the network results in the model learning a more causal policy. We then systematically study how causality varies with the number of parameters (and depth) and training steps in scaled models of up to 1.2 billion parameters, and we find similar scaling results to what we observe in the toy problem.
Pixels to Play: A Foundation Model for 3D Gameplay
Aug 19, 2025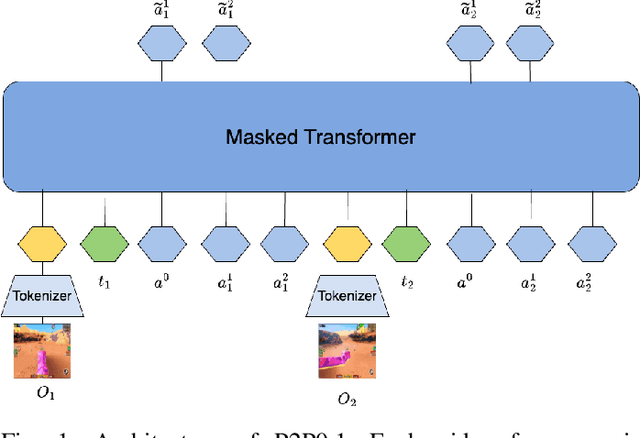
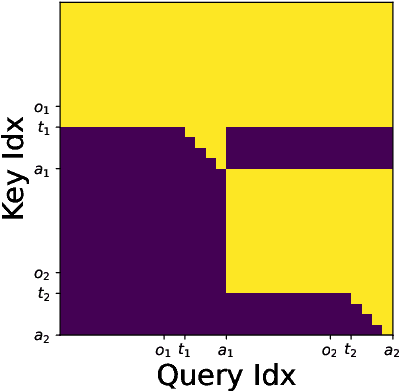

We introduce Pixels2Play-0.1 (P2P0.1), a foundation model that learns to play a wide range of 3D video games with recognizable human-like behavior. Motivated by emerging consumer and developer use cases - AI teammates, controllable NPCs, personalized live-streamers, assistive testers - we argue that an agent must rely on the same pixel stream available to players and generalize to new titles with minimal game-specific engineering. P2P0.1 is trained end-to-end with behavior cloning: labeled demonstrations collected from instrumented human game-play are complemented by unlabeled public videos, to which we impute actions via an inverse-dynamics model. A decoder-only transformer with auto-regressive action output handles the large action space while remaining latency-friendly on a single consumer GPU. We report qualitative results showing competent play across simple Roblox and classic MS-DOS titles, ablations on unlabeled data, and outline the scaling and evaluation steps required to reach expert-level, text-conditioned control.
MAML-en-LLM: Model Agnostic Meta-Training of LLMs for Improved In-Context Learning
May 19, 2024



Adapting large language models (LLMs) to unseen tasks with in-context training samples without fine-tuning remains an important research problem. To learn a robust LLM that adapts well to unseen tasks, multiple meta-training approaches have been proposed such as MetaICL and MetaICT, which involve meta-training pre-trained LLMs on a wide variety of diverse tasks. These meta-training approaches essentially perform in-context multi-task fine-tuning and evaluate on a disjointed test set of tasks. Even though they achieve impressive performance, their goal is never to compute a truly general set of parameters. In this paper, we propose MAML-en-LLM, a novel method for meta-training LLMs, which can learn truly generalizable parameters that not only perform well on disjointed tasks but also adapts to unseen tasks. We see an average increase of 2% on unseen domains in the performance while a massive 4% improvement on adaptation performance. Furthermore, we demonstrate that MAML-en-LLM outperforms baselines in settings with limited amount of training data on both seen and unseen domains by an average of 2%. Finally, we discuss the effects of type of tasks, optimizers and task complexity, an avenue barely explored in meta-training literature. Exhaustive experiments across 7 task settings along with two data settings demonstrate that models trained with MAML-en-LLM outperform SOTA meta-training approaches.
Learning to Rank For Push Notifications Using Pairwise Expected Regret
Jan 19, 2022

