 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic Knowledge Transfer Learning for Speech Enhancement
Mar 10, 2025Linguistic knowledge plays a crucial role in spoken language comprehension. It provides essential semantic and syntactic context for speech perception in noisy environments. However, most speech enhancement (SE) methods predominantly rely on acoustic features to learn the mapping relationship between noisy and clean speech, with limited exploration of linguistic integration. While text-informed SE approaches have been investigated, they often require explicit speech-text alignment or externally provided textual data, constraining their practicality in real-world scenarios. Additionally, using text as input poses challenges in aligning linguistic and acoustic representations due to their inherent differences. In this study, we propose the Cross-Modality Knowledge Transfer (CMKT) learning framework, which leverages pre-trained large language models (LLMs) to infuse linguistic knowledge into SE models without requiring text input or LLMs during inference. Furthermore, we introduce a misalignment strategy to improve knowledge transfer. This strategy applies controlled temporal shifts, encouraging the model to learn more robust representations. Experimental evaluations demonstrate that CMKT consistently outperforms baseline models across various SE architectures and LLM embeddings, highlighting its adaptability to different configurations. Additionally, results on Mandarin and English datasets confirm its effectiveness across diverse linguistic conditions, further validating its robustness. Moreover, CMKT remains effective even in scenarios without textual data, underscoring its practicality for real-world applications. By bridging the gap between linguistic and acoustic modalities, CMKT offers a scalable and innovative solution for integrating linguistic knowledge into SE models, leading to substantial improvements in both intelligibility and enhancement performance.
MECG-E: Mamba-based ECG Enhancer for Baseline Wander Removal
