 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTARFlow: Scaling Latent Normalizing Flows for High-resolution Image Synthesis
Jun 06, 2025
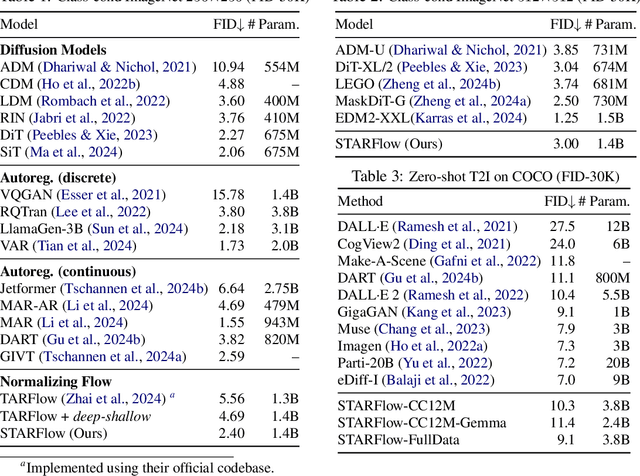
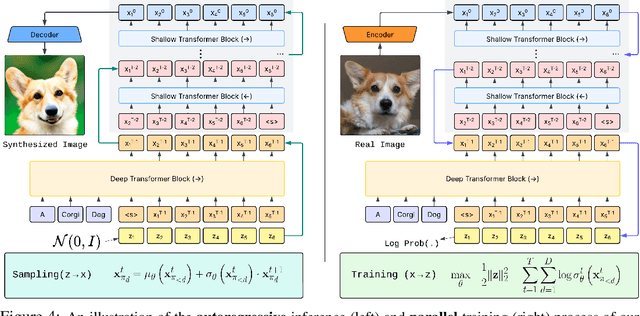
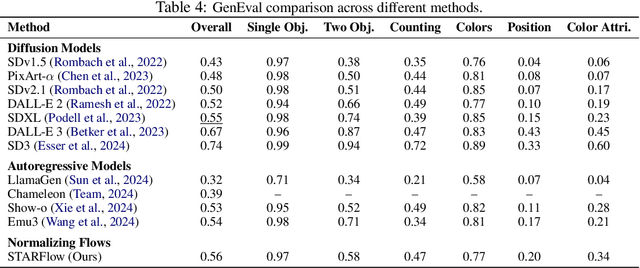
We present STARFlow, a scalable generative model based on normalizing flows that achieves strong performance in high-resolution image synthesis. The core of STARFlow is Transformer Autoregressive Flow (TARFlow), which combines the expressive power of normalizing flows with the structured modeling capabilities of Autoregressive Transformers. We first establish the theoretical universality of TARFlow for modeling continuous distributions. Building on this foundation, we introduce several key architectural and algorithmic innovations to significantly enhance scalability: (1) a deep-shallow design, wherein a deep Transformer block captures most of the model representational capacity, complemented by a few shallow Transformer blocks that are computationally efficient yet substantially beneficial; (2) modeling in the latent space of pretrained autoencoders, which proves more effective than direct pixel-level modeling; and (3) a novel guidance algorithm that significantly boosts sample quality. Crucially, our model remains an end-to-end normalizing flow, enabling exact maximum likelihood training in continuous spaces without discretization. STARFlow achieves competitive performance in both class-conditional and text-conditional image generation tasks, approaching state-of-the-art diffusion models in sample quality. To our knowledge, this work is the first successful demonstration of normalizing flows operating effectively at this scale and resolution.
LiDAR: Sensing Linear Probing Performance in Joint Embedding SSL Architectures
Dec 07, 2023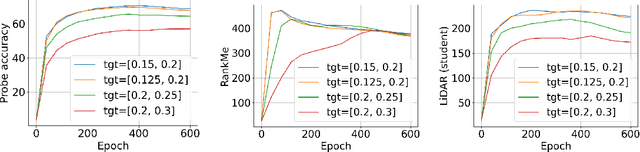
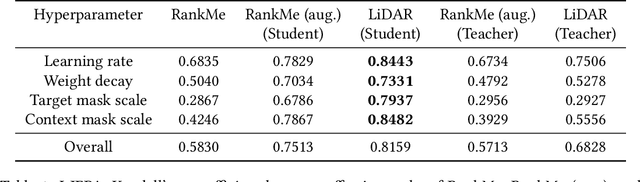

