 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmotion-Aware Prefix: Towards Explicit Emotion Control in Voice Conversion Models
Mar 10, 2026Recent advances in zero-shot voice conversion have exhibited potential in emotion control, yet the performance is suboptimal or inconsistent due to their limited expressive capacity. We propose Emotion-Aware Prefix for explicit emotion control in a two-stage voice conversion backbone. We significantly improve emotion conversion performance, doubling the baseline Emotion Conversion Accuracy (ECA) from 42.40% to 85.50% while maintaining linguistic integrity and speech quality, without compromising speaker identity. Our ablation study suggests that a joint control of both sequence modulation and acoustic realization is essential to synthesize distinct emotions. Furthermore, comparative analysis verifies the generalizability of proposed method, while it provides insights on the role of acoustic decoupling in maintaining speaker identity.
DeepTraverse: A Depth-First Search Inspired Network for Algorithmic Visual Understanding
Jun 11, 2025Conventional vision backbones, despite their success, often construct features through a largely uniform cascade of operations, offering limited explicit pathways for adaptive, iterative refinement. This raises a compelling question: can principles from classical search algorithms instill a more algorithmic, structured, and logical processing flow within these networks, leading to representations built through more interpretable, perhaps reasoning-like decision processes? We introduce DeepTraverse, a novel vision architecture directly inspired by algorithmic search strategies, enabling it to learn features through a process of systematic elucidation and adaptive refinement distinct from conventional approaches. DeepTraverse operationalizes this via two key synergistic components: recursive exploration modules that methodically deepen feature analysis along promising representational paths with parameter sharing for efficiency, and adaptive calibration modules that dynamically adjust feature salience based on evolving global context. The resulting algorithmic interplay allows DeepTraverse to intelligently construct and refine feature patterns. Comprehensive evaluations across a diverse suite of image classification benchmarks show that DeepTraverse achieves highly competitive classification accuracy and robust feature discrimination, often outperforming conventional models with similar or larger parameter counts. Our work demonstrates that integrating such algorithmic priors provides a principled and effective strategy for building more efficient, performant, and structured vision backbones.
UniPET-SPK: A Unified Framework for Parameter-Efficient Tuning of Pre-trained Speech Models for Robust Speaker Verification
Jan 27, 2025With excellent generalization ability, SSL speech models have shown impressive performance on various downstream tasks in the pre-training and fine-tuning paradigm. However, as the size of pre-trained models grows, fine-tuning becomes practically unfeasible due to expanding computation and storage requirements and the risk of overfitting. This study explores parameter-efficient tuning (PET) methods for adapting large-scale pre-trained SSL speech models to speaker verification task. Correspondingly, we propose three PET methods: (i)an adapter-tuning method, (ii)a prompt-tuning method, and (iii)a unified framework that effectively incorporates adapter-tuning and prompt-tuning with a dynamically learnable gating mechanism. First, we propose the Inner+Inter Adapter framework, which inserts two types of adapters into pre-trained models, allowing for adaptation of latent features within the intermediate Transformer layers and output embeddings from all Transformer layers, through a parallel adapter design. Second, we propose the Deep Speaker Prompting method that concatenates trainable prompt tokens into the input space of pre-trained models to guide adaptation. Lastly, we propose the UniPET-SPK, a unified framework that effectively incorporates these two alternate PET methods into a single framework with a dynamic trainable gating mechanism. The proposed UniPET-SPK learns to find the optimal mixture of PET methods to match different datasets and scenarios. We conduct a comprehensive set of experiments on several datasets to validate the effectiveness of the proposed PET methods. Experimental results on VoxCeleb, CN-Celeb, and 1st 48-UTD forensic datasets demonstrate that the proposed UniPET-SPK consistently outperforms the two PET methods, fine-tuning, and other parameter-efficient tuning methods, achieving superior performance while updating only 5.4% of the parameters.
DiffAttack: Diffusion-based Timbre-reserved Adversarial Attack in Speaker Identification
Jan 09, 2025



