 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrdinal Preference Optimization: Aligning Human Preferences via NDCG
Oct 06, 2024Aligning Large Language Models (LLMs) with diverse human preferences is a pivotal technique for controlling model behaviors and enhancing generation quality. Reinforcement Learning from Human Feedback (RLHF), Direct Preference Optimization (DPO), and their variants optimize language models by pairwise comparisons. However, when multiple responses are available, these approaches fall short of leveraging the extensive information in the ranking given by the reward models or human feedback. In this work, we propose a novel listwise approach named Ordinal Preference Optimization (OPO), which employs the Normalized Discounted Cumulative Gain (NDCG), a widely-used ranking metric, to better utilize relative proximity within ordinal multiple responses. We develop an end-to-end preference optimization algorithm by approximating NDCG with a differentiable surrogate loss. This approach builds a connection between ranking models in information retrieval and the alignment problem. In aligning multi-response datasets assigned with ordinal rewards, OPO outperforms existing pairwise and listwise approaches on evaluation sets and general benchmarks like AlpacaEval. Moreover, we demonstrate that increasing the pool of negative samples can enhance model performance by reducing the adverse effects of trivial negatives.
Adjusting Regression Models for Conditional Uncertainty Calibration
Sep 26, 2024Conformal Prediction methods have finite-sample distribution-free marginal coverage guarantees. However, they generally do not offer conditional coverage guarantees, which can be important for high-stakes decisions. In this paper, we propose a novel algorithm to train a regression function to improve the conditional coverage after applying the split conformal prediction procedure. We establish an upper bound for the miscoverage gap between the conditional coverage and the nominal coverage rate and propose an end-to-end algorithm to control this upper bound. We demonstrate the efficacy of our method empirically on synthetic and real-world datasets.
Score identity Distillation: Exponentially Fast Distillation of Pretrained Diffusion Models for One-Step Generation
Apr 05, 2024

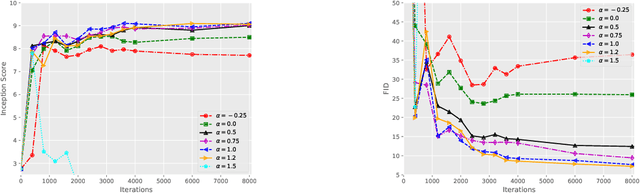
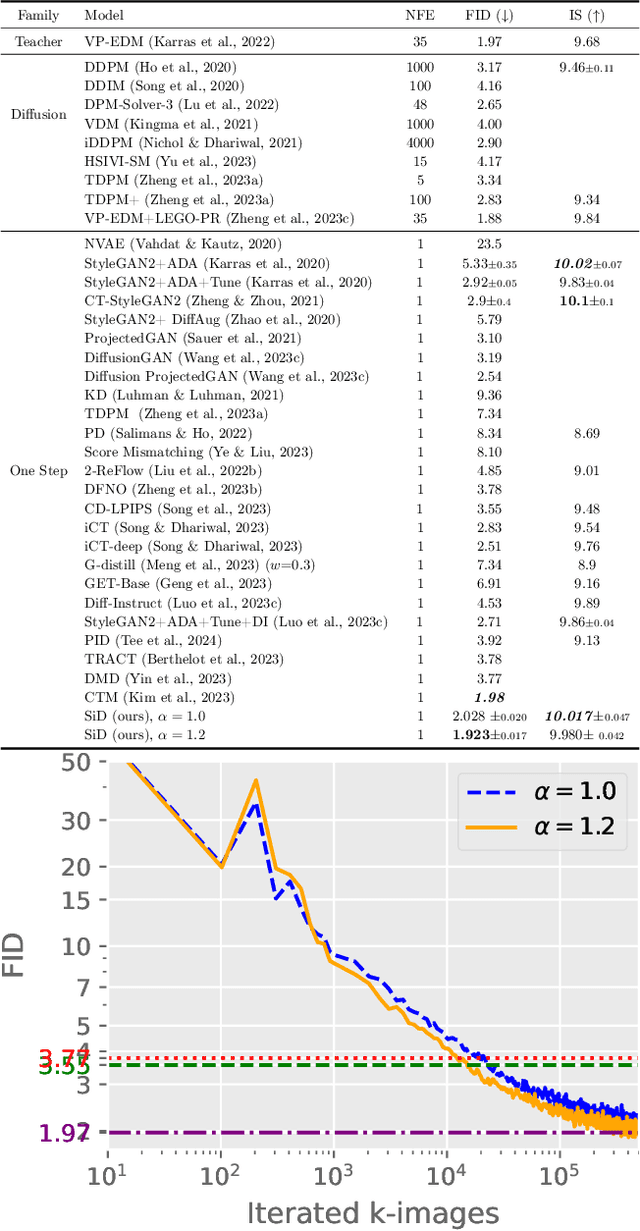
We introduce Score identity Distillation (SiD), an innovative data-free method that distills the generative capabilities of pretrained diffusion models into a single-step generator. SiD not only facilitates an exponentially fast reduction in Fr\'echet inception distance (FID) during distillation but also approaches or even exceeds the FID performance of the original teacher diffusion models. By reformulating forward diffusion processes as semi-implicit distributions, we leverage three score-related identities to create an innovative loss mechanism. This mechanism achieves rapid FID reduction by training