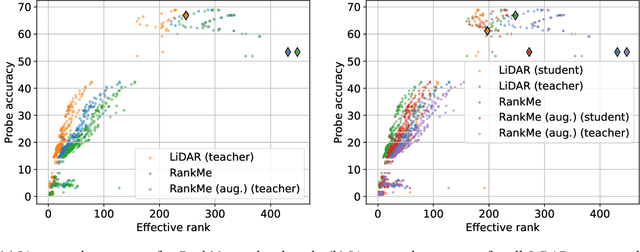
Joint embedding (JE) architectures have emerged as a promising avenue for acquiring transferable data representations. A key obstacle to using JE methods, however, is the inherent challenge of evaluating learned representations without access to a downstream task, and an annotated dataset. Without efficient and reliable evaluation, it is difficult to iterate on architectural and training choices for JE methods. In this paper, we introduce LiDAR (Linear Discriminant Analysis Rank), a metric designed to measure the quality of representations within JE architectures. Our metric addresses several shortcomings of recent approaches based on feature covariance rank by discriminating between informative and uninformative features. In essence, LiDAR quantifies the rank of the Linear Discriminant Analysis (LDA) matrix associated with the surrogate SSL task -- a measure that intuitively captures the information content as it pertains to solving the SSL task. We empirically demonstrate that LiDAR significantly surpasses naive rank based approaches in its predictive power of optimal hyperparameters. Our proposed criterion presents a more robust and intuitive means of assessing the quality of representations within JE architectures, which we hope facilitates broader adoption of these powerful techniques in various domains.
Adaptivity and Modularity for Efficient Generalization Over Task Complexity
Oct 13, 2023



Can transformers generalize efficiently on problems that require dealing with examples with different levels of difficulty? We introduce a new task tailored to assess generalization over different complexities and present results that indicate that standard transformers face challenges in solving these tasks. These tasks are variations of pointer value retrieval previously introduced by Zhang et al. (2021). We investigate how the use of a mechanism for adaptive and modular computation in transformers facilitates the learning of tasks that demand generalization over the number of sequential computation steps (i.e., the depth of the computation graph). Based on our observations, we propose a transformer-based architecture called Hyper-UT, which combines dynamic function generation from hyper networks with adaptive depth from Universal Transformers. This model demonstrates higher accuracy and a fairer allocation of computational resources when generalizing to higher numbers of computation steps. We conclude that mechanisms for adaptive depth and modularity complement each other in improving efficient generalization concerning example complexity. Additionally, to emphasize the broad applicability of our findings, we illustrate that in a standard image recognition task, Hyper- UT's performance matches that of a ViT model but with considerably reduced computational demands (achieving over 70\% average savings by effectively using fewer layers).
Generative Modeling with Phase Stochastic Bridges
Oct 13, 2023



Diffusion models (DMs) represent state-of-the-art generative models for continuous inputs. DMs work by constructing a Stochastic Differential Equation (SDE) in the input space (ie, position space), and using a neural network to reverse it. In this work, we introduce a novel generative modeling framework grounded in \textbf{phase space dynamics}, where a phase space is defined as {an augmented space encompassing both position and velocity.} Leveraging insights from Stochastic Optimal Control, we construct a path measure in the phase space that enables efficient sampling. {In contrast to DMs, our framework demonstrates the capability to generate realistic data points at an early stage of dynamics propagation.} This early prediction sets the stage for efficient data generation by leveraging additional velocity information along the trajectory. On standard image generation benchmarks, our model yields favorable performance over baselines in the regime of small Number of Function Evaluations (NFEs). Furthermore, our approach rivals the performance of diffusion models equipped with efficient sampling techniques, underscoring its potential as a new tool generative modeling.
GAUDI: A Neural Architect for Immersive 3D Scene Generation
Jul 27, 2022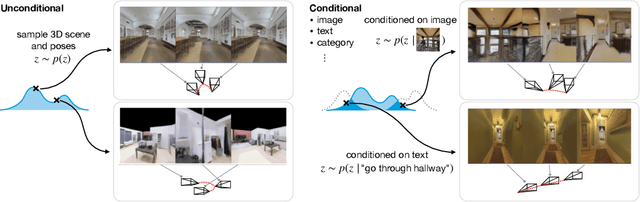
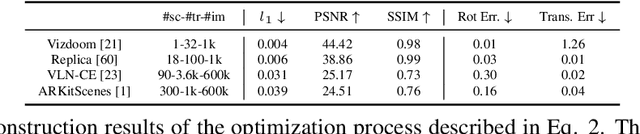
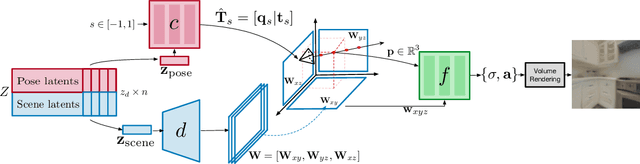

