 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbarrassingly Simple Self-Distillation Improves Code Generation
Apr 01, 2026Can a large language model (LLM) improve at code generation using only its own raw outputs, without a verifier, a teacher model, or reinforcement learning? We answer in the affirmative with simple self-distillation (SSD): sample solutions from the model with certain temperature and truncation configurations, then fine-tune on those samples with standard supervised fine-tuning. SSD improves Qwen3-30B-Instruct from 42.4% to 55.3% pass@1 on LiveCodeBench v6, with gains concentrating on harder problems, and it generalizes across Qwen and Llama models at 4B, 8B, and 30B scale, including both instruct and thinking variants. To understand why such a simple method can work, we trace these gains to a precision-exploration conflict in LLM decoding and show that SSD reshapes token distributions in a context-dependent way, suppressing distractor tails where precision matters while preserving useful diversity where exploration matters. Taken together, SSD offers a complementary post-training direction for improving LLM code generation.
Rejection Mixing: Fast Semantic Propagation of Mask Tokens for Efficient DLLM Inference
Feb 26, 2026Diffusion Large Language Models (DLLMs) promise fast non-autoregressive inference but suffer a severe quality-speed trade-off in parallel decoding. This stems from the ''combinatorial contradiction'' phenomenon, where parallel tokens form semantically inconsistent combinations. We address this by integrating continuous representations into the discrete decoding process, as they preserve rich inter-position dependency. We propose ReMix (Rejection Mixing), a framework that introduces a novel Continuous Mixing State as an intermediate between the initial masked state and the final decoded token state. This intermediate state allows a token's representation to be iteratively refined in a continuous space, resolving mutual conflicts with other tokens before collapsing into a final discrete sample. Furthermore, a rejection rule reverts uncertain representations from the continuous state back to the masked state for reprocessing, ensuring stability and preventing error propagation. ReMix thus mitigates combinatorial contradictions by enabling continuous-space refinement during discrete diffusion decoding. Extensive experiments demonstrate that ReMix, as a training-free method, achieves a $2-8 \times$ inference speedup without any quality degradation.
Wide-In, Narrow-Out: Revokable Decoding for Efficient and Effective DLLMs
Jul 24, 2025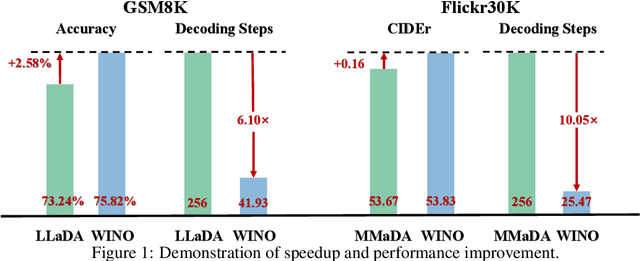
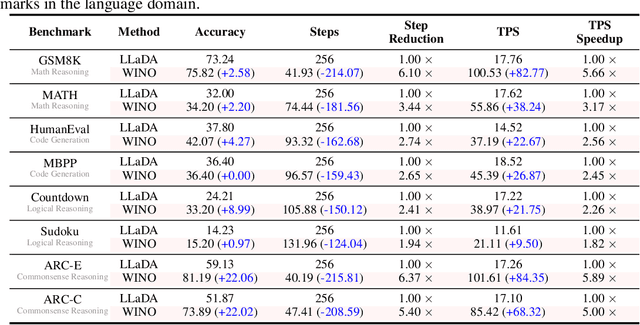
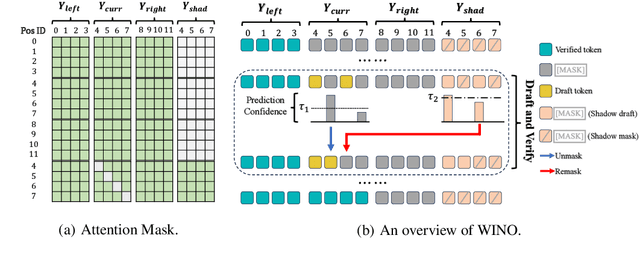
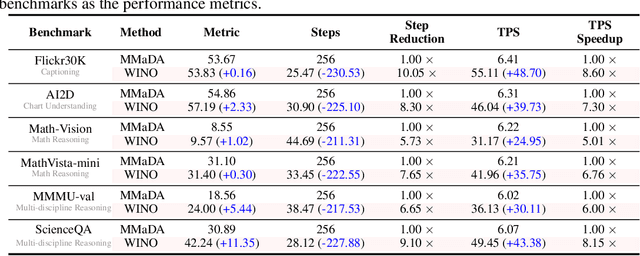
Diffusion Large Language Models (DLLMs) have emerged as a compelling alternative to Autoregressive models, designed for fast parallel generation. However, existing DLLMs are plagued by a severe quality-speed trade-off, where faster parallel decoding leads to significant performance degradation. We attribute this to the irreversibility of standard decoding in DLLMs, which is easily polarized into the wrong decoding direction along with early error context accumulation. To resolve this, we introduce Wide-In, Narrow-Out (WINO), a training-free decoding algorithm that enables revokable decoding in DLLMs. WINO employs a parallel draft-and-verify mechanism, aggressively drafting multiple tokens while simultaneously using the model's bidirectional context to verify and re-mask suspicious ones for refinement. Verified in open-source DLLMs like LLaDA and MMaDA, WINO is shown to decisively improve the quality-speed trade-off. For instance, on the GSM8K math benchmark, it accelerates inference by 6$\times$ while improving accuracy by 2.58%; on Flickr30K captioning, it achieves a 10$\times$ speedup with higher performance. More comprehensive experiments are conducted to demonstrate the superiority and provide an in-depth understanding of WINO.
