 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparative Analysis of Personalized Voice Activity Detection Systems: Assessing Real-World Effectiveness
Jun 12, 2024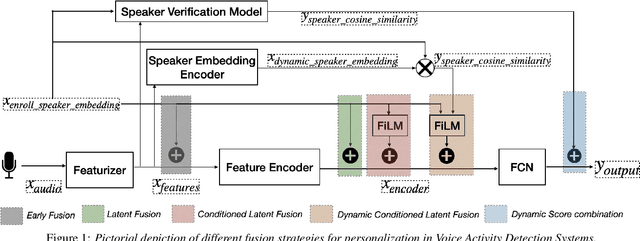
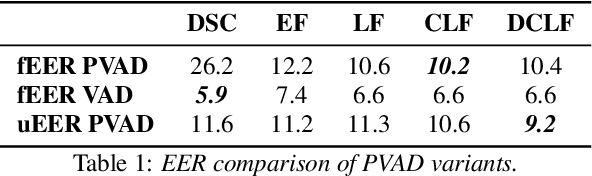
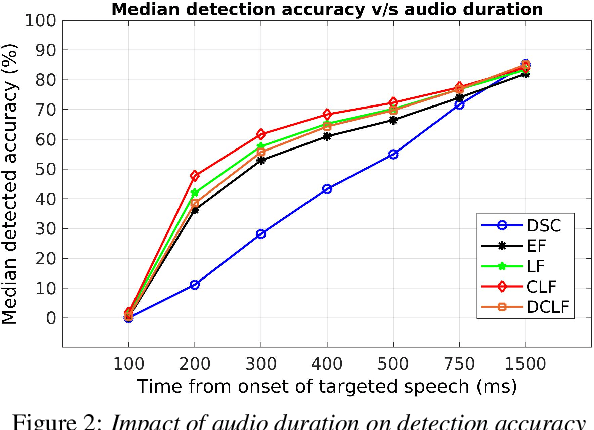

Voice activity detection (VAD) is a critical component in various applications such as speech recognition, speech enhancement, and hands-free communication systems. With the increasing demand for personalized and context-aware technologies, the need for effective personalized VAD systems has become paramount. In this paper, we present a comparative analysis of Personalized Voice Activity Detection (PVAD) systems to assess their real-world effectiveness. We introduce a comprehensive approach to assess PVAD systems, incorporating various performance metrics such as frame-level and utterance-level error rates, detection latency and accuracy, alongside user-level analysis. Through extensive experimentation and evaluation, we provide a thorough understanding of the strengths and limitations of various PVAD variants. This paper advances the understanding of PVAD technology by offering insights into its efficacy and viability in practical applications using a comprehensive set of metrics.
Efficient Multimodal Neural Networks for Trigger-less Voice Assistants
May 20, 2023



The adoption of multimodal interactions by Voice Assistants (VAs) is growing rapidly to enhance human-computer interactions. Smartwatches have now incorporated trigger-less methods of invoking VAs, such as Raise To Speak (RTS), where the user raises their watch and speaks to VAs without an explicit trigger. Current state-of-the-art RTS systems rely on heuristics and engineered Finite State Machines to fuse gesture and audio data for multimodal decision-making. However, these methods have limitations, including limited adaptability, scalability, and induced human biases. In this work, we propose a neural network based audio-gesture multimodal fusion system that (1) Better understands temporal correlation between audio and gesture data, leading to precise invocations (2) Generalizes to a wide range of environments and scenarios (3) Is lightweight and deployable on low-power devices, such as smartwatches, with quick launch times (4) Improves productivity in asset development processes.