 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText-Conditional JEPA for Learning Semantically Rich Visual Representations
May 05, 2026Image-based Joint-Embedding Predictive Architecture (I-JEPA) offers a promising approach to visual self-supervised learning through masked feature prediction. However with the inherent visual uncertainty at masked positions, feature prediction remains challenging and may fail to learn semantic representations. In this work, we propose Text-Conditional JEPA (TC-JEPA) that uses image captions to reduce the prediction uncertainty. Specifically, we modulate the predicted patch features using a fine-grained text conditioner that computes sparse cross-attention over input text tokens. With such conditioning, patch features become predictable as a function of text, thus are more semantically meaningful. We show TC-JEPA improves downstream performance and training stability, with promising scaling properties. TC-JEPA also offers a new vision-language pretraining paradigm based on feature prediction only, outperforming contrastive methods on diverse tasks, especially those requiring fine-grained visual understanding and reasoning.
Path-Constrained Mixture-of-Experts
Mar 18, 2026Sparse Mixture-of-Experts (MoE) architectures enable efficient scaling by activating only a subset of parameters for each input. However, conventional MoE routing selects each layer's experts independently, creating N^L possible expert paths -- for N experts across L layers. This far exceeds typical training set sizes, leading to statistical inefficiency as the model may not learn meaningful structure over such a vast path space. To constrain it, we propose \pathmoe, which shares router parameters across consecutive layers. Experiments on 0.9B and 16B parameter models demonstrate consistent improvements on perplexity and downstream tasks over independent routing, while eliminating the need for auxiliary load balancing losses. Analysis reveals that tokens following the same path naturally cluster by linguistic function, with \pathmoe{} producing more concentrated groups, better cross-layer consistency, and greater robustness to routing perturbations. These results offer a new perspective for understanding MoE architectures through the lens of expert paths.
Parameters vs FLOPs: Scaling Laws for Optimal Sparsity for Mixture-of-Experts Language Models
Jan 21, 2025Scaling the capacity of language models has consistently proven to be a reliable approach for improving performance and unlocking new capabilities. Capacity can be primarily defined by two dimensions: the number of model parameters and the compute per example. While scaling typically involves increasing both, the precise interplay between these factors and their combined contribution to overall capacity remains not fully understood. We explore this relationship in the context of sparse Mixture-of-Expert models (MoEs), which allow scaling the number of parameters without proportionally increasing the FLOPs per example. We investigate how varying the sparsity level, i.e., the ratio of non-active to total parameters, affects model performance in terms of both pretraining and downstream performance. We find that under different constraints (e.g. parameter size and total training compute), there is an optimal level of sparsity that improves both training efficiency and model performance. These results provide a better understanding of the impact of sparsity in scaling laws for MoEs and complement existing works in this area, offering insights for designing more efficient architectures.
Enhancing JEPAs with Spatial Conditioning: Robust and Efficient Representation Learning
Oct 14, 2024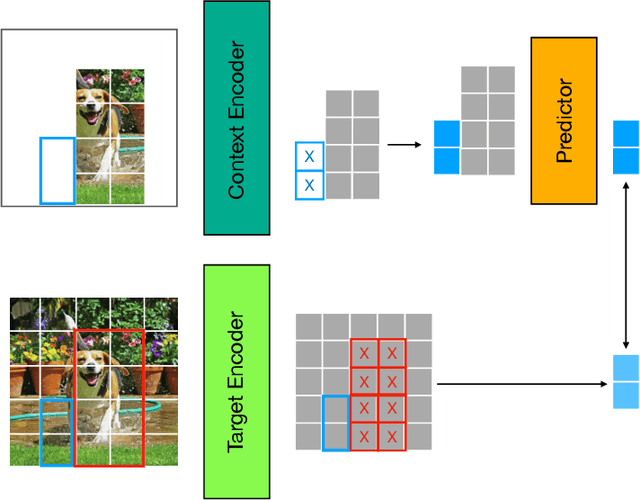
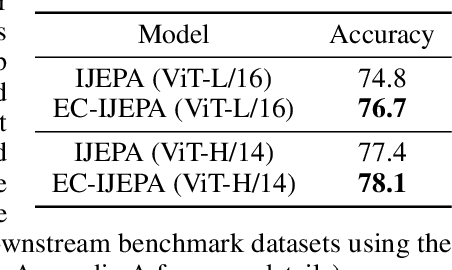
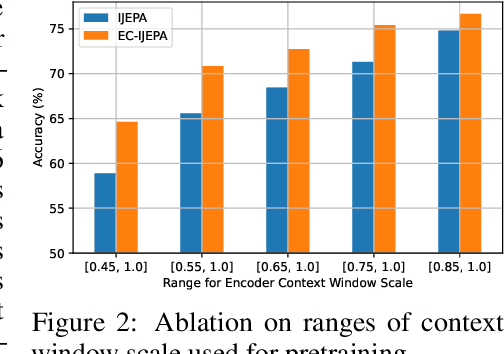
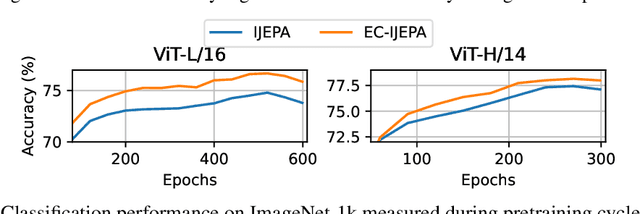