Listwise ranking losses have been widely studied in recommender systems. However, new paradigms of content consumption present new challenges for ranking methods. In this work we contribute an analysis of learning to rank for personalized mobile push notifications and discuss the unique challenges this presents compared to traditional ranking problems. To address these challenges, we introduce a novel ranking loss based on weighting the pairwise loss between candidates by the expected regret incurred for misordering the pair. We demonstrate that the proposed method can outperform prior methods both in a simulated environment and in a production experiment on a major social network.
Implicit Distributional Reinforcement Learning
Jul 13, 2020
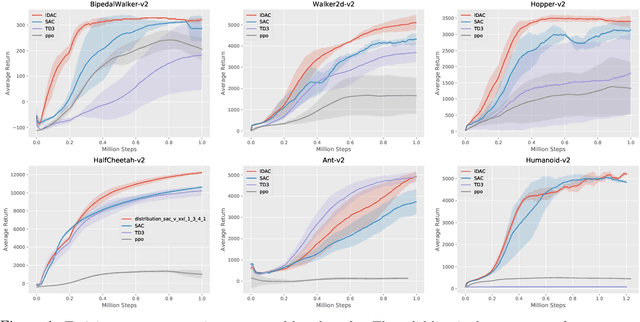
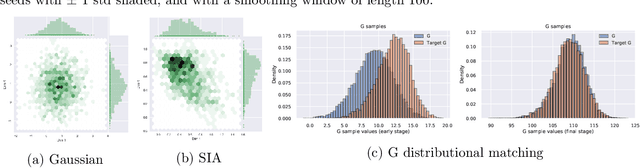

To improve the sample efficiency of policy-gradient based reinforcement learning algorithms, we propose implicit distributional actor critic (IDAC) that consists of a distributional critic, built on two deep generator networks (DGNs), and a semi-implicit actor (SIA), powered by a flexible policy distribution. We adopt a distributional perspective on the discounted cumulative return and model it with a state-action-dependent implicit distribution, which is approximated by the DGNs that take state-action pairs and random noises as their input. Moreover, we use the SIA to provide a semi-implicit policy distribution, which mixes the policy parameters with a reparameterizable distribution that is not constrained by an analytic density function. In this way, the policy's marginal distribution is implicit, providing the potential to model complex properties such as covariance structure and skewness, but its parameter and entropy can still be estimated. We incorporate these features with an off-policy algorithm framework to solve problems with continuous action space, and compare IDAC with the state-of-art algorithms on representative OpenAI Gym environments. We observe that IDAC outperforms these baselines for most tasks.
Discrete Action On-Policy Learning with Action-Value Critic
Feb 21, 2020
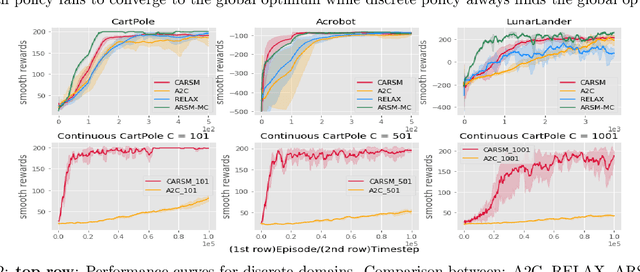


Reinforcement learning (RL) in discrete action space is ubiquitous in real-world applications, but its complexity grows exponentially with the action-space dimension, making it challenging to apply existing on-policy gradient based deep RL algorithms efficiently. To effectively operate in multidimensional discrete action spaces, we construct a critic to estimate action-value functions, apply it on correlated actions, and combine these critic estimated action values to control the variance of gradient estimation. We follow rigorous statistical analysis to design how to generate and combine these correlated actions, and how to sparsify the gradients by shutting down the contributions from certain dimensions. These efforts result in a new discrete action on-policy RL algorithm that empirically outperforms related on-policy algorithms relying on variance control techniques. We demonstrate these properties on OpenAI Gym benchmark tasks, and illustrate how discretizing the action space could benefit the exploration phase and hence facilitate convergence to a better local optimal solution thanks to the flexibility of discrete policy.
Semi-supervised Learning using Adversarial Training with Good and Bad Samples
Oct 18, 2019