the generator using its own synthesized images, eliminating the need for real data or reverse-diffusion-based generation, all accomplished within significantly shortened generation time. Upon evaluation across four benchmark datasets, the SiD algorithm demonstrates high iteration efficiency during distillation and surpasses competing distillation approaches, whether they are one-step or few-step, data-free, or dependent on training data, in terms of generation quality. This achievement not only redefines the benchmarks for efficiency and effectiveness in diffusion distillation but also in the broader field of diffusion-based generation. Our PyTorch implementation will be publicly accessible on GitHub.
Nonparametric Discrete Choice Experiments with Machine Learning Guided Adaptive Design
Oct 18, 2023Designing products to meet consumers' preferences is essential for a business's success. We propose the Gradient-based Survey (GBS), a discrete choice experiment for multiattribute product design. The experiment elicits consumer preferences through a sequence of paired comparisons for partial profiles. GBS adaptively constructs paired comparison questions based on the respondents' previous choices. Unlike the traditional random utility maximization paradigm, GBS is robust to model misspecification by not requiring a parametric utility model. Cross-pollinating the machine learning and experiment design, GBS is scalable to products with hundreds of attributes and can design personalized products for heterogeneous consumers. We demonstrate the advantage of GBS in accuracy and sample efficiency compared to the existing parametric and nonparametric methods in simulations.
Confounding-Robust Policy Improvement with Human-AI Teams
Oct 13, 2023Human-AI collaboration has the potential to transform various domains by leveraging the complementary strengths of human experts and Artificial Intelligence (AI) systems. However, unobserved confounding can undermine the effectiveness of this collaboration, leading to biased and unreliable outcomes. In this paper, we propose a novel solution to address unobserved confounding in human-AI collaboration by employing the marginal sensitivity model (MSM). Our approach combines domain expertise with AI-driven statistical modeling to account for potential confounders that may otherwise remain hidden. We present a deferral collaboration framework for incorporating the MSM into policy learning from observational data, enabling the system to control for the influence of unobserved confounding factors. In addition, we propose a personalized deferral collaboration system to leverage the diverse expertise of different human decision-makers. By adjusting for potential biases, our proposed solution enhances the robustness and reliability of collaborative outcomes. The empirical and theoretical analyses demonstrate the efficacy of our approach in mitigating unobserved confounding and improving the overall performance of human-AI collaborations.