DiffuCoder: Understanding and Improving Masked Diffusion Models for Code Generation
Jun 26, 2025Diffusion large language models (dLLMs) are compelling alternatives to autoregressive (AR) models because their denoising models operate over the entire sequence. The global planning and iterative refinement features of dLLMs are particularly useful for code generation. However, current training and inference mechanisms for dLLMs in coding are still under-explored. To demystify the decoding behavior of dLLMs and unlock their potential for coding, we systematically investigate their denoising processes and reinforcement learning (RL) methods. We train a 7B dLLM, \textbf{DiffuCoder}, on 130B tokens of code. Using this model as a testbed, we analyze its decoding behavior, revealing how it differs from that of AR models: (1) dLLMs can decide how causal their generation should be without relying on semi-AR decoding, and (2) increasing the sampling temperature diversifies not only token choices but also their generation order. This diversity creates a rich search space for RL rollouts. For RL training, to reduce the variance of token log-likelihood estimates and maintain training efficiency, we propose \textbf{coupled-GRPO}, a novel sampling scheme that constructs complementary mask noise for completions used in training. In our experiments, coupled-GRPO significantly improves DiffuCoder's performance on code generation benchmarks (+4.4\% on EvalPlus) and reduces reliance on AR bias during decoding. Our work provides deeper insight into the machinery of dLLM generation and offers an effective, diffusion-native RL training framework. https://github.com/apple/ml-diffucoder.
STARFlow: Scaling Latent Normalizing Flows for High-resolution Image Synthesis
Jun 06, 2025
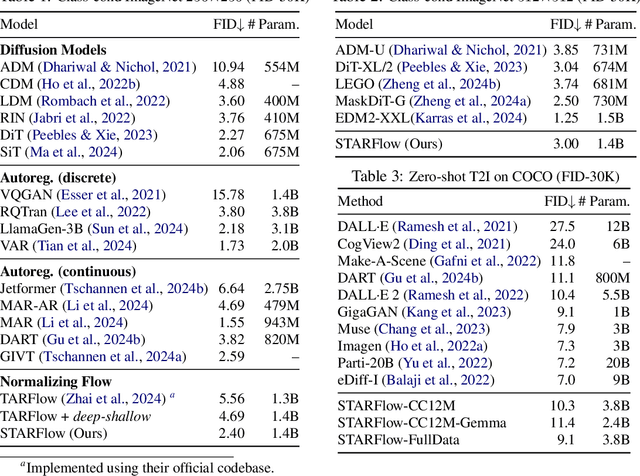
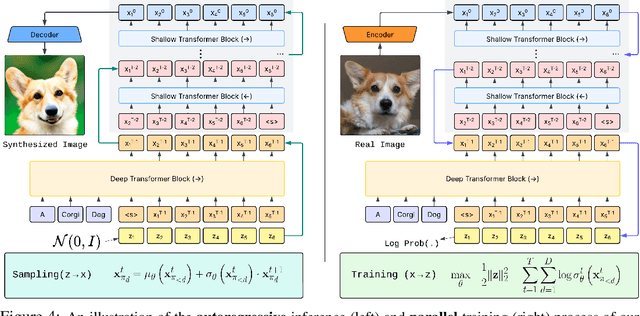
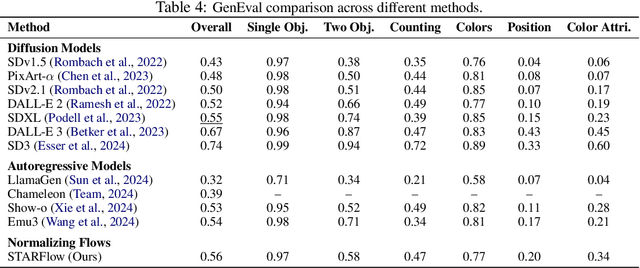
We present STARFlow, a scalable generative model based on normalizing flows that achieves strong performance in high-resolution image synthesis. The core of STARFlow is Transformer Autoregressive Flow (TARFlow), which combines the expressive power of normalizing flows with the structured modeling capabilities of Autoregressive Transformers. We first establish the theoretical universality of TARFlow for modeling continuous distributions. Building on this foundation, we introduce several key architectural and algorithmic innovations to significantly enhance scalability: (1) a deep-shallow design, wherein a deep Transformer block captures most of the model representational capacity, complemented by a few shallow Transformer blocks that are computationally efficient yet substantially beneficial; (2) modeling in the latent space of pretrained autoencoders, which proves more effective than direct pixel-level modeling; and (3) a novel guidance algorithm that significantly boosts sample quality. Crucially, our model remains an end-to-end normalizing flow, enabling exact maximum likelihood training in continuous spaces without discretization. STARFlow achieves competitive performance in both class-conditional and text-conditional image generation tasks, approaching state-of-the-art diffusion models in sample quality. To our knowledge, this work is the first successful demonstration of normalizing flows operating effectively at this scale and resolution.
