 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Personalized Voice Activity Detection Systems: Assessing Real-World Effectiveness
Jun 12, 2024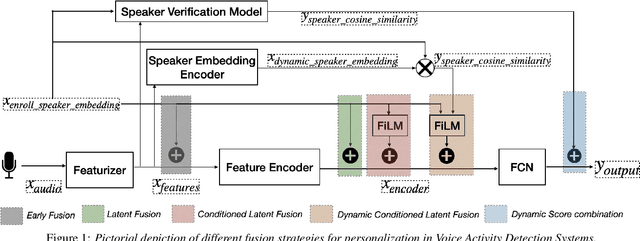
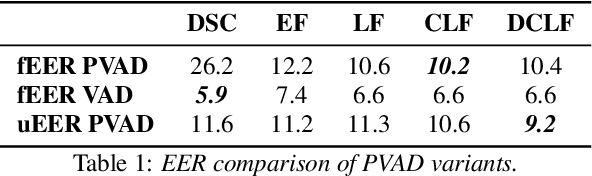
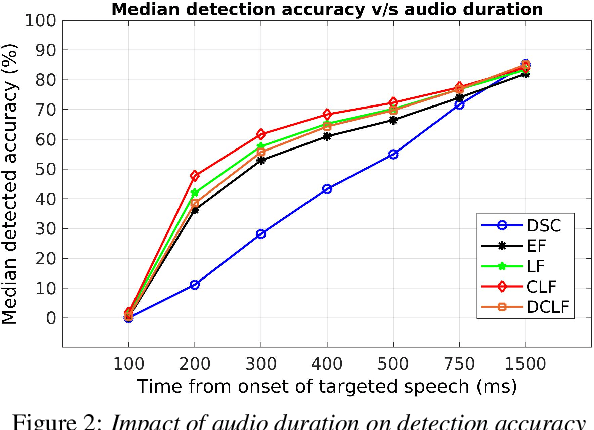

Voice activity detection (VAD) is a critical component in various applications such as speech recognition, speech enhancement, and hands-free communication systems. With the increasing demand for personalized and context-aware technologies, the need for effective personalized VAD systems has become paramount. In this paper, we present a comparative analysis of Personalized Voice Activity Detection (PVAD) systems to assess their real-world effectiveness. We introduce a comprehensive approach to assess PVAD systems, incorporating various performance metrics such as frame-level and utterance-level error rates, detection latency and accuracy, alongside user-level analysis. Through extensive experimentation and evaluation, we provide a thorough understanding of the strengths and limitations of various PVAD variants. This paper advances the understanding of PVAD technology by offering insights into its efficacy and viability in practical applications using a comprehensive set of metrics.
Improving Voice Trigger Detection with Metric Learning
Apr 05, 2022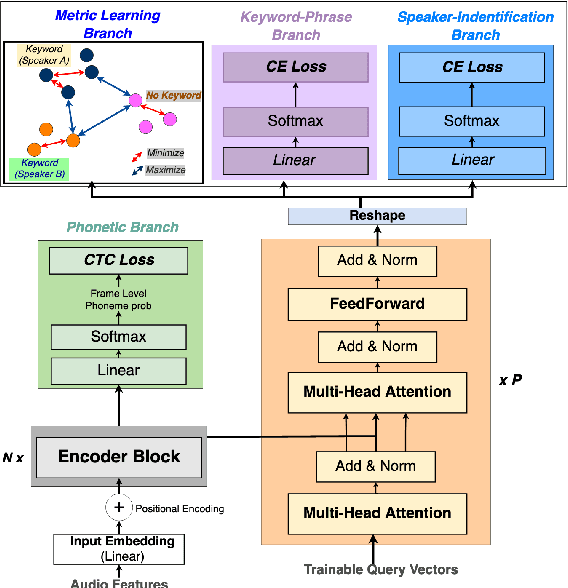

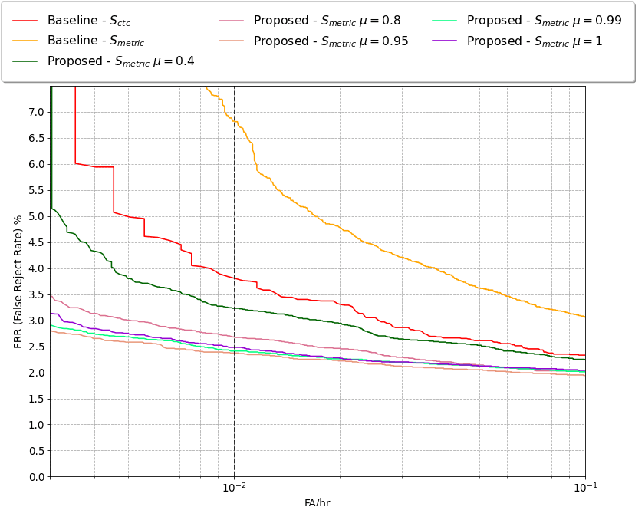
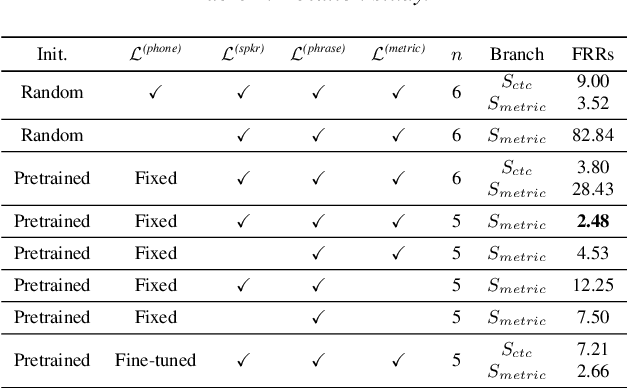
Voice trigger detection is an important task, which enables activating a voice assistant when a target user speaks a keyword phrase. A detector is typically trained on speech data independent of speaker information and used for the voice trigger detection task. However, such