 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTokenSE: a Mamba-based discrete token speech enhancement framework for cochlear implants
Apr 14, 2026Speech enhancement (SE) is critical for improving speech intelligibility and quality in real-world environments, particularly for cochlear implant (CI) users who experience severe degradations in speech understanding under noisy and reverberant conditions. In this study, we propose TokenSE, a discrete token-based SE framework operating in the neural audio codec space, which predicts clean codec token indices from degraded speech using a Mamba-based model. Unlike the earlier Transformer architecture, whose self-attention mechanism has a computational complexity that grows quadratically with sequence length, the input-dependent selection mechanism of Mamba achieves linear complexity, making it a compelling alternative to Transformers, especially for CI and hearing-aid (HA) applications. Objective evaluations show that TokenSE consistently outperforms baseline methods on both in-domain and out-of-domain datasets. Moreover, subjective listening experiments with CI users indicate clear benefit in speech intelligibility under adverse noisy and reverberant environments.
Restorative Speech Enhancement: A Progressive Approach Using SE and Codec Modules
Oct 02, 2024



In challenging environments with significant noise and reverberation, traditional speech enhancement (SE) methods often lead to over-suppressed speech, creating artifacts during listening and harming downstream tasks performance. To overcome these limitations, we propose a novel approach called Restorative SE (RestSE), which combines a lightweight SE module with a generative codec module to progressively enhance and restore speech quality. The SE module initially reduces noise, while the codec module subsequently performs dereverberation and restores speech using generative capabilities. We systematically explore various quantization techniques within the codec module to optimize performance. Additionally, we introduce a weighted loss function and feature fusion that merges the SE output with the original mixture, particularly at segments where the SE output is heavily distorted. Experimental results demonstrate the effectiveness of our proposed method in enhancing speech quality under adverse conditions. Audio demos are available at: https://sophie091524.github.io/RestorativeSE/.
Multi-objective Non-intrusive Hearing-aid Speech Assessment Model
Nov 15, 2023Without the need for a clean reference, non-intrusive speech assessment methods have caught great attention for objective evaluations. While deep learning models have been used to develop non-intrusive speech assessment methods with promising results, there is limited research on hearing-impaired subjects. This study proposes a multi-objective non-intrusive hearing-aid speech assessment model, called HASA-Net Large, which predicts speech quality and intelligibility scores based on input speech signals and specified hearing-loss patterns. Our experiments showed the utilization of pre-trained SSL models leads to a significant boost in speech quality and intelligibility predictions compared to using spectrograms as input. Additionally, we examined three distinct fine-tuning approaches that resulted in further performance improvements. Furthermore, we demonstrated that incorporating SSL models resulted in greater transferability to OOD dataset. Finally, this study introduces HASA-Net Large, which is a non-invasive approach for evaluating speech quality and intelligibility. HASA-Net Large utilizes raw waveforms and hearing-loss patterns to accurately predict speech quality and intelligibility levels for individuals with normal and impaired hearing and demonstrates superior prediction performance and transferability.
Study on the Correlation between Objective Evaluations and Subjective Speech Quality and Intelligibility
Jul 10, 2023Subjective tests are the gold standard for evaluating speech quality and intelligibility, but they are time-consuming and expensive. Thus, objective measures that align with human perceptions are crucial. This study evaluates the correlation between commonly used objective measures and subjective speech quality and intelligibility using a Chinese speech dataset. Moreover, new objective measures are proposed combining current objective measures using deep learning techniques to predict subjective quality and intelligibility. The proposed deep learning model reduces the amount of training data without significantly impacting prediction performance. We interpret the deep learning model to understand how objective measures reflect subjective quality and intelligibility. We also explore the impact of including subjective speech quality ratings on speech intelligibility prediction. Our findings offer valuable insights into the relationship between objective measures and human perceptions.