Being a form of biometric identification, the security of the speaker identification (SID) system is of utmost importance. To better understand the robustness of SID systems, we aim to perform more realistic attacks in SID, which are challenging for both humans and machines to detect. In this study, we propose DiffAttack, a novel timbre-reserved adversarial attack approach that exploits the capability of a diffusion-based voice conversion (DiffVC) model to generate adversarial fake audio with distinct target speaker attribution. By introducing adversarial constraints into the generative process of the diffusion-based voice conversion model, we craft fake samples that effectively mislead target models while preserving speaker-wise characteristics. Specifically, inspired by the use of randomly sampled Gaussian noise in conventional adversarial attacks and diffusion processes, we incorporate adversarial constraints into the reverse diffusion process. These constraints subtly guide the reverse diffusion process toward aligning with the target speaker distribution. Our experiments on the LibriTTS dataset indicate that DiffAttack significantly improves the attack success rate compared to vanilla DiffVC and other methods. Moreover, objective and subjective evaluations demonstrate that introducing adversarial constraints does not compromise the speech quality generated by the DiffVC model.
Toward Improving Synthetic Audio Spoofing Detection Robustness via Meta-Learning and Disentangled Training With Adversarial Examples
Aug 23, 2024



Advances in automatic speaker verification (ASV) promote research into the formulation of spoofing detection systems for real-world applications. The performance of ASV systems can be degraded severely by multiple types of spoofing attacks, namely, synthetic speech (SS), voice conversion (VC), replay, twins and impersonation, especially in the case of unseen synthetic spoofing attacks. A reliable and robust spoofing detection system can act as a security gate to filter out spoofing attacks instead of having them reach the ASV system. A weighted additive angular margin loss is proposed to address the data imbalance issue, and different margins has been assigned to improve generalization to unseen spoofing attacks in this study. Meanwhile, we incorporate a meta-learning loss function to optimize differences between the embeddings of support versus query set in order to learn a spoofing-category-independent embedding space for utterances. Furthermore, we craft adversarial examples by adding imperceptible perturbations to spoofing speech as a data augmentation strategy, then we use an auxiliary batch normalization (BN) to guarantee that corresponding normalization statistics are performed exclusively on the adversarial examples. Additionally, A simple attention module is integrated into the residual block to refine the feature extraction process. Evaluation results on the Logical Access (LA) track of the ASVspoof 2019 corpus provides confirmation of our proposed approaches' effectiveness in terms of a pooled EER of 0.87%, and a min t-DCF of 0.0277. These advancements offer effective options to reduce the impact of spoofing attacks on voice recognition/authentication systems.
* IEEE ACCESS 2024
Navigating the United States Legislative Landscape on Voice Privacy: Existing Laws, Proposed Bills, Protection for Children, and Synthetic Data for AI
Jul 29, 2024

Privacy is a hot topic for policymakers across the globe, including the United States. Evolving advances in AI and emerging concerns about the misuse of personal data have pushed policymakers to draft legislation on trustworthy AI and privacy protection for its citizens. This paper presents the state of the privacy legislation at the U.S. Congress and outlines how voice data is considered as part of the legislation definition. This paper also reviews additional privacy protection for children. This paper presents a holistic review of enacted and proposed privacy laws, and consideration for voice data, including guidelines for processing children's data, in those laws across the fifty U.S. states. As a groundbreaking alternative to actual human data, ethically generated synthetic data allows much flexibility to keep AI innovation in progress. Given the consideration of synthetic data in AI legislation by policymakers to be relatively new, as compared to that of privacy laws, this paper reviews regulatory considerations for synthetic data.
We Need Variations in Speech Synthesis: Sub-center Modelling for Speaker Embeddings
Jul 05, 2024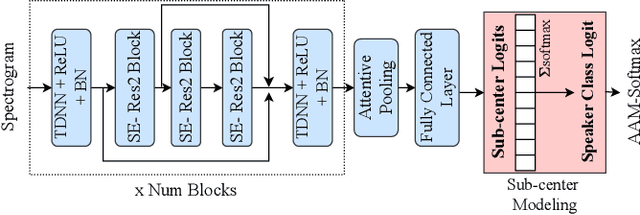
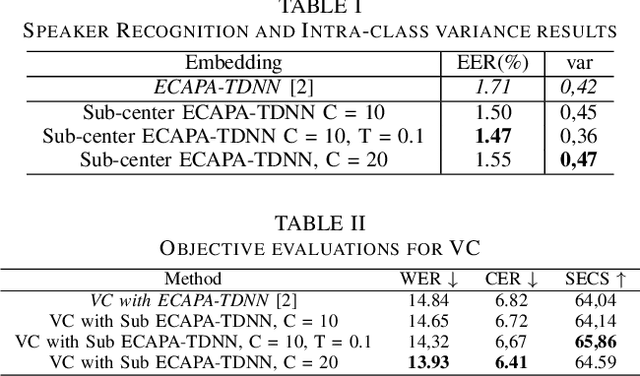
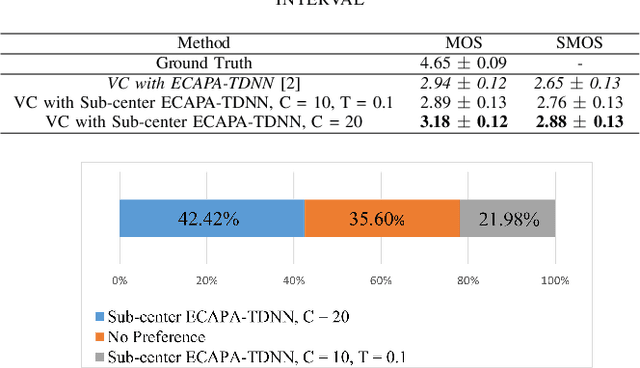
In speech synthesis, modeling of rich emotions and prosodic variations present in human voice are crucial to synthesize natural speech. Although speaker embeddings have been widely used in personalized speech synthesis as conditioning inputs, they are designed to lose variation to optimize speaker recognition accuracy. Thus, they are suboptimal for speech synthesis in terms of modeling the rich variations at the output speech distribution. In this work, we propose a novel speaker embedding network which utilizes multiple class centers in the speaker classification training rather than a single class center as traditional embeddings. The proposed approach introduces variations in the speaker embedding while retaining the speaker recognition performance since model does not have to map all of the utterances of a speaker into a single class center. We apply our proposed embedding in voice conversion task and show that our method provides better naturalness and prosody in synthesized speech.
Efficient Adapter Tuning of Pre-trained Speech Models for Automatic Speaker Verification
Mar 01, 2024



