 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Variational Framework for Improving Naturalness in Generative Spoken Language Models
Jun 17, 2025



The success of large language models in text processing has inspired their adaptation to speech modeling. However, since speech is continuous and complex, it is often discretized for autoregressive modeling. Speech tokens derived from self-supervised models (known as semantic tokens) typically focus on the linguistic aspects of speech but neglect prosodic information. As a result, models trained on these tokens can generate speech with reduced naturalness. Existing approaches try to fix this by adding pitch features to the semantic tokens. However, pitch alone cannot fully represent the range of paralinguistic attributes, and selecting the right features requires careful hand-engineering. To overcome this, we propose an end-to-end variational approach that automatically learns to encode these continuous speech attributes to enhance the semantic tokens. Our approach eliminates the need for manual extraction and selection of paralinguistic features. Moreover, it produces preferred speech continuations according to human raters. Code, samples and models are available at https://github.com/b04901014/vae-gslm.
Speaker-IPL: Unsupervised Learning of Speaker Characteristics with i-Vector based Pseudo-Labels
Sep 16, 2024



Iterative self-training, or iterative pseudo-labeling (IPL)--using an improved model from the current iteration to provide pseudo-labels for the next iteration--has proven to be a powerful approach to enhance the quality of speaker representations. Recent applications of IPL in unsupervised speaker recognition start with representations extracted from very elaborate self-supervised methods (e.g., DINO). However, training such strong self-supervised models is not straightforward (they require hyper-parameters tuning and may not generalize to out-of-domain data) and, moreover, may not be needed at all. To this end, we show the simple, well-studied, and established i-vector generative model is enough to bootstrap the IPL process for unsupervised learning of speaker representations. We also systematically study the impact of other components on the IPL process, which includes the initial model, the encoder, augmentations, the number of clusters, and the clustering algorithm. Remarkably, we find that even with a simple and significantly weaker initial model like i-vector, IPL can still achieve speaker verification performance that rivals state-of-the-art methods.
Exploring Prediction Targets in Masked Pre-Training for Speech Foundation Models
Sep 16, 2024



Speech foundation models, such as HuBERT and its variants, are pre-trained on large amounts of unlabeled speech for various downstream tasks. These models use a masked prediction objective, where the model learns to predict information about masked input segments from the unmasked context. The choice of prediction targets in this framework can influence performance on downstream tasks. For example, targets that encode prosody are beneficial for speaker-related tasks, while targets that encode phonetics are more suited for content-related tasks. Additionally, prediction targets can vary in the level of detail they encode; targets that encode fine-grained acoustic details are beneficial for denoising tasks, while targets that encode higher-level abstractions are more suited for content-related tasks. Despite the importance of prediction targets, the design choices that affect them have not been thoroughly studied. This work explores the design choices and their impact on downstream task performance. Our results indicate that the commonly used design choices for HuBERT can be suboptimal. We propose novel approaches to create more informative prediction targets and demonstrate their effectiveness through improvements across various downstream tasks.
Towards Automatic Assessment of Self-Supervised Speech Models using Rank
Sep 16, 2024


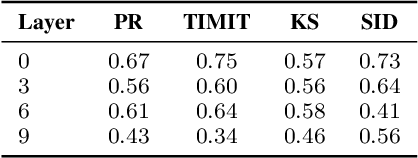
This study explores using embedding rank as an unsupervised evaluation metric for general-purpose speech encoders trained via self-supervised learning (SSL). Traditionally, assessing the performance of these encoders is resource-intensive and requires labeled data from the downstream tasks. Inspired by the vision domain, where embedding rank has shown promise for evaluating image encoders without tuning on labeled downstream data, this work examines its applicability in the speech domain, considering the temporal nature of the signals. The findings indicate rank correlates with downstream performance within encoder layers across various downstream tasks and for in- and out-of-domain scenarios. However, rank does not reliably predict the best-performing layer for specific downstream tasks, as lower-ranked layers can outperform higher-ranked ones. Despite this limitation, the results suggest that embedding rank can be a valuable tool for monitoring training progress in SSL speech models, offering a less resource-demanding alternative to traditional evaluation methods.
Rethinking Non-Negative Matrix Factorization with Implicit Neural Representations
Apr 05, 2024



