 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech-Hands: A Self-Reflection Voice Agentic Approach to Speech Recognition and Audio Reasoning with Omni Perception
Jan 14, 2026We introduce a voice-agentic framework that learns one critical omni-understanding skill: knowing when to trust itself versus when to consult external audio perception. Our work is motivated by a crucial yet counterintuitive finding: naively fine-tuning an omni-model on both speech recognition and external sound understanding tasks often degrades performance, as the model can be easily misled by noisy hypotheses. To address this, our framework, Speech-Hands, recasts the problem as an explicit self-reflection decision. This learnable reflection primitive proves effective in preventing the model from being derailed by flawed external candidates. We show that this agentic action mechanism generalizes naturally from speech recognition to complex, multiple-choice audio reasoning. Across the OpenASR leaderboard, Speech-Hands consistently outperforms strong baselines by 12.1% WER on seven benchmarks. The model also achieves 77.37% accuracy and high F1 on audio QA decisions, showing robust generalization and reliability across diverse audio question answering datasets. By unifying perception and decision-making, our work offers a practical path toward more reliable and resilient audio intelligence.
Boosting Self-Supervised Embeddings for Speech Enhancement
Apr 07, 2022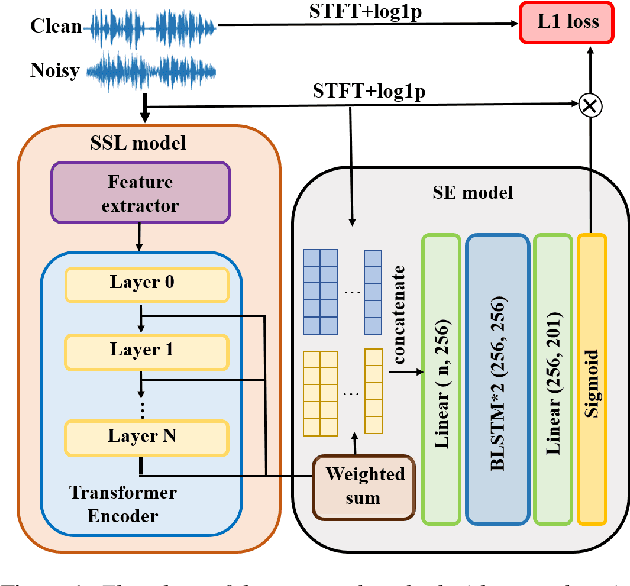
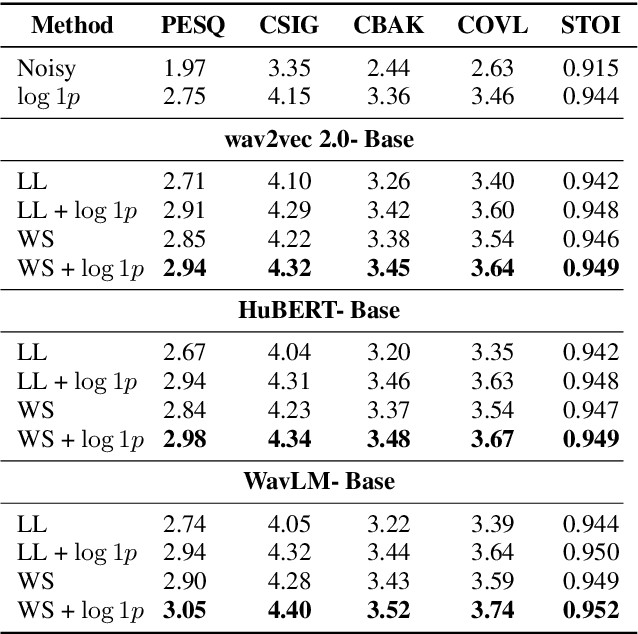
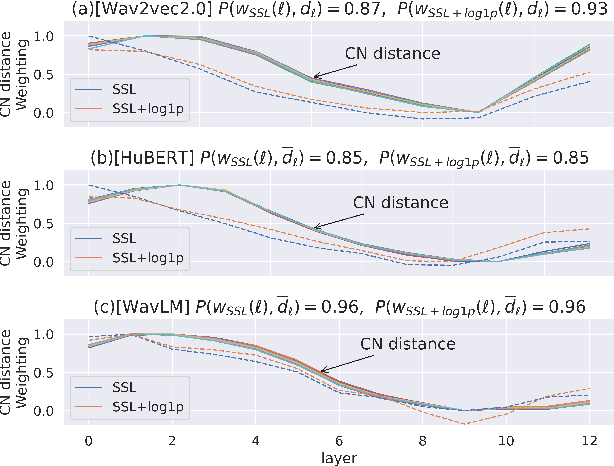
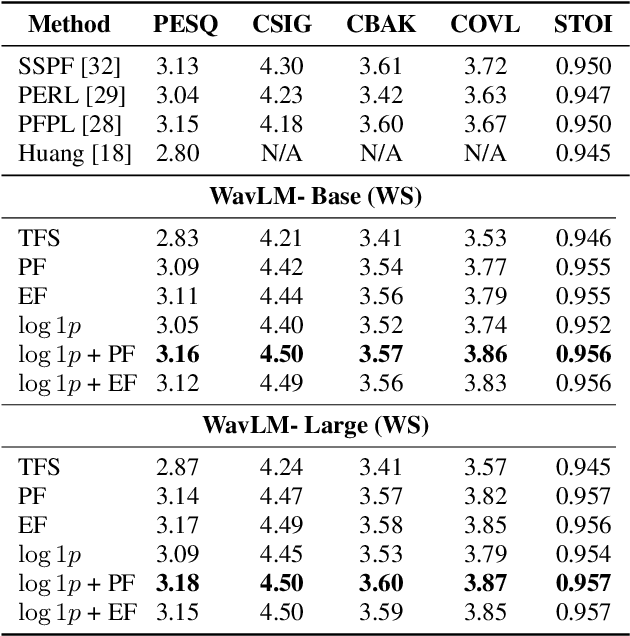
Self-supervised learning (SSL) representation for speech has achieved state-of-the-art (SOTA) performance on several downstream tasks. However, there remains room for improvement in speech enhancement (SE) tasks. In this study, we used a cross-domain feature to solve the problem that SSL embeddings may lack fine-grained information to regenerate speech signals. By integrating the SSL representation and spectrogram, the result can be significantly boosted. We further study the relationship between the noise robustness of SSL representation via clean-noisy distance (CN distance) and the layer importance for SE. Consequently, we found that SSL representations with lower noise robustness are more important. Furthermore, our experiments on the VCTK-DEMAND dataset demonstrated that fine-tuning an SSL representation with an SE model can outperform the SOTA SSL-based SE methods in PESQ, CSIG and COVL without invoking complicated network architectures. In later experiments, the CN distance in SSL embeddings was observed to increase after fine-tuning. These results verify our expectations and may help design SE-related SSL training in the future.