Sep 27, 2024Electrocardiogram (ECG) is an important non-invasive method for diagnosing cardiovascular disease. However, ECG signals are susceptible to noise contamination, such as electrical interference or signal wandering, which reduces diagnostic accuracy. Various ECG denoising methods have been proposed, but most existing methods yield suboptimal performance under very noisy conditions or require several steps during inference, leading to latency during online processing. In this paper, we propose a novel ECG denoising model, namely Mamba-based ECG Enhancer (MECG-E), which leverages the Mamba architecture known for its fast inference and outstanding nonlinear mapping capabilities. Experimental results indicate that MECG-E surpasses several well-known existing models across multiple metrics under different noise conditions. Additionally, MECG-E requires less inference time than state-of-the-art diffusion-based ECG denoisers, demonstrating the model's functionality and efficiency.
Boosting Self-Supervised Embeddings for Speech Enhancement
Apr 07, 2022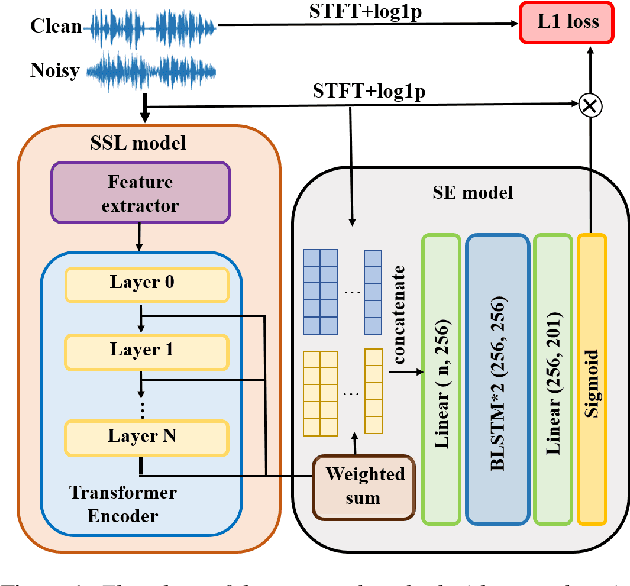
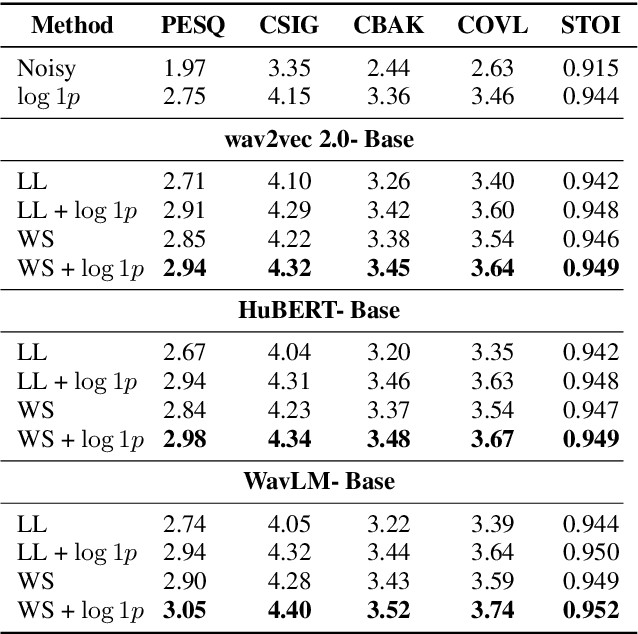
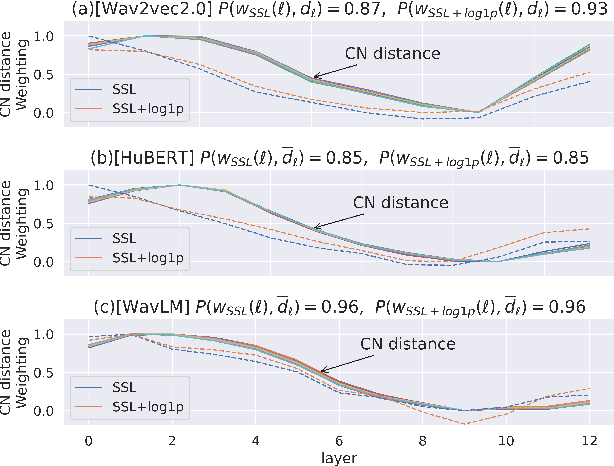
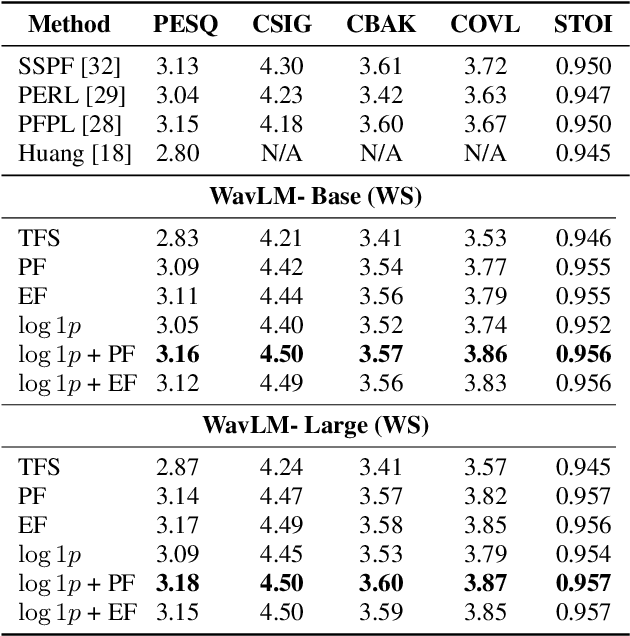
Self-supervised learning (SSL) representation for speech has achieved state-of-the-art (SOTA) performance on several downstream tasks. However, there remains room for improvement in speech enhancement (SE) tasks. In this study, we used a cross-domain feature to solve the problem that SSL embeddings may lack fine-grained information to regenerate speech signals. By integrating the SSL representation and spectrogram, the result can be significantly boosted. We further study the relationship between the noise robustness of SSL representation via clean-noisy distance (CN distance) and the layer importance for SE. Consequently, we found that SSL representations with lower noise robustness are more important. Furthermore, our experiments on the VCTK-DEMAND dataset demonstrated that fine-tuning an SSL representation with an SE model can outperform the SOTA SSL-based SE methods in PESQ, CSIG and COVL without invoking complicated network architectures. In later experiments, the CN distance in SSL embeddings was observed to increase after fine-tuning. These results verify our expectations and may help design SE-related SSL training in the future.