Non-negative Matrix Factorization (NMF) is a powerful technique for analyzing regularly-sampled data, i.e., data that can be stored in a matrix. For audio, this has led to numerous applications using time-frequency (TF) representations like the Short-Time Fourier Transform. However extending these applications to irregularly-spaced TF representations, like the Constant-Q transform, wavelets, or sinusoidal analysis models, has not been possible since these representations cannot be directly stored in matrix form. In this paper, we formulate NMF in terms of continuous functions (instead of fixed vectors) and show that NMF can be extended to a wider variety of signal classes that need not be regularly sampled.
Can you Remove the Downstream Model for Speaker Recognition with Self-Supervised Speech Features?
Feb 01, 2024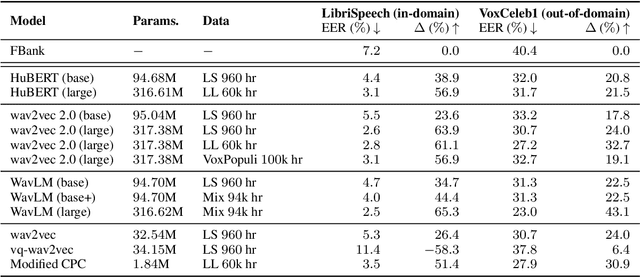
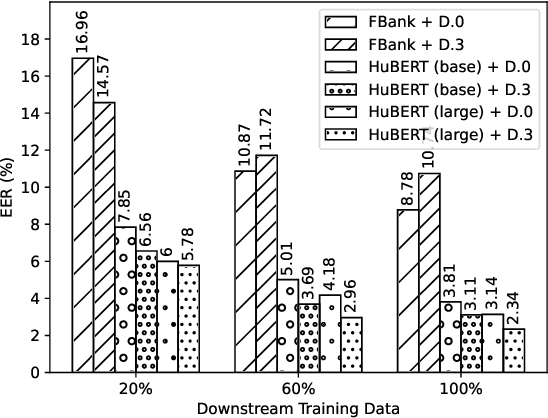

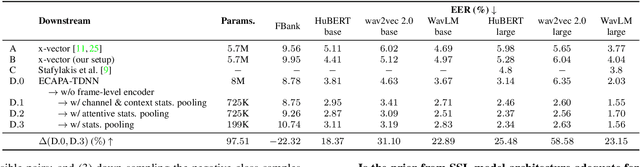
Self-supervised features are typically used in place of filter-banks in speaker verification models. However, these models were originally designed to ingest filter-banks as inputs, and thus, training them on top of self-supervised features assumes that both feature types require the same amount of learning for the task. In this work, we observe that pre-trained self-supervised speech features inherently include information required for downstream speaker verification task, and therefore, we can simplify the downstream model without sacrificing performance. To this end, we revisit the design of the downstream model for speaker verification using self-supervised features. We show that we can simplify the model to use 97.51% fewer parameters while achieving a 29.93% average improvement in performance on SUPERB. Consequently, we show that the simplified downstream model is more data efficient compared to baseline--it achieves better performance with only 60% of the training data.
ESPnet-SPK: full pipeline speaker embedding toolkit with reproducible recipes, self-supervised front-ends, and off-the-shelf models
Jan 30, 2024



This paper introduces ESPnet-SPK, a toolkit designed with several objectives for training speaker embedding extractors. First, we provide an open-source platform for researchers in the speaker recognition community to effortlessly build models. We provide several models, ranging from x-vector to recent SKA-TDNN. Through the modularized architecture design, variants can be developed easily. We also aspire to bridge developed models with other domains, facilitating the broad research community to effortlessly incorporate state-of-the-art embedding extractors. Pre-trained embedding extractors can be accessed in an off-the-shelf manner and we demonstrate the toolkit's versatility by showcasing its integration with two tasks. Another goal is to integrate with diverse self-supervised learning features. We release a reproducible recipe that achieves an equal error rate of 0.39% on the Vox1-O evaluation protocol using WavLM-Large with ECAPA-TDNN.
Does Single-channel Speech Enhancement Improve Keyword Spotting Accuracy? A Case Study
Sep 27, 2023


