 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUTD-CRSS Systems for 2016 NIST Speaker Recognition Evaluation
Paper and Code
Oct 24, 2016
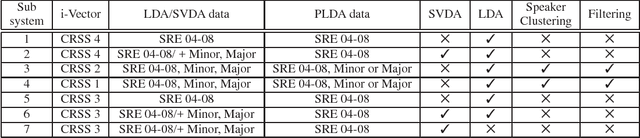
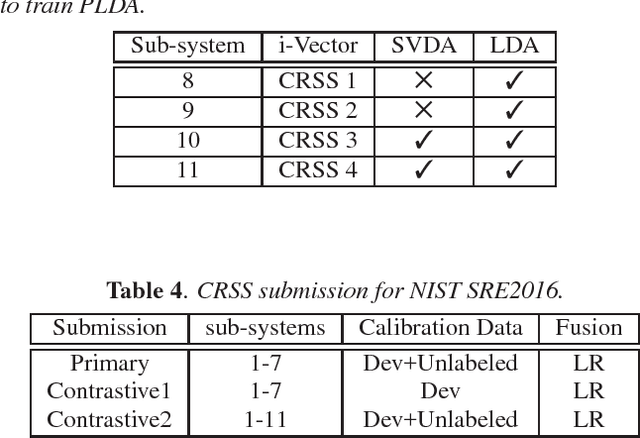
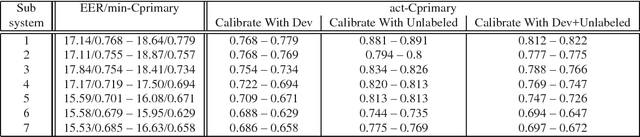
This document briefly describes the systems submitted by the Center for Robust Speech Systems (CRSS) from The University of Texas at Dallas (UTD) to the 2016 National Institute of Standards and Technology (NIST) Speaker Recognition Evaluation (SRE). We developed several UBM and DNN i-Vector based speaker recognition systems with different data sets and feature representations. Given that the emphasis of the NIST SRE 2016 is on language mismatch between training and enrollment/test data, so-called domain mismatch, in our system development we focused on: (1) using unlabeled in-domain data for centralizing data to alleviate the domain mismatch problem, (2) finding the best data set for training LDA/PLDA, (3) using newly proposed dimension reduction technique incorporating unlabeled in-domain data before PLDA training, (4) unsupervised speaker clustering of unlabeled data and using them alone or with previous SREs for PLDA training, (5) score calibration using only unlabeled data and combination of unlabeled and development (Dev) data as separate experiments.