Gradient Estimation for Binary Latent Variables via Gradient Variance Clipping
Aug 12, 2022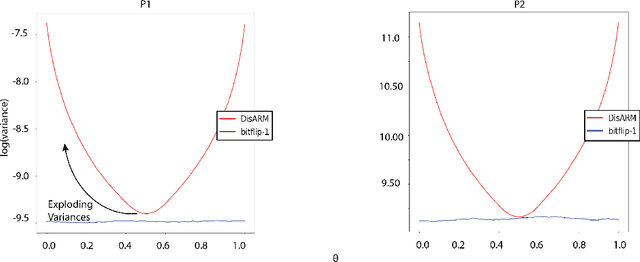
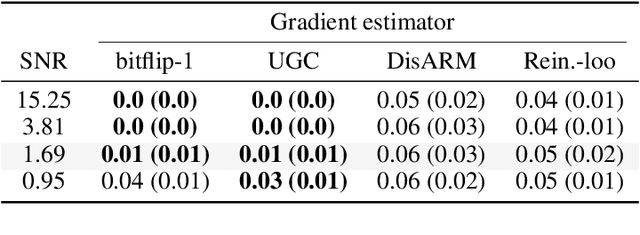
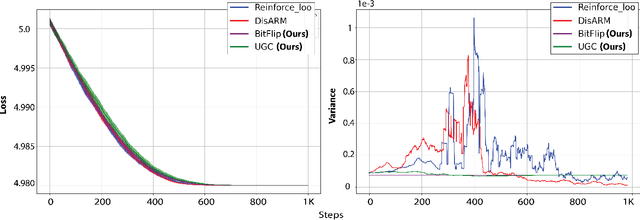
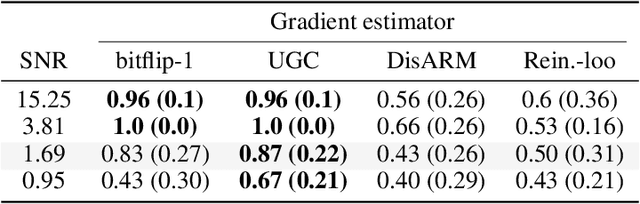
Gradient estimation is often necessary for fitting generative models with discrete latent variables, in contexts such as reinforcement learning and variational autoencoder (VAE) training. The DisARM estimator (Yin et al. 2020; Dong, Mnih, and Tucker 2020) achieves state of the art gradient variance for Bernoulli latent variable models in many contexts. However, DisARM and other estimators have potentially exploding variance near the boundary of the parameter space, where solutions tend to lie. To ameliorate this issue, we propose a new gradient estimator \textit{bitflip}-1 that has lower variance at the boundaries of the parameter space. As bitflip-1 has complementary properties to existing estimators, we introduce an aggregated estimator, \textit{unbiased gradient variance clipping} (UGC) that uses either a bitflip-1 or a DisARM gradient update for each coordinate. We theoretically prove that UGC has uniformly lower variance than DisARM. Empirically, we observe that UGC achieves the optimal value of the optimization objectives in toy experiments, discrete VAE training, and in a best subset selection problem.
Probabilistic Conformal Prediction Using Conditional Random Samples
Jun 20, 2022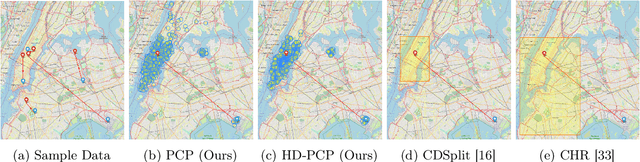
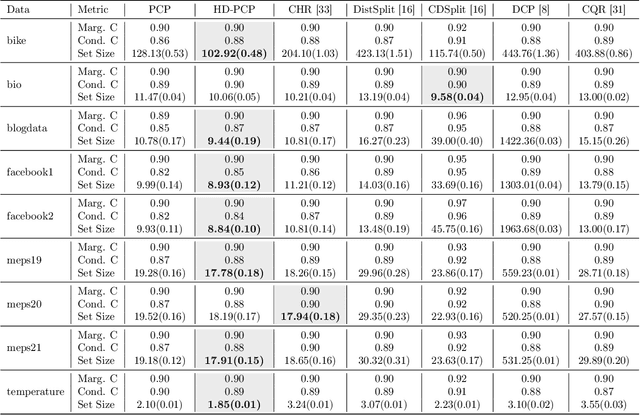
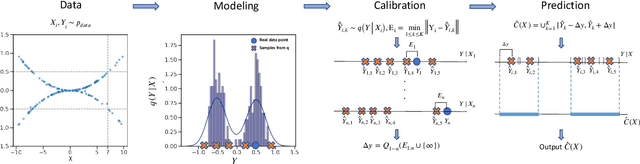

This paper proposes probabilistic conformal prediction (PCP), a predictive inference algorithm that estimates a target variable by a discontinuous predictive set. Given inputs, PCP construct the predictive set based on random samples from an estimated generative model. It is efficient and compatible with either explicit or implicit conditional generative models. Theoretically, we show that PCP guarantees correct marginal coverage with finite samples. Empirically, we study PCP on a variety of simulated and real datasets. Compared to existing methods for conformal inference, PCP provides sharper predictive sets.
