 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Learning with Partially Labeled Data: A Conditional Distillation Approach
Dec 25, 2024



In medical imaging, developing generalized segmentation models that can handle multiple organs and lesions is crucial. However, the scarcity of fully annotated datasets and strict privacy regulations present significant barriers to data sharing. Federated Learning (FL) allows decentralized model training, but existing FL methods often struggle with partial labeling, leading to model divergence and catastrophic forgetting. We propose ConDistFL, a novel FL framework incorporating conditional distillation to address these challenges. ConDistFL enables effective learning from partially labeled datasets, significantly improving segmentation accuracy across distributed and non-uniform datasets. In addition to its superior segmentation performance, ConDistFL maintains computational and communication efficiency, ensuring its scalability for real-world applications. Furthermore, ConDistFL demonstrates remarkable generalizability, significantly outperforming existing FL methods in out-of-federation tests, even adapting to unseen contrast phases (e.g., non-contrast CT images) in our experiments. Extensive evaluations on 3D CT and 2D chest X-ray datasets show that ConDistFL is an efficient, adaptable solution for collaborative medical image segmentation in privacy-constrained settings.
A Study on Incorporating Whisper for Robust Speech Assessment
Sep 22, 2023



This research introduces an enhanced version of the multi-objective speech assessment model, called MOSA-Net+, by leveraging the acoustic features from large pre-trained weakly supervised models, namely Whisper, to create embedding features. The first part of this study investigates the correlation between the embedding features of Whisper and two self-supervised learning (SSL) models with subjective quality and intelligibility scores. The second part evaluates the effectiveness of Whisper in deploying a more robust speech assessment model. Third, the possibility of combining representations from Whisper and SSL models while deploying MOSA-Net+ is analyzed. The experimental results reveal that Whisper's embedding features correlate more strongly with subjective quality and intelligibility than other SSL's embedding features, contributing to more accurate prediction performance achieved by MOSA-Net+. Moreover, combining the embedding features from Whisper and SSL models only leads to marginal improvement. As compared to MOSA-Net and other SSL-based speech assessment models, MOSA-Net+ yields notable improvements in estimating subjective quality and intelligibility scores across all evaluation metrics. We further tested MOSA-Net+ on Track 3 of the VoiceMOS Challenge 2023 and obtained the top-ranked performance.
Utilizing Whisper to Enhance Multi-Branched Speech Intelligibility Prediction Model for Hearing Aids
Sep 18, 2023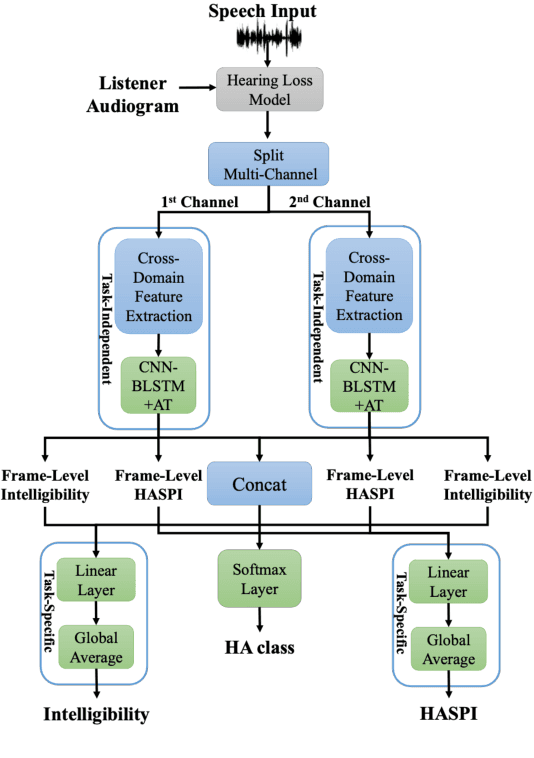
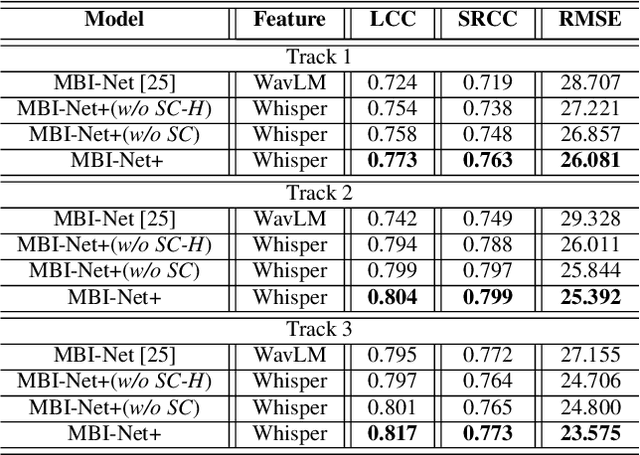
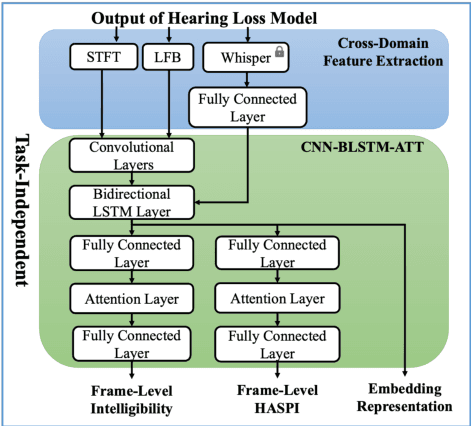
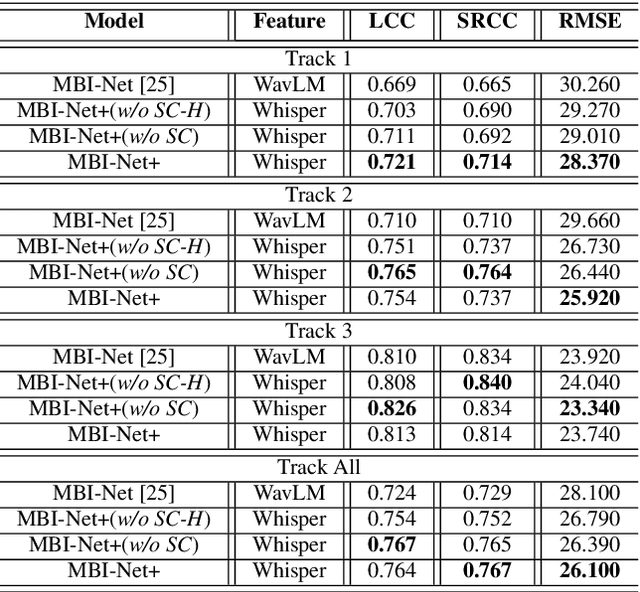
Automated assessment of speech intelligibility in hearing aid (HA) devices is of great importance. Our previous work introduced a non-intrusive multi-branched speech intelligibility prediction model called MBI-Net, which achieved top performance in the Clarity Prediction Challenge 2022. Based on the promising results of the MBI-Net model, we aim to further enhance its performance by leveraging Whisper embeddings to enrich acoustic features. In this study, we propose two improved models, namely MBI-Net+ and MBI-Net++. MBI-Net+ maintains the same model architecture as MBI-Net, but replaces self-supervised learning (SSL