Boosting Self-Supervised Embeddings for Speech Enhancement
Apr 07, 2022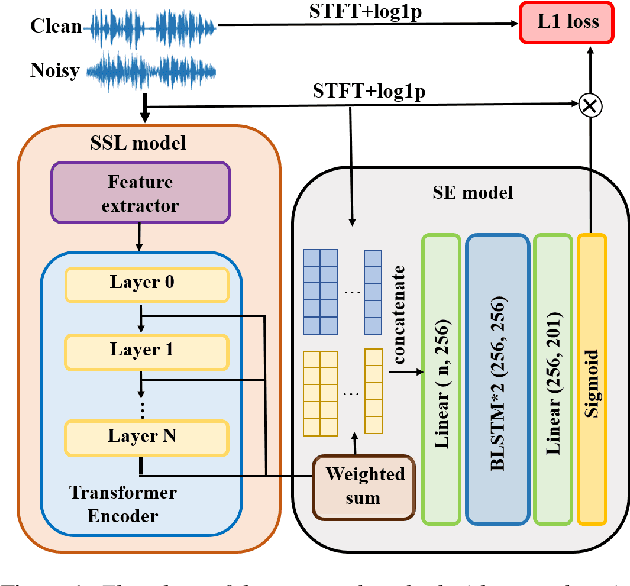
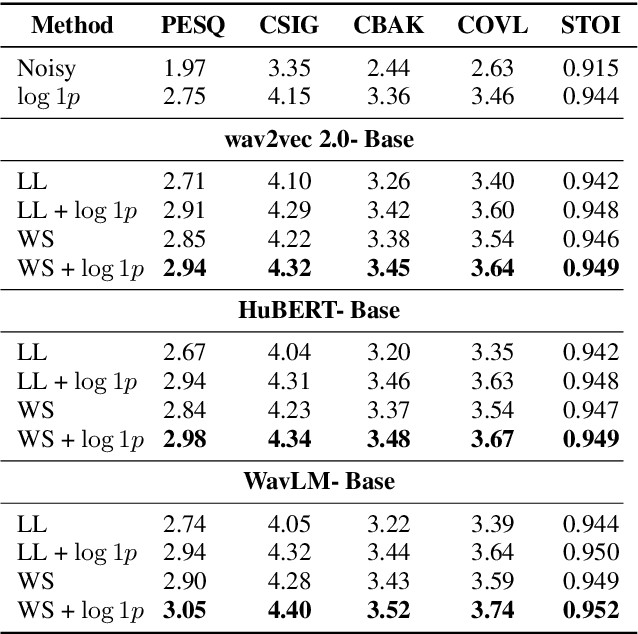
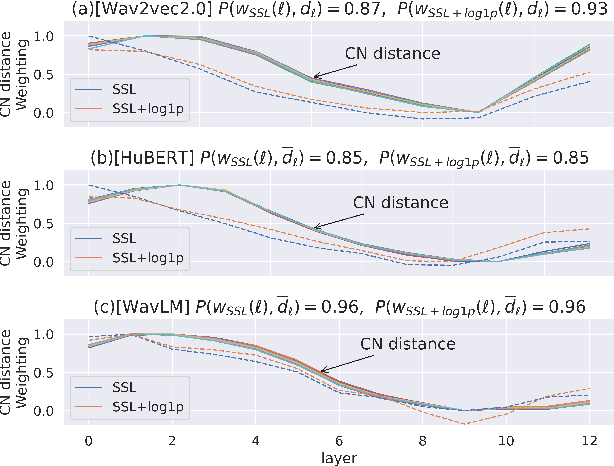
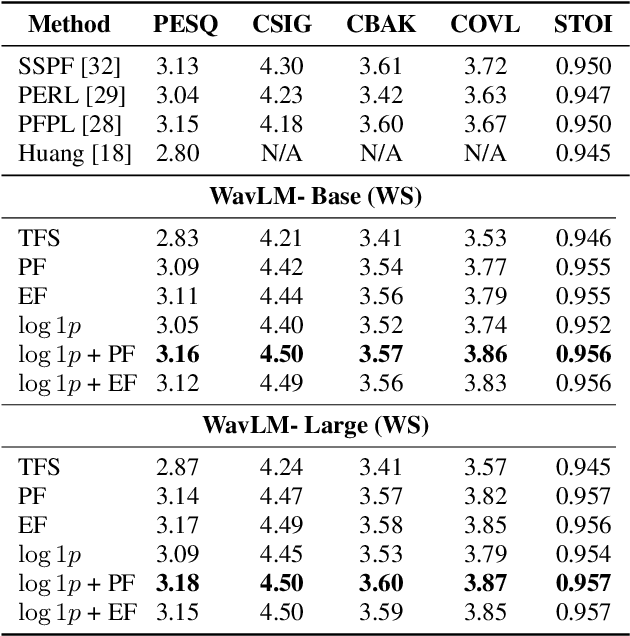
Self-supervised learning (SSL) representation for speech has achieved state-of-the-art (SOTA) performance on several downstream tasks. However, there remains room for improvement in speech enhancement (SE) tasks. In this study, we used a cross-domain feature to solve the problem that SSL embeddings may lack fine-grained information to regenerate speech signals. By integrating the SSL representation and spectrogram, the result can be significantly boosted. We further study the relationship between the noise robustness of SSL representation via clean-noisy distance (CN distance) and the layer importance for SE. Consequently, we found that SSL representations with lower noise robustness are more important. Furthermore, our experiments on the VCTK-DEMAND dataset demonstrated that fine-tuning an SSL representation with an SE model can outperform the SOTA SSL-based SE methods in PESQ, CSIG and COVL without invoking complicated network architectures. In later experiments, the CN distance in SSL embeddings was observed to increase after fine-tuning. These results verify our expectations and may help design SE-related SSL training in the future.