Image-based Joint-Embedding Predictive Architecture (IJEPA) offers an attractive alternative to Masked Autoencoder (MAE) for representation learning using the Masked Image Modeling framework. IJEPA drives representations to capture useful semantic information by predicting in latent rather than input space. However, IJEPA relies on carefully designed context and target windows to avoid representational collapse. The encoder modules in IJEPA cannot adaptively modulate the type of predicted and/or target features based on the feasibility of the masked prediction task as they are not given sufficient information of both context and targets. Based on the intuition that in natural images, information has a strong spatial bias with spatially local regions being highly predictive of one another compared to distant ones. We condition the target encoder and context encoder modules in IJEPA with positions of context and target windows respectively. Our "conditional" encoders show performance gains on several image classification benchmark datasets, improved robustness to context window size and sample-efficiency during pretraining.
Towards Automatic Assessment of Self-Supervised Speech Models using Rank
Sep 16, 2024


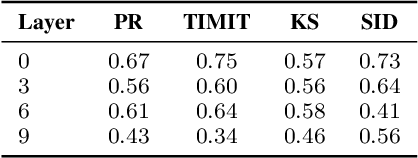
This study explores using embedding rank as an unsupervised evaluation metric for general-purpose speech encoders trained via self-supervised learning (SSL). Traditionally, assessing the performance of these encoders is resource-intensive and requires labeled data from the downstream tasks. Inspired by the vision domain, where embedding rank has shown promise for evaluating image encoders without tuning on labeled downstream data, this work examines its applicability in the speech domain, considering the temporal nature of the signals. The findings indicate rank correlates with downstream performance within encoder layers across various downstream tasks and for in- and out-of-domain scenarios. However, rank does not reliably predict the best-performing layer for specific downstream tasks, as lower-ranked layers can outperform higher-ranked ones. Despite this limitation, the results suggest that embedding rank can be a valuable tool for monitoring training progress in SSL speech models, offering a less resource-demanding alternative to traditional evaluation methods.
How JEPA Avoids Noisy Features: The Implicit Bias of Deep Linear Self Distillation Networks
Jul 03, 2024



Two competing paradigms exist for self-supervised learning of data representations. Joint Embedding Predictive Architecture (JEPA) is a class of architectures in which semantically similar inputs are encoded into representations that are predictive of each other. A recent successful approach that falls under the JEPA framework is self-distillation, where an online encoder is trained to predict the output of the target encoder, sometimes using a lightweight predictor network. This is contrasted with the Masked AutoEncoder (MAE) paradigm, where an encoder and decoder are trained to reconstruct missing parts of the input in the data space rather, than its latent representation. A common motivation for using the JEPA approach over MAE is that the JEPA objective prioritizes abstract features over fine-grained pixel information (which can be unpredictable and uninformative). In this work, we seek to understand the mechanism behind this empirical observation by analyzing the training dynamics of deep linear models. We uncover a surprising mechanism: in a simplified linear setting where both approaches learn similar representations, JEPAs are biased to learn high-influence features, i.e., features characterized by having high regression coefficients. Our results point to a distinct implicit bias of predicting in latent space that may shed light on its success in practice.