Normalizing Flows are Capable Generative Models
Dec 10, 2024Normalizing Flows (NFs) are likelihood-based models for continuous inputs. They have demonstrated promising results on both density estimation and generative modeling tasks, but have received relatively little attention in recent years. In this work, we demonstrate that NFs are more powerful than previously believed. We present TarFlow: a simple and scalable architecture that enables highly performant NF models. TarFlow can be thought of as a Transformer-based variant of Masked Autoregressive Flows (MAFs): it consists of a stack of autoregressive Transformer blocks on image patches, alternating the autoregression direction between layers. TarFlow is straightforward to train end-to-end, and capable of directly modeling and generating pixels. We also propose three key techniques to improve sample quality: Gaussian noise augmentation during training, a post training denoising procedure, and an effective guidance method for both class-conditional and unconditional settings. Putting these together, TarFlow sets new state-of-the-art results on likelihood estimation for images, beating the previous best methods by a large margin, and generates samples with quality and diversity comparable to diffusion models, for the first time with a stand-alone NF model. We make our code available at https://github.com/apple/ml-tarflow.
Adversarial Score identity Distillation: Rapidly Surpassing the Teacher in One Step
Oct 19, 2024



Score identity Distillation (SiD) is a data-free method that has achieved state-of-the-art performance in image generation by leveraging only a pretrained diffusion model, without requiring any training data. However, the ultimate performance of SiD is constrained by the accuracy with which the pretrained model captures the true data scores at different stages of the diffusion process. In this paper, we introduce SiDA (SiD with Adversarial Loss), which not only enhances generation quality but also improves distillation efficiency by incorporating real images and adversarial loss. SiDA utilizes the encoder from the generator's score network as a discriminator, boosting its ability to distinguish between real images and those generated by SiD. The adversarial loss is batch-normalized within each GPU and then combined with the original SiD loss. This integration effectively incorporates the average "fakeness" per GPU batch into the pixel-based SiD loss, enabling SiDA to distill a single-step generator either from scratch or by fine-tuning an existing one. SiDA converges significantly faster than its predecessor when trained from scratch, and swiftly improves upon the original model's performance after an initial warmup period during fine-tuning from a pre-distilled SiD generator. This one-step adversarial distillation method has set new benchmarks for generation performance when distilling EDM diffusion models pretrained on CIFAR-10 (32x32) and ImageNet (64x64), achieving FID scores of $\mathbf{1.499}$ on CIFAR-10 unconditional, $\mathbf{1.396}$ on CIFAR-10 conditional, and $\mathbf{1.110}$ on ImageNet 64x64. Our open-source code will be integrated into the SiD codebase on GitHub.
What If We Recaption Billions of Web Images with LLaMA-3?