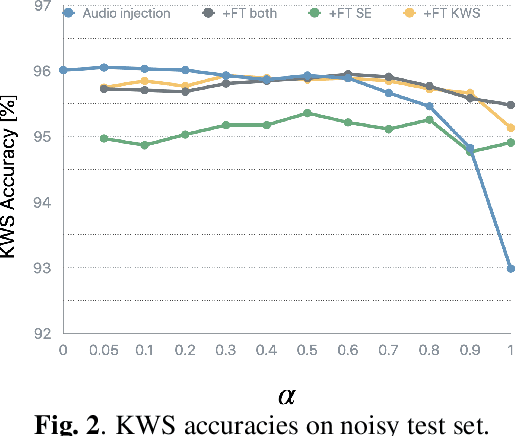
Noise robustness is a key aspect of successful speech applications. Speech enhancement (SE) has been investigated to improve automatic speech recognition accuracy; however, its effectiveness for keyword spotting (KWS) is still under-investigated. In this paper, we conduct a comprehensive study on single-channel speech enhancement for keyword spotting on the Google Speech Command (GSC) dataset. To investigate robustness to noise, the GSC dataset is augmented with noise signals from the WSJ0 Hipster Ambient Mixtures (WHAM!) noise dataset. Our investigation includes not only applying SE before KWS but also performing joint training of the SE frontend and KWS backend models. Moreover, we explore audio injection, a common approach to reduce distortions by using a weighted average of the enhanced and original signals. Audio injection is then further optimized by using another model that predicts the weight for each utterance. Our investigation reveals that SE can improve KWS accuracy on noisy speech when the backend model is trained on clean speech; however, despite our extensive exploration, it is difficult to improve the KWS accuracy with SE when the backend is trained on noisy speech.
Multichannel Voice Trigger Detection Based on Transform-average-concatenate
Sep 27, 2023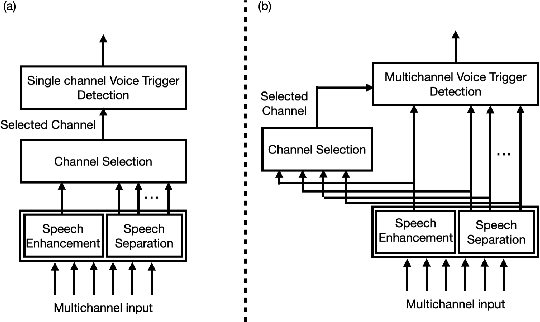
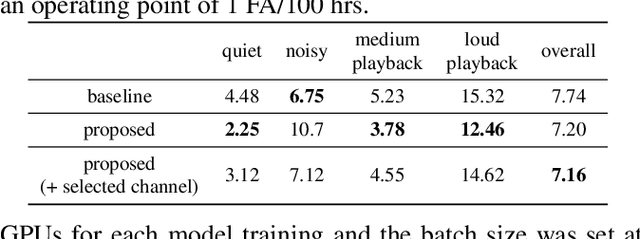
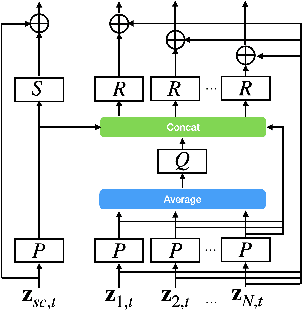
Voice triggering (VT) enables users to activate their devices by just speaking a trigger phrase. A front-end system is typically used to perform speech enhancement and/or separation, and produces multiple enhanced and/or separated signals. Since conventional VT systems take only single-channel audio as input, channel selection is performed. A drawback of this approach is that unselected channels are discarded, even if the discarded channels could contain useful information for VT. In this work, we propose multichannel acoustic models for VT, where the multichannel output from the frond-end is fed directly into a VT model. We adopt a transform-average-concatenate (TAC) block and modify the TAC block by incorporating the channel from the conventional channel selection so that the model can attend to a target speaker when multiple speakers are present. The proposed approach achieves up to 30% reduction in the false rejection rate compared to the baseline channel selection approach.
Improving Voice Trigger Detection with Metric Learning
Apr 05, 2022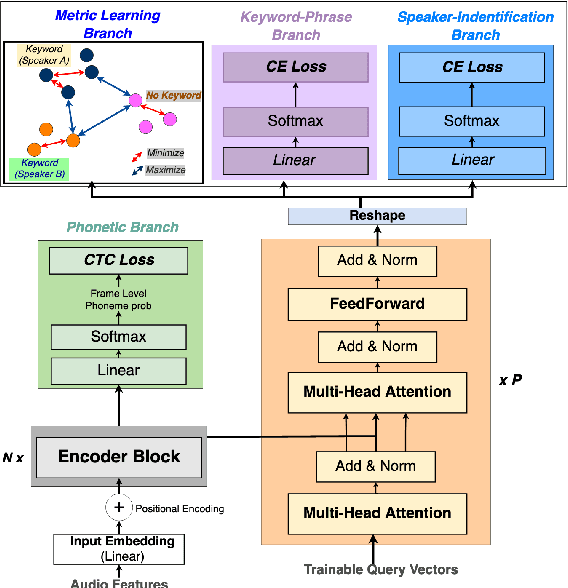