MTI-Net: A Multi-Target Speech Intelligibility Prediction Model
Apr 07, 2022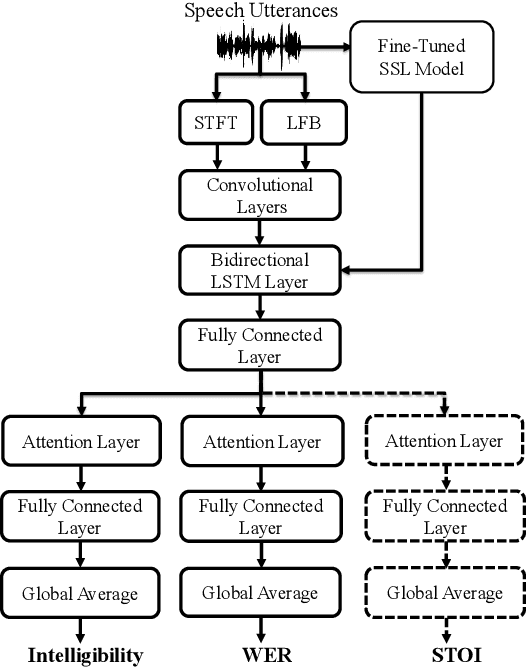
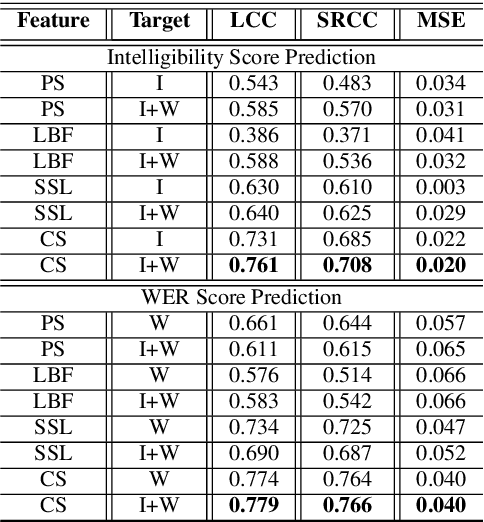
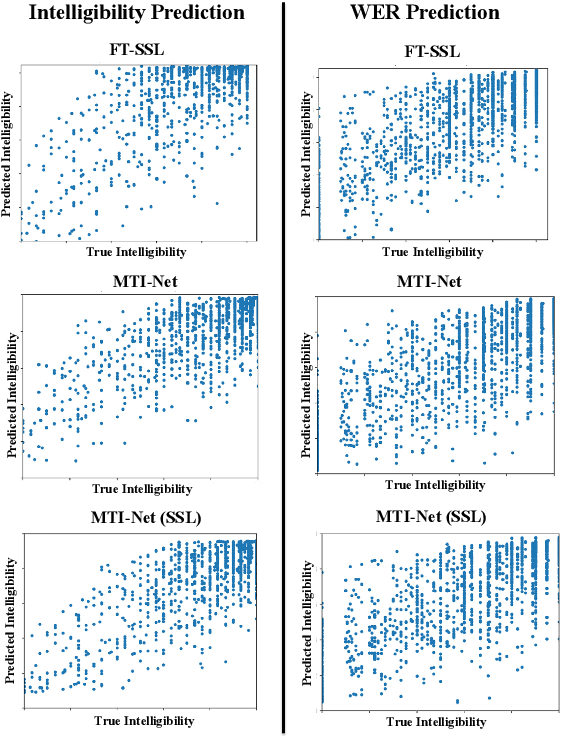
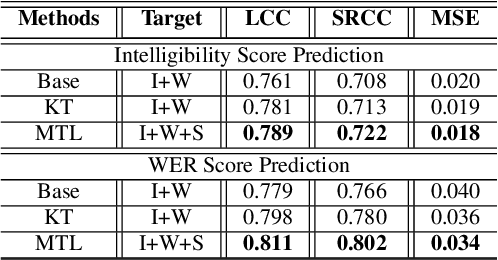
Recently, deep learning (DL)-based non-intrusive speech assessment models have attracted great attention. Many studies report that these DL-based models yield satisfactory assessment performance and good flexibility, but their performance in unseen environments remains a challenge. Furthermore, compared to quality scores, fewer studies elaborate deep learning models to estimate intelligibility scores. This study proposes a multi-task speech intelligibility prediction model, called MTI-Net, for simultaneously predicting human and machine intelligibility measures. Specifically, given a speech utterance, MTI-Net is designed to predict subjective listening test results and word error rate (WER) scores. We also investigate several methods that can improve the prediction performance of MTI-Net. First, we compare different features (including low-level features and embeddings from self-supervised learning (SSL) models) and prediction targets of MTI-Net. Second, we explore the effect of transfer learning and multi-tasking learning on training MTI-Net. Finally, we examine the potential advantages of fine-tuning SSL embeddings. Experimental results demonstrate the effectiveness of using cross-domain features, multi-task learning, and fine-tuning SSL embeddings. Furthermore, it is confirmed that the intelligibility and WER scores predicted by MTI-Net are highly correlated with the ground-truth scores.