In this work, we investigate semi-supervised learning (SSL) for image classification using adversarial training. Previous results have illustrated that generative adversarial networks (GANs) can be used for multiple purposes. Triple-GAN, which aims to jointly optimize model components by incorporating three players, generates suitable image-label pairs to compensate for the lack of labeled data in SSL with improved benchmark performance. Conversely, Bad (or complementary) GAN, optimizes generation to produce complementary data-label pairs and force a classifier's decision boundary to lie between data manifolds. Although it generally outperforms Triple-GAN, Bad GAN is highly sensitive to the amount of labeled data used for training. Unifying these two approaches, we present unified-GAN (UGAN), a novel framework that enables a classifier to simultaneously learn from both good and bad samples through adversarial training. We perform extensive experiments on various datasets and demonstrate that UGAN: 1) achieves state-of-the-art performance among other deep generative models, and 2) is robust to variations in the amount of labeled data used for training.
A Unified Framework for Tuning Hyperparameters in Clustering Problems
Oct 17, 2019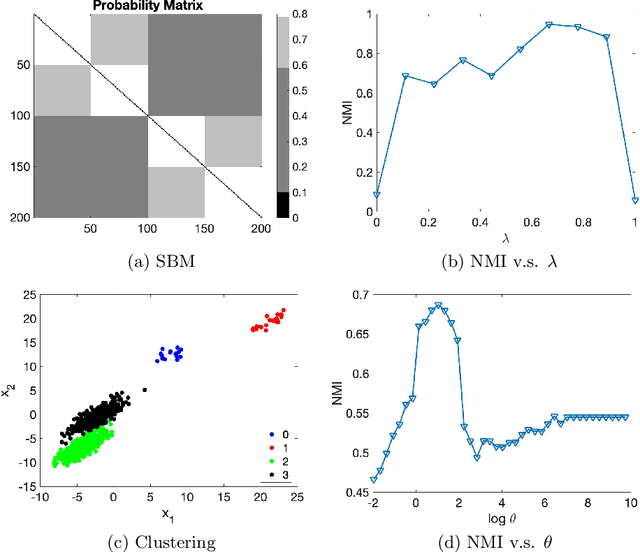
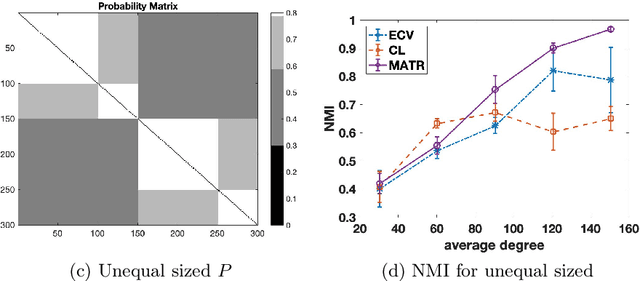
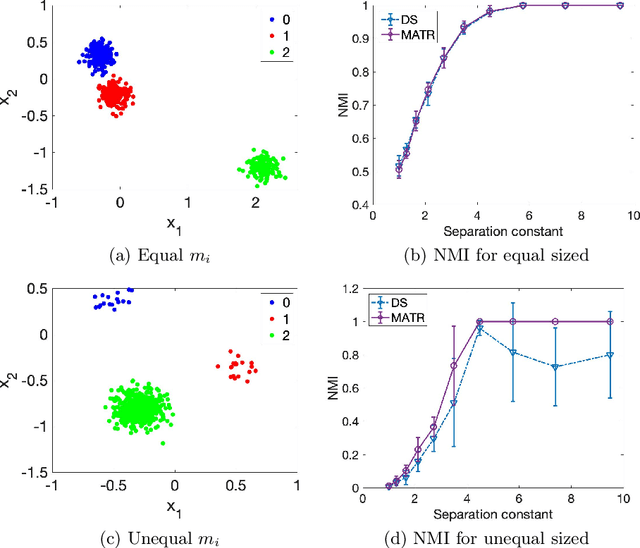
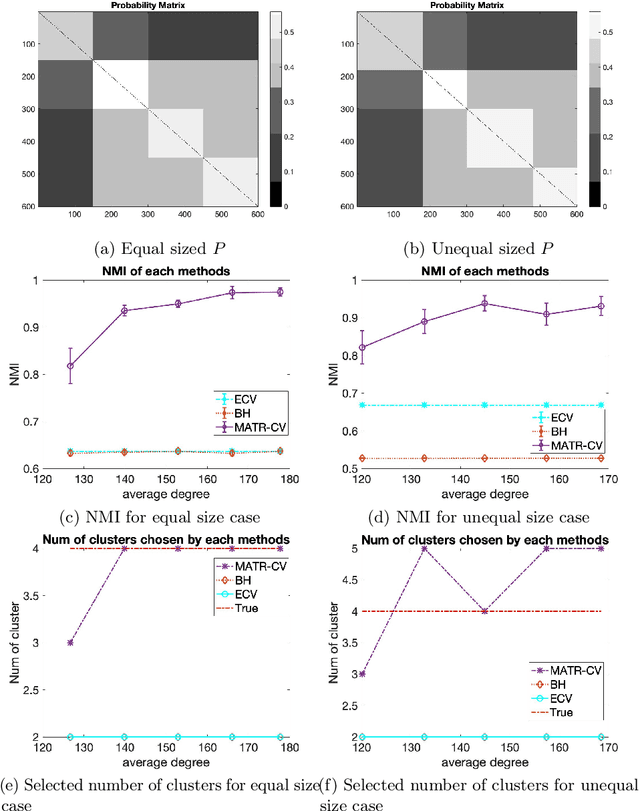
Selecting hyperparameters for unsupervised learning problems is difficult in general due to the lack of ground truth for validation. However, this issue is prevalent in machine learning, especially in clustering problems with examples including the Lagrange multipliers of penalty terms in semidefinite programming (SDP) relaxations and the bandwidths used for constructing kernel similarity matrices for Spectral Clustering. Despite this, there are not many provable algorithms for tuning these hyperparameters. In this paper, we provide a unified framework with provable guarantees for the above class of problems. We demonstrate our method on two distinct models. First, we show how to tune the hyperparameters in widely used SDP algorithms for community detection in networks. In this case, our method can also be used for model selection. Second, we show the same framework works for choosing the bandwidth for the kernel similarity matrix in Spectral Clustering for subgaussian mixtures under suitable model specification. In a variety of simulation experiments, we show that our framework outperforms other widely used tuning procedures in a broad range of parameter settings.
ARSM: Augment-REINFORCE-Swap-Merge Estimator for Gradient Backpropagation Through Categorical Variables
May 04, 2019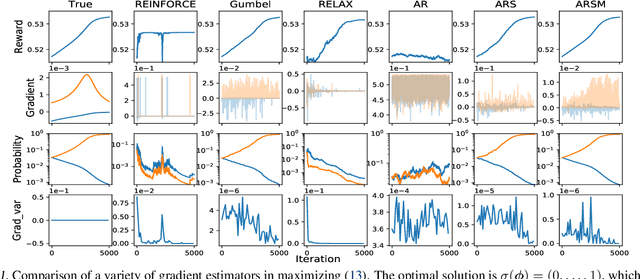