LiDAR: Sensing Linear Probing Performance in Joint Embedding SSL Architectures
Dec 07, 2023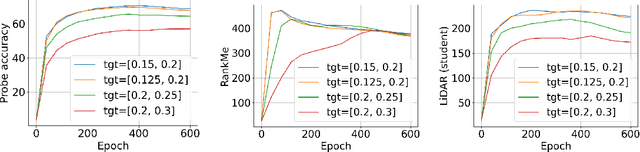
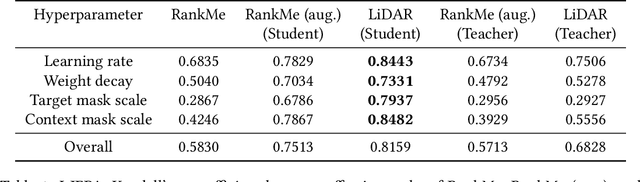

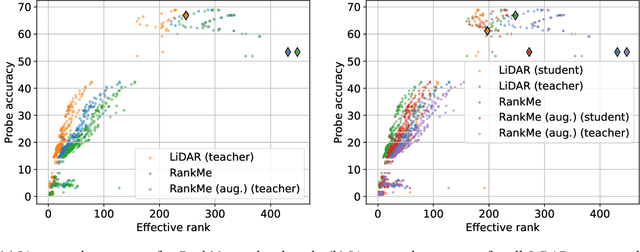
Joint embedding (JE) architectures have emerged as a promising avenue for acquiring transferable data representations. A key obstacle to using JE methods, however, is the inherent challenge of evaluating learned representations without access to a downstream task, and an annotated dataset. Without efficient and reliable evaluation, it is difficult to iterate on architectural and training choices for JE methods. In this paper, we introduce LiDAR (Linear Discriminant Analysis Rank), a metric designed to measure the quality of representations within JE architectures. Our metric addresses several shortcomings of recent approaches based on feature covariance rank by discriminating between informative and uninformative features. In essence, LiDAR quantifies the rank of the Linear Discriminant Analysis (LDA) matrix associated with the surrogate SSL task -- a measure that intuitively captures the information content as it pertains to solving the SSL task. We empirically demonstrate that LiDAR significantly surpasses naive rank based approaches in its predictive power of optimal hyperparameters. Our proposed criterion presents a more robust and intuitive means of assessing the quality of representations within JE architectures, which we hope facilitates broader adoption of these powerful techniques in various domains.
Vanishing Gradients in Reinforcement Finetuning of Language Models
Oct 31, 2023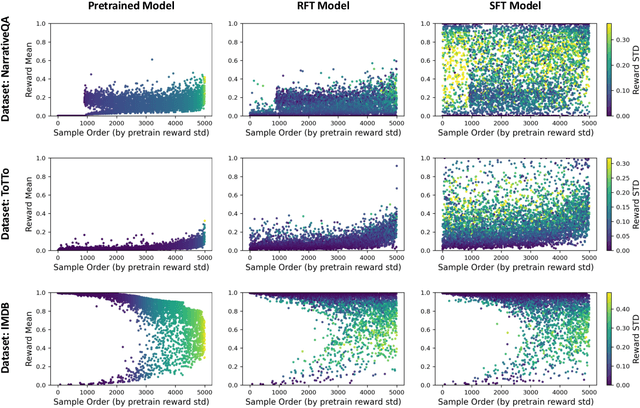
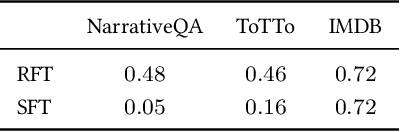
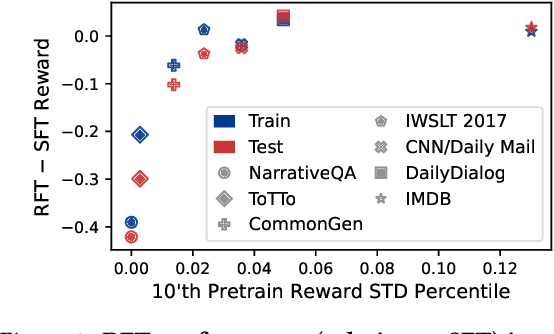
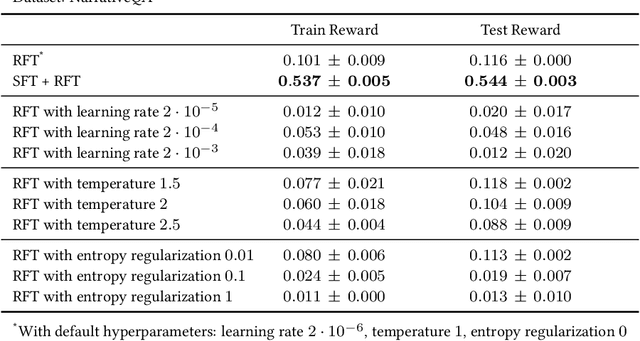
Pretrained language models are commonly aligned with human preferences and downstream tasks via reinforcement finetuning (RFT), which entails maximizing a (possibly learned) reward function using policy gradient algorithms. This work highlights a fundamental optimization obstacle in RFT: we prove that the expected gradient for an input vanishes when its reward standard deviation under the model is small, even if the expected reward is far from optimal. Through experiments on an RFT benchmark and controlled environments, as well as a theoretical analysis, we then demonstrate that vanishing gradients due to small reward standard deviation are prevalent and detrimental, leading to extremely slow reward maximization. Lastly, we explore ways to overcome vanishing gradients in RFT. We find the common practice of an initial supervised finetuning (SFT) phase to be the most promising candidate, which sheds light on its importance in an RFT pipeline. Moreover, we show that a relatively small number of SFT optimization steps on as few as 1% of the input samples can suffice, indicating that the initial SFT phase need not be expensive in terms of compute and data labeling efforts. Overall, our results emphasize that being mindful for inputs whose expected gradient vanishes, as measured by the reward standard deviation, is crucial for successful execution of RFT.