Jun 12, 2024



Web-crawled image-text pairs are inherently noisy. Prior studies demonstrate that semantically aligning and enriching textual descriptions of these pairs can significantly enhance model training across various vision-language tasks, particularly text-to-image generation. However, large-scale investigations in this area remain predominantly closed-source. Our paper aims to bridge this community effort, leveraging the powerful and \textit{open-sourced} LLaMA-3, a GPT-4 level LLM. Our recaptioning pipeline is simple: first, we fine-tune a LLaMA-3-8B powered LLaVA-1.5 and then employ it to recaption 1.3 billion images from the DataComp-1B dataset. Our empirical results confirm that this enhanced dataset, Recap-DataComp-1B, offers substantial benefits in training advanced vision-language models. For discriminative models like CLIP, we observe enhanced zero-shot performance in cross-modal retrieval tasks. For generative models like text-to-image Diffusion Transformers, the generated images exhibit a significant improvement in alignment with users' text instructions, especially in following complex queries. Our project page is https://www.haqtu.me/Recap-Datacomp-1B/
Long and Short Guidance in Score identity Distillation for One-Step Text-to-Image Generation
Jun 03, 2024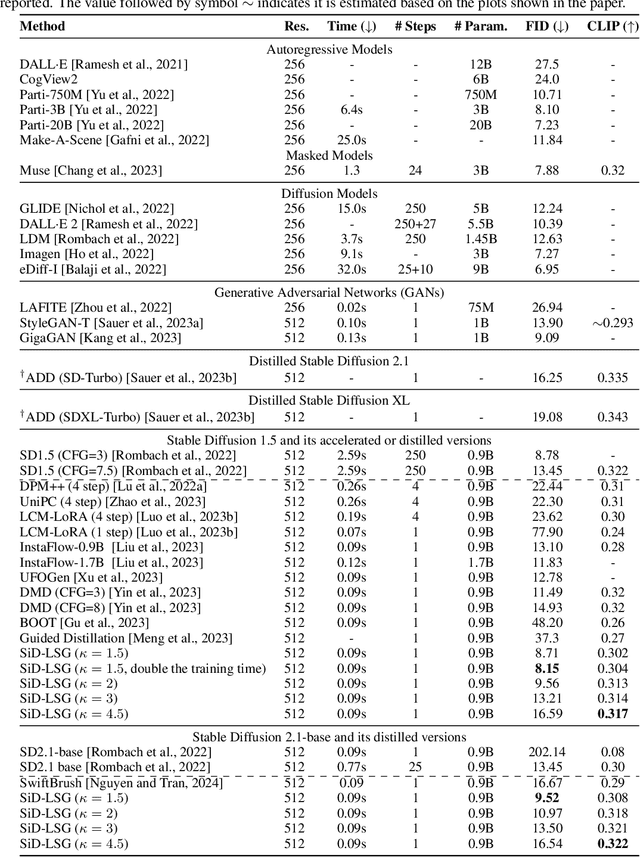

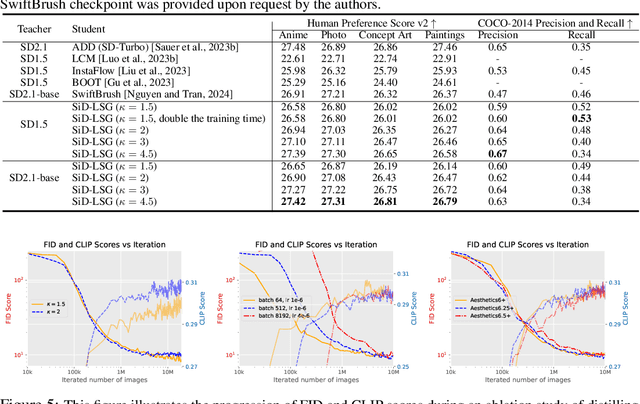
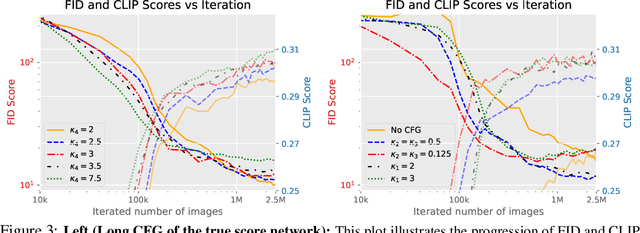
Diffusion-based text-to-image generation models trained on extensive text-image pairs have shown the capacity to generate photorealistic images consistent with textual descriptions. However, a significant limitation of these models is their slow sample generation, which requires iterative refinement through the same network. In this paper, we enhance Score identity Distillation (SiD) by developing long and short classifier-free guidance (LSG) to efficiently distill pretrained Stable Diffusion models without using real training data. SiD aims to optimize a model-based explicit score matching loss, utilizing a score-identity-based approximation alongside the proposed LSG for practical computation. By training