With excellent generalization ability, self-supervised speech models have shown impressive performance on various downstream speech tasks in the pre-training and fine-tuning paradigm. However, as the growing size of pre-trained models, fine-tuning becomes practically unfeasible due to heavy computation and storage overhead, as well as the risk of overfitting. Adapters are lightweight modules inserted into pre-trained models to facilitate parameter-efficient adaptation. In this paper, we propose an effective adapter framework designed for adapting self-supervised speech models to the speaker verification task. With a parallel adapter design, our proposed framework inserts two types of adapters into the pre-trained model, allowing the adaptation of latent features within intermediate Transformer layers and output embeddings from all Transformer layers. We conduct comprehensive experiments to validate the efficiency and effectiveness of the proposed framework. Experimental results on the VoxCeleb1 dataset demonstrate that the proposed adapters surpass fine-tuning and other parameter-efficient transfer learning methods, achieving superior performance while updating only 5% of the parameters.
Multi-objective Non-intrusive Hearing-aid Speech Assessment Model
Nov 15, 2023Without the need for a clean reference, non-intrusive speech assessment methods have caught great attention for objective evaluations. While deep learning models have been used to develop non-intrusive speech assessment methods with promising results, there is limited research on hearing-impaired subjects. This study proposes a multi-objective non-intrusive hearing-aid speech assessment model, called HASA-Net Large, which predicts speech quality and intelligibility scores based on input speech signals and specified hearing-loss patterns. Our experiments showed the utilization of pre-trained SSL models leads to a significant boost in speech quality and intelligibility predictions compared to using spectrograms as input. Additionally, we examined three distinct fine-tuning approaches that resulted in further performance improvements. Furthermore, we demonstrated that incorporating SSL models resulted in greater transferability to OOD dataset. Finally, this study introduces HASA-Net Large, which is a non-invasive approach for evaluating speech quality and intelligibility. HASA-Net Large utilizes raw waveforms and hearing-loss patterns to accurately predict speech quality and intelligibility levels for individuals with normal and impaired hearing and demonstrates superior prediction performance and transferability.
MixRep: Hidden Representation Mixup for Low-Resource Speech Recognition
Oct 27, 2023



In this paper, we present MixRep, a simple and effective data augmentation strategy based on mixup for low-resource ASR. MixRep interpolates the feature dimensions of hidden representations in the neural network that can be applied to both the acoustic feature input and the output of each layer, which generalizes the previous MixSpeech method. Further, we propose to combine the mixup with a regularization along the time axis of the input, which is shown as complementary. We apply MixRep to a Conformer encoder of an E2E LAS architecture trained with a joint CTC loss. We experiment on the WSJ dataset and subsets of the SWB dataset, covering reading and telephony conversational speech. Experimental results show that MixRep consistently outperforms other regularization methods for low-resource ASR. Compared to a strong SpecAugment baseline, MixRep achieves a +6.5\% and a +6.7\% relative WER reduction on the eval92 set and the Callhome part of the eval'2000 set.