Partial Identification with Noisy Covariates: A Robust Optimization Approach
Feb 22, 2022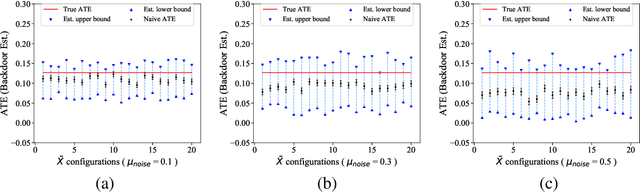
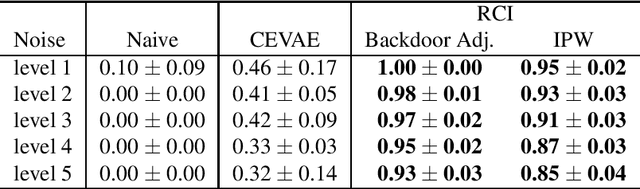

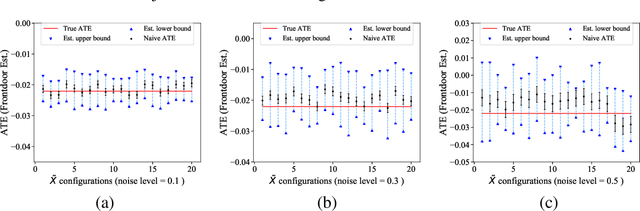
Causal inference from observational datasets often relies on measuring and adjusting for covariates. In practice, measurements of the covariates can often be noisy and/or biased, or only measurements of their proxies may be available. Directly adjusting for these imperfect measurements of the covariates can lead to biased causal estimates. Moreover, without additional assumptions, the causal effects are not point-identifiable due to the noise in these measurements. To this end, we study the partial identification of causal effects given noisy covariates, under a user-specified assumption on the noise level. The key observation is that we can formulate the identification of the average treatment effects (ATE) as a robust optimization problem. This formulation leads to an efficient robust optimization algorithm that bounds the ATE with noisy covariates. We show that this robust optimization approach can extend a wide range of causal adjustment methods to perform partial identification, including backdoor adjustment, inverse propensity score weighting, double machine learning, and front door adjustment. Across synthetic and real datasets, we find that this approach provides ATE bounds with a higher coverage probability than existing methods.
Optimization-based Causal Estimation from Heterogenous Environments
Sep 24, 2021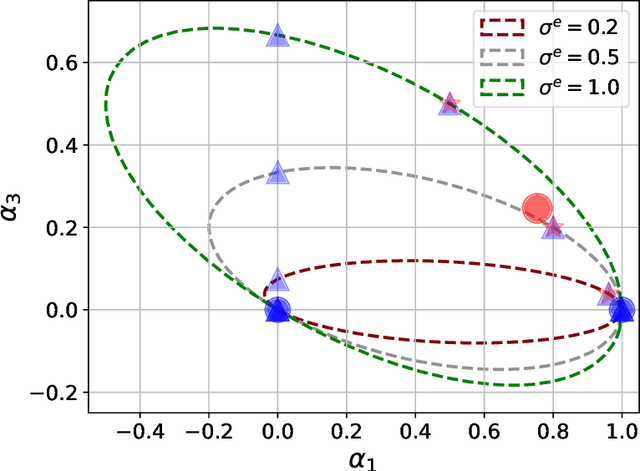

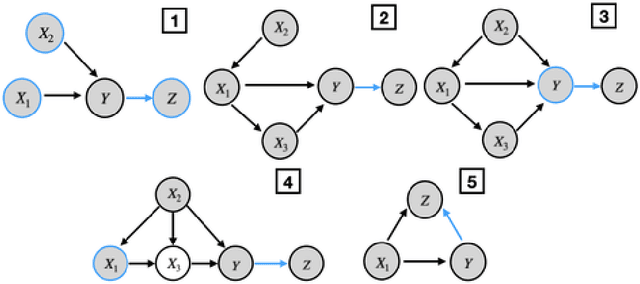

This paper presents a new optimization approach to causal estimation. Given data that contains covariates and an outcome, which covariates are causes of the outcome, and what is the strength of the causality? In classical machine learning (ML), the goal of optimization is to maximize predictive accuracy. However, some covariates might exhibit a non-causal association to the outcome. Such spurious associations provide predictive power for classical ML, but they prevent us from causally interpreting the result. This paper proposes CoCo, an optimization algorithm that bridges the gap between pure prediction and causal inference. CoCo leverages the recently-proposed idea of environments, datasets of covariates/response where the causal relationships remain invariant but where the distribution of the covariates changes from environment to environment. Given datasets from multiple environments -- and ones that exhibit sufficient heterogeneity -- CoCo maximizes an objective for which the only solution is the causal solution. We describe the theoretical foundations of this approach and demonstrate its effectiveness on simulated and real datasets. Compared to classical ML and existing methods, CoCo provides more accurate estimates of the causal model.