HASA-net: A non-intrusive hearing-aid speech assessment network
Nov 10, 2021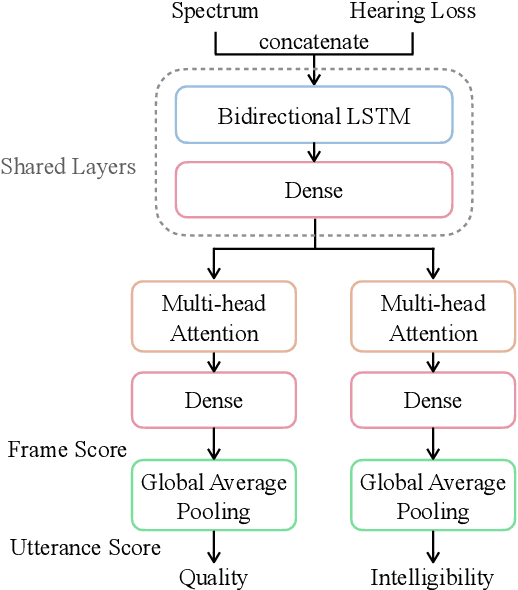
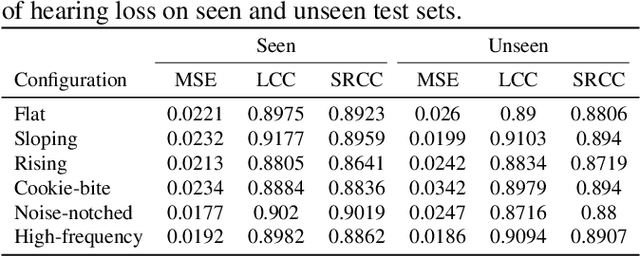
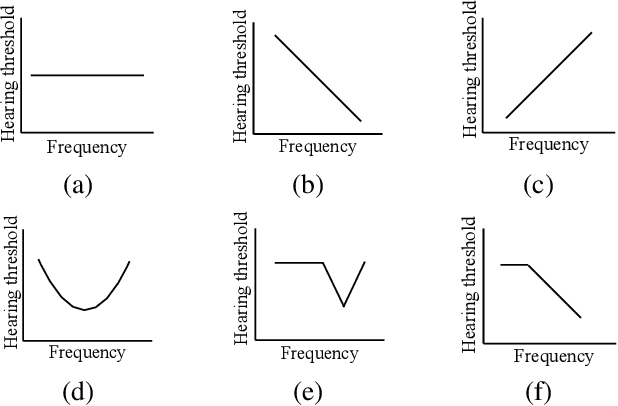
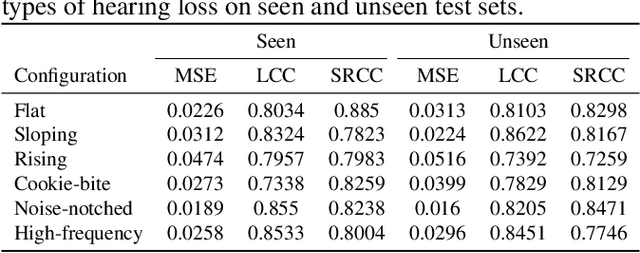
Without the need of a clean reference, non-intrusive speech assessment methods have caught great attention for objective evaluations. Recently, deep neural network (DNN) models have been applied to build non-intrusive speech assessment approaches and confirmed to provide promising performance. However, most DNN-based approaches are designed for normal-hearing listeners without considering hearing-loss factors. In this study, we propose a DNN-based hearing aid speech assessment network (HASA-Net), formed by a bidirectional long short-term memory (BLSTM) model, to predict speech quality and intelligibility scores simultaneously according to input speech signals and specified hearing-loss patterns. To the best of our knowledge, HASA-Net is the first work to incorporate quality and intelligibility assessments utilizing a unified DNN-based non-intrusive model for hearing aids. Experimental results show that the predicted speech quality and intelligibility scores of HASA-Net are highly correlated to two well-known intrusive hearing-aid evaluation metrics, hearing aid speech quality index (HASQI) and hearing aid speech perception index (HASPI), respectively.