Adaptivity and Modularity for Efficient Generalization Over Task Complexity
Oct 13, 2023



Can transformers generalize efficiently on problems that require dealing with examples with different levels of difficulty? We introduce a new task tailored to assess generalization over different complexities and present results that indicate that standard transformers face challenges in solving these tasks. These tasks are variations of pointer value retrieval previously introduced by Zhang et al. (2021). We investigate how the use of a mechanism for adaptive and modular computation in transformers facilitates the learning of tasks that demand generalization over the number of sequential computation steps (i.e., the depth of the computation graph). Based on our observations, we propose a transformer-based architecture called Hyper-UT, which combines dynamic function generation from hyper networks with adaptive depth from Universal Transformers. This model demonstrates higher accuracy and a fairer allocation of computational resources when generalizing to higher numbers of computation steps. We conclude that mechanisms for adaptive depth and modularity complement each other in improving efficient generalization concerning example complexity. Additionally, to emphasize the broad applicability of our findings, we illustrate that in a standard image recognition task, Hyper- UT's performance matches that of a ViT model but with considerably reduced computational demands (achieving over 70\% average savings by effectively using fewer layers).
The Slingshot Mechanism: An Empirical Study of Adaptive Optimizers and the Grokking Phenomenon
Jun 13, 2022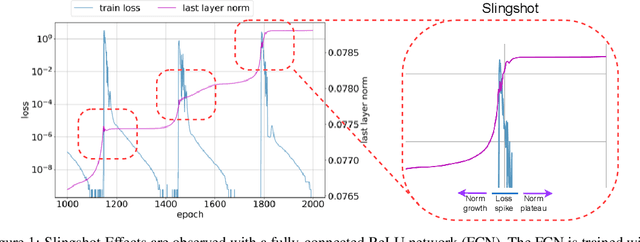
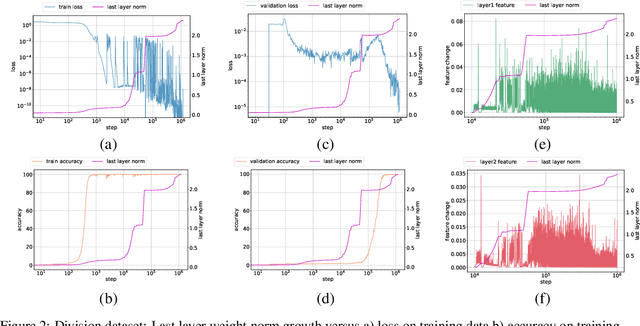
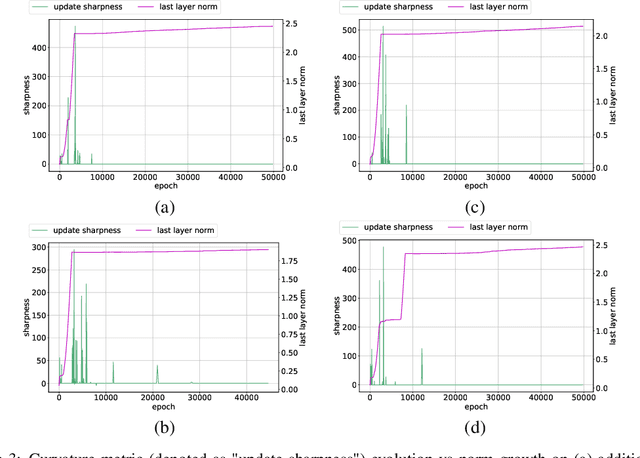
The grokking phenomenon as reported by Power et al. ( arXiv:2201.02177 ) refers to a regime where a long period of overfitting is followed by a seemingly sudden transition to perfect generalization. In this paper, we attempt to reveal the underpinnings of Grokking via a series of empirical studies. Specifically, we uncover an optimization anomaly plaguing adaptive optimizers at extremely late stages of training, referred to as the Slingshot Mechanism. A prominent artifact of the Slingshot Mechanism can be measured by the cyclic phase transitions between stable and unstable training regimes, and can be easily monitored by the cyclic behavior of the norm of the last layers weights. We empirically observe that without explicit regularization, Grokking as reported in ( arXiv:2201.02177 ) almost exclusively happens at the onset of Slingshots, and is absent without it. While common and easily reproduced in more general settings, the Slingshot Mechanism does not follow from any known optimization theories that we are aware of, and can be easily overlooked without an in depth examination. Our work points to a surprising and useful inductive bias of adaptive gradient optimizers at late stages of training, calling for a revised theoretical analysis of their origin.