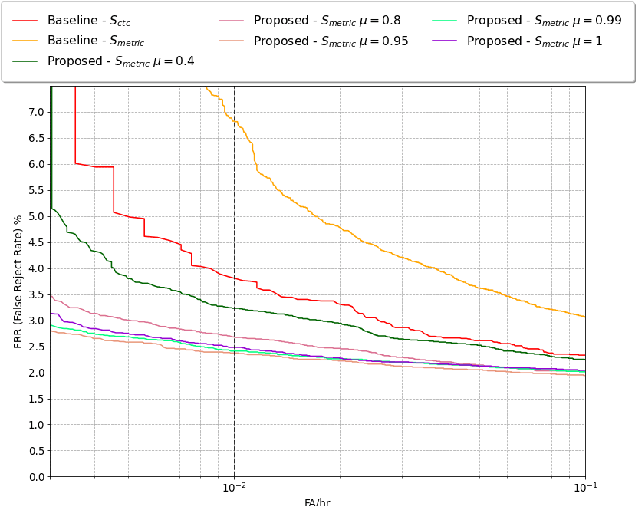
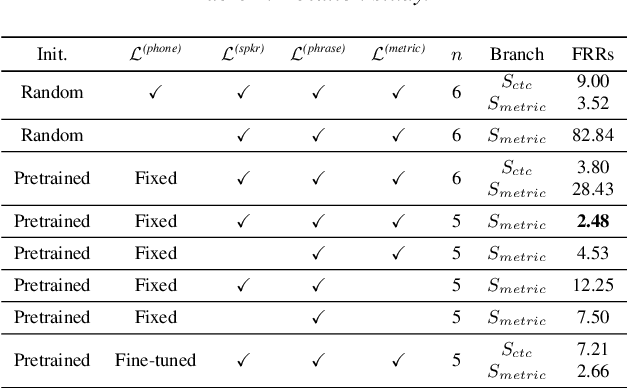
Voice trigger detection is an important task, which enables activating a voice assistant when a target user speaks a keyword phrase. A detector is typically trained on speech data independent of speaker information and used for the voice trigger detection task. However, such a speaker independent voice trigger detector typically suffers from performance degradation on speech from underrepresented groups, such as accented speakers. In this work, we propose a novel voice trigger detector that can use a small number of utterances from a target speaker to improve detection accuracy. Our proposed model employs an encoder-decoder architecture. While the encoder performs speaker independent voice trigger detection, similar to the conventional detector, the decoder predicts a personalized embedding for each utterance. A personalized voice trigger score is then obtained as a similarity score between the embeddings of enrollment utterances and a test utterance. The personalized embedding allows adapting to target speaker's speech when computing the voice trigger score, hence improving voice trigger detection accuracy. Experimental results show that the proposed approach achieves a 38% relative reduction in a false rejection rate (FRR) compared to a baseline speaker independent voice trigger model.