exclusively with fake images synthesized with its one-step generator, SiD equipped with LSG rapidly improves FID and CLIP scores, achieving state-of-the-art FID performance while maintaining a competitive CLIP score. Specifically, its data-free distillation of Stable Diffusion 1.5 achieves a record low FID of 8.15 on the COCO-2014 validation set, with a CLIP score of 0.304 at an LSG scale of 1.5, and a FID of 9.56 with a CLIP score of 0.313 at an LSG scale of 2. We will make our PyTorch implementation and distilled Stable Diffusion one-step generators available at https://github.com/mingyuanzhou/SiD-LSG
Score identity Distillation: Exponentially Fast Distillation of Pretrained Diffusion Models for One-Step Generation
Apr 05, 2024

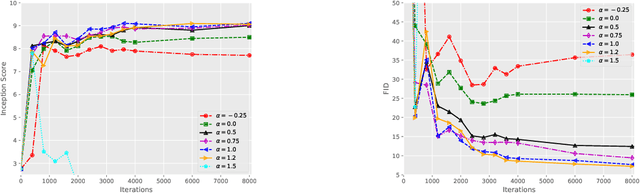
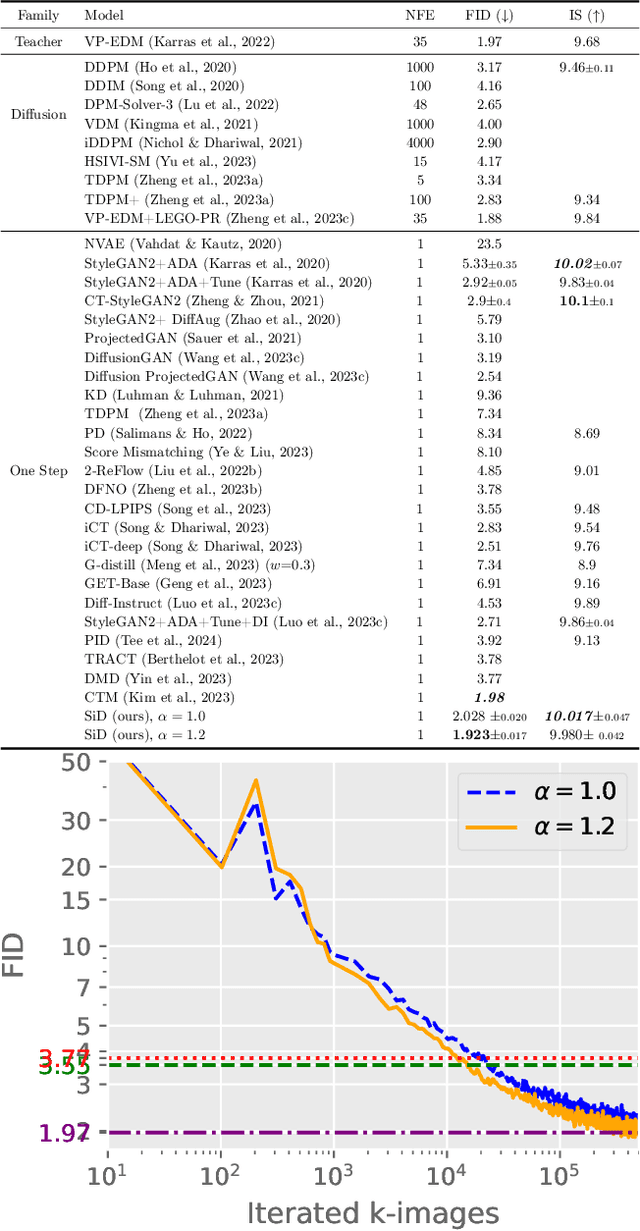
We introduce Score identity Distillation (SiD), an innovative data-free method that distills the generative capabilities of pretrained diffusion models into a single-step generator. SiD not only facilitates an exponentially fast reduction in Fr\'echet inception distance (FID) during distillation but also approaches or even exceeds the FID performance of the original teacher diffusion models. By reformulating forward diffusion processes as semi-implicit distributions, we leverage three score-related identities to create an innovative loss mechanism. This mechanism achieves rapid FID reduction by training the generator using its own synthesized images, eliminating the need for real data or reverse-diffusion-based generation, all accomplished within significantly shortened generation time. Upon evaluation across four benchmark datasets, the SiD algorithm demonstrates high iteration efficiency during distillation and surpasses competing distillation approaches, whether they are one-step or few-step, data-free, or dependent on training data, in terms of generation quality. This achievement not only redefines the benchmarks for efficiency and effectiveness in diffusion distillation but also in the broader field of diffusion-based generation. Our PyTorch implementation will be publicly accessible on GitHub.