a speaker independent voice trigger detector typically suffers from performance degradation on speech from underrepresented groups, such as accented speakers. In this work, we propose a novel voice trigger detector that can use a small number of utterances from a target speaker to improve detection accuracy. Our proposed model employs an encoder-decoder architecture. While the encoder performs speaker independent voice trigger detection, similar to the conventional detector, the decoder predicts a personalized embedding for each utterance. A personalized voice trigger score is then obtained as a similarity score between the embeddings of enrollment utterances and a test utterance. The personalized embedding allows adapting to target speaker's speech when computing the voice trigger score, hence improving voice trigger detection accuracy. Experimental results show that the proposed approach achieves a 38% relative reduction in a false rejection rate (FRR) compared to a baseline speaker independent voice trigger model.
I4U Submission to NIST SRE 2018: Leveraging from a Decade of Shared Experiences
Apr 16, 2019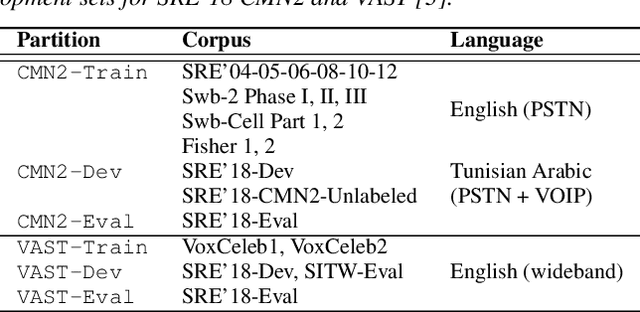
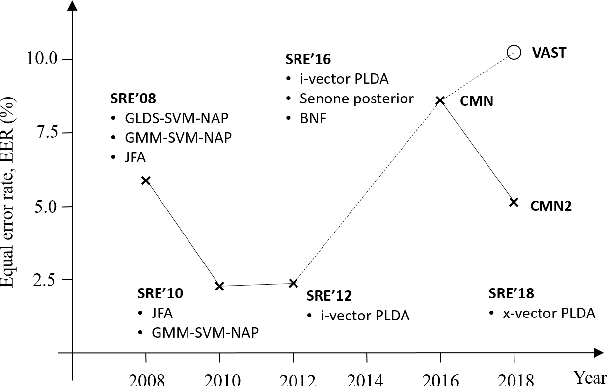
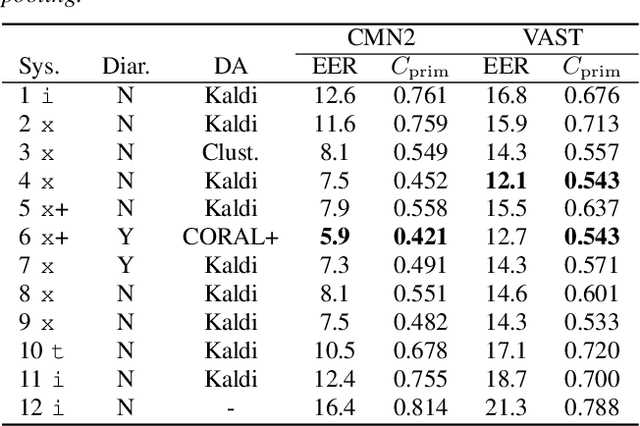
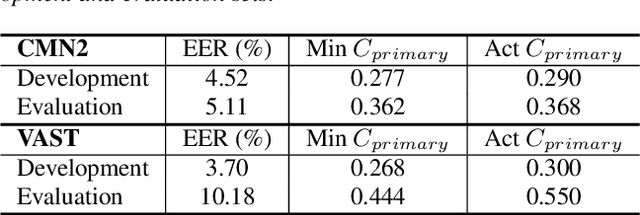
The I4U consortium was established to facilitate a joint entry to NIST speaker recognition evaluations (SRE). The latest edition of such joint submission was in SRE 2018, in which the I4U submission was among the best-performing systems. SRE'18 also marks the 10-year anniversary of I4U consortium into NIST SRE series of evaluation. The primary objective of the current paper is to summarize the results and lessons learned based on