Pairwise Supervised Hashing with Bernoulli Variational Auto-Encoder and Self-Control Gradient Estimator
May 21, 2020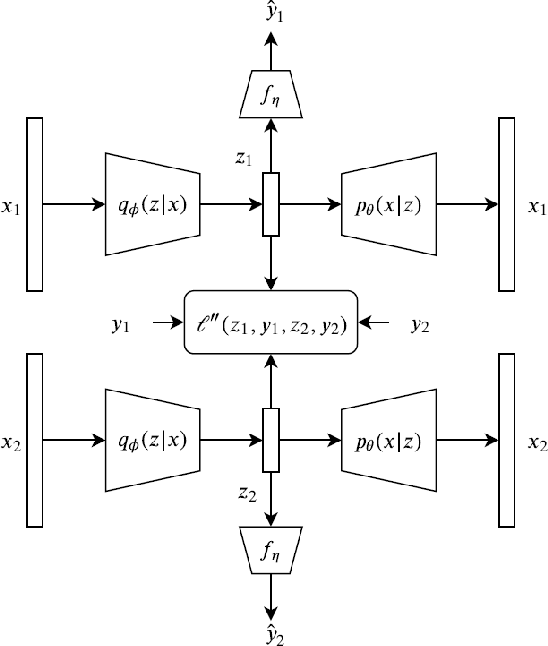
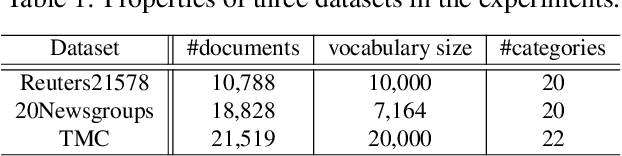
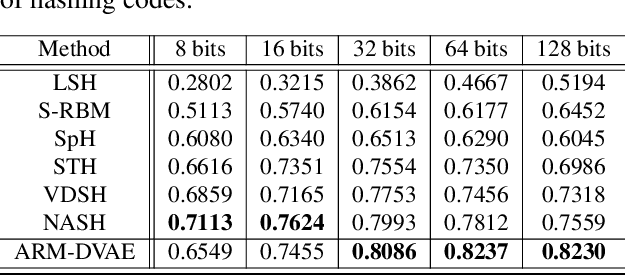
Semantic hashing has become a crucial component of fast similarity search in many large-scale information retrieval systems, in particular, for text data. Variational auto-encoders (VAEs) with binary latent variables as hashing codes provide state-of-the-art performance in terms of precision for document retrieval. We propose a pairwise loss function with discrete latent VAE to reward within-class similarity and between-class dissimilarity for supervised hashing. Instead of solving the optimization relying on existing biased gradient estimators, an unbiased low-variance gradient estimator is adopted to optimize the hashing function by evaluating the non-differentiable loss function over two correlated sets of binary hashing codes to control the variance of gradient estimates. This new semantic hashing framework achieves superior performance compared to the state-of-the-arts, as demonstrated by our comprehensive experiments.
* To appear in UAI 2020