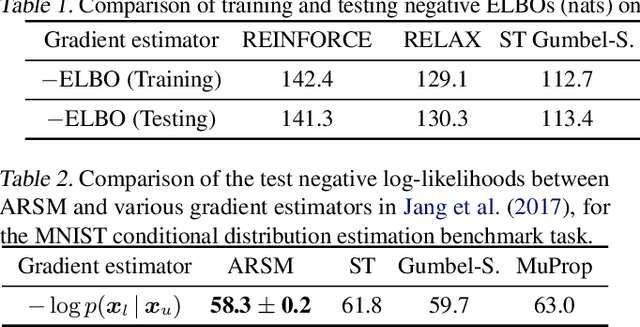
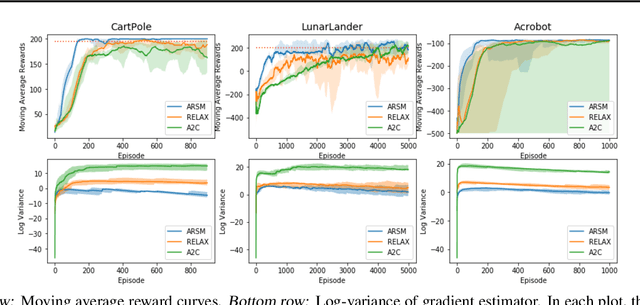
To address the challenge of backpropagating the gradient through categorical variables, we propose the augment-REINFORCE-swap-merge (ARSM) gradient estimator that is unbiased and has low variance. ARSM first uses variable augmentation, REINFORCE, and Rao-Blackwellization to re-express the gradient as an expectation under the Dirichlet distribution, then uses variable swapping to construct differently expressed but equivalent expectations, and finally shares common random numbers between these expectations to achieve significant variance reduction. Experimental results show ARSM closely resembles the performance of the true gradient for optimization in univariate settings; outperforms existing estimators by a large margin when applied to categorical variational auto-encoders; and provides a "try-and-see self-critic" variance reduction method for discrete-action policy gradient, which removes the need of estimating baselines by generating a random number of pseudo actions and estimating their action-value functions.