the twelve sub-systems and their fusion submitted to SRE'18. It is also our intention to present a shared view on the advancements, progresses, and major paradigm shifts that we have witnessed as an SRE participant in the past decade from SRE'08 to SRE'18. In this regard, we have seen, among others, a paradigm shift from supervector representation to deep speaker embedding, and a switch of research challenge from channel compensation to domain adaptation.
UTD-CRSS Systems for 2016 NIST Speaker Recognition Evaluation
Oct 24, 2016
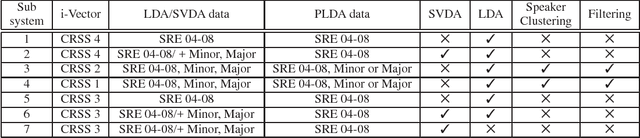
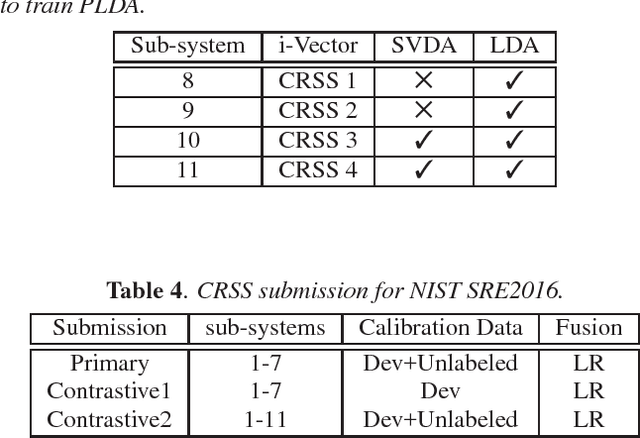
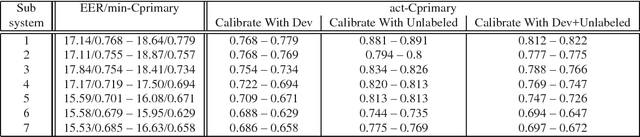
This document briefly describes the systems submitted by the Center for Robust Speech Systems (CRSS) from The University of Texas at Dallas (UTD) to the 2016 National Institute of Standards and Technology (NIST) Speaker Recognition Evaluation (SRE). We developed several UBM and DNN i-Vector based speaker recognition systems with different data sets and feature representations. Given that the emphasis of the NIST SRE 2016 is on language mismatch between training and enrollment/test data, so-called domain mismatch, in our system development we focused on: (1) using unlabeled in-domain data for centralizing data to alleviate the domain mismatch problem, (2) finding the best data set for training LDA/PLDA, (3) using newly proposed dimension reduction technique incorporating unlabeled in-domain data before PLDA training, (4) unsupervised speaker clustering of unlabeled data and using them alone or with previous SREs for PLDA training, (5) score calibration using only unlabeled data and combination of unlabeled and development (Dev) data as separate experiments.