We introduce GAUDI, a generative model capable of capturing the distribution of complex and realistic 3D scenes that can be rendered immersively from a moving camera. We tackle this challenging problem with a scalable yet powerful approach, where we first optimize a latent representation that disentangles radiance fields and camera poses. This latent representation is then used to learn a generative model that enables both unconditional and conditional generation of 3D scenes. Our model generalizes previous works that focus on single objects by removing the assumption that the camera pose distribution can be shared across samples. We show that GAUDI obtains state-of-the-art performance in the unconditional generative setting across multiple datasets and allows for conditional generation of 3D scenes given conditioning variables like sparse image observations or text that describes the scene.
Perfect density models cannot guarantee anomaly detection
Dec 07, 2020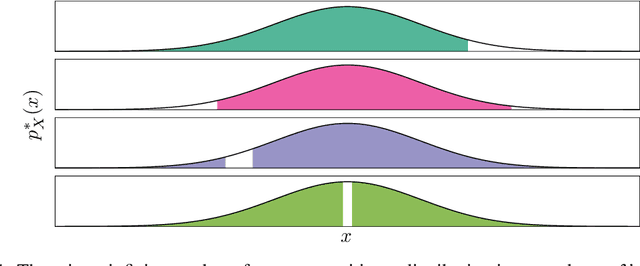



Thanks to the tractability of their likelihood, some deep generative models show promise for seemingly straightforward but important applications like anomaly detection, uncertainty estimation, and active learning. However, the likelihood values empirically attributed to anomalies conflict with the expectations these proposed applications suggest. In this paper, we take a closer look at the behavior of distribution densities and show that these quantities carry less meaningful information than previously thought, beyond estimation issues or the curse of dimensionality. We conclude that the use of these likelihoods for out-of-distribution detection relies on strong and implicit hypotheses, and highlight the necessity of explicitly formulating these assumptions for reliable anomaly detection.
Augmented Normalizing Flows: Bridging the Gap Between Generative Flows and Latent Variable Models
Feb 17, 2020



In this work, we propose a new family of generative flows on an augmented data space, with an aim to improve expressivity without drastically increasing the computational cost of sampling and evaluation of a lower bound on the likelihood. Theoretically, we prove the proposed flow can approximate a Hamiltonian ODE as a universal transport map. Empirically, we demonstrate state-of-the-art performance on standard benchmarks of flow-based generative modeling.
Discrete Flows: Invertible Generative Models of Discrete Data
May 24, 2019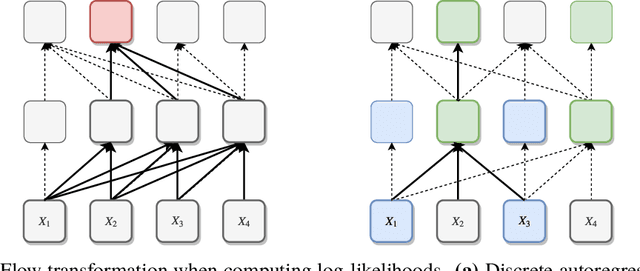

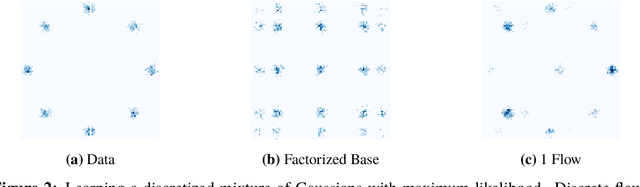

While normalizing flows have led to significant advances in modeling high-dimensional continuous distributions, their applicability to discrete distributions remains unknown. In this paper, we show that flows can in fact be extended to discrete events---and under a simple change-of-variables formula not requiring log-determinant-Jacobian computations. Discrete flows have numerous applications. We consider two flow architectures: discrete autoregressive flows that enable bidirectionality, allowing, for example, tokens in text to depend on both left-to-right and right-to-left contexts in an exact language model; and discrete bipartite flows that enable efficient non-autoregressive generation as in RealNVP. Empirically, we find that discrete autoregressive flows outperform autoregressive baselines on synthetic discrete distributions, an addition task, and Potts models; and bipartite flows can obtain competitive performance with autoregressive baselines on character-level language modeling for Penn Tree Bank and text8.
A RAD approach to deep mixture models
Mar 18, 2019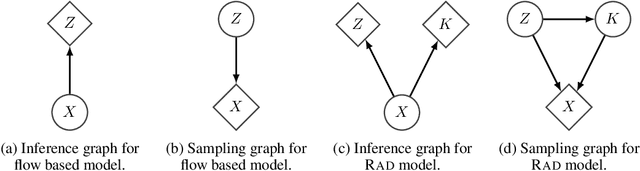

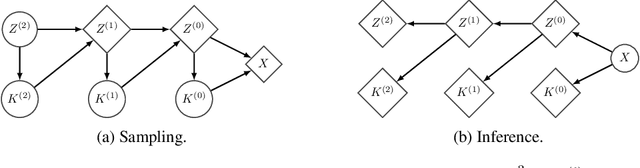
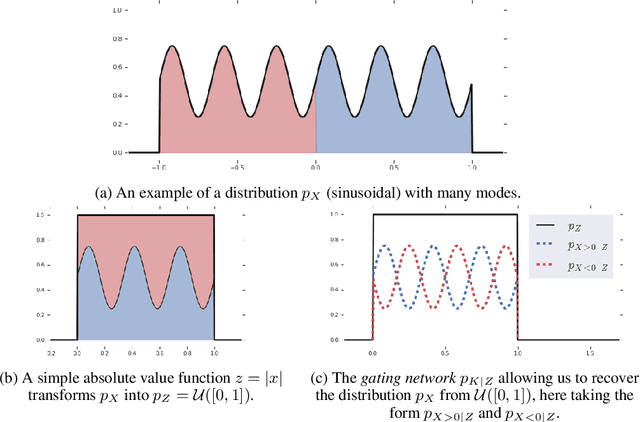
Flow based models such as Real NVP are an extremely powerful approach to density estimation. However, existing flow based models are restricted to transforming continuous densities over a continuous input space into similarly continuous distributions over continuous latent variables. This makes them poorly suited for modeling and representing discrete structures in data distributions, for example class membership or discrete symmetries. To address this difficulty, we present a normalizing flow architecture which relies on domain partitioning using locally invertible functions, and possesses both real and discrete valued latent variables. This Real and Discrete (RAD) approach retains the desirable normalizing flow properties of exact sampling, exact inference, and analytically computable probabilities, while at the same time allowing simultaneous modeling of both continuous and discrete structure in a data distribution.
VideoFlow: A Flow-Based Generative Model for Video
Mar 04, 2019


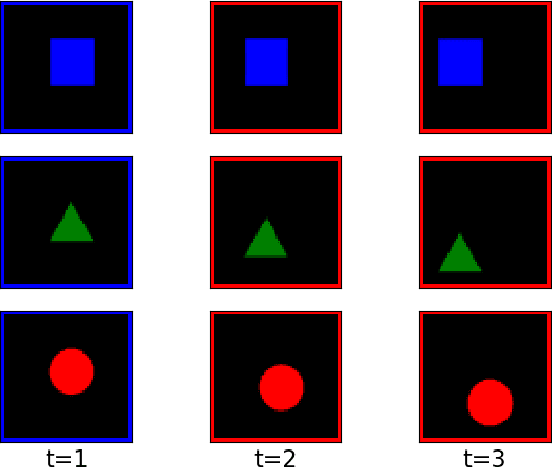
Generative models that can model and predict sequences of future events can, in principle, learn to capture complex real-world phenomena, such as physical interactions. In particular, learning predictive models of videos offers an especially appealing mechanism to enable a rich understanding of the physical world: videos of real-world interactions are plentiful and readily available, and a model that can predict future video frames can not only capture useful representations of the world, but can be useful in its own right, for problems such as model-based robotic control. However, a central challenge in video prediction is that the future is highly uncertain: a sequence of past observations of events can imply many possible futures. Although a number of recent works have studied probabilistic models that can represent uncertain futures, such models are either extremely expensive computationally (as in the case of pixel-level autoregressive models), or do not directly optimize the likelihood of the data. In this work, we propose a model for video prediction based on normalizing flows, which allows for direct optimization of the data likelihood, and produces high-quality stochastic predictions. To our knowledge, our work is the first to propose multi-frame video prediction with normalizing flows. We describe an approach for modeling the latent space dynamics, and demonstrate that flow-based generative models offer a viable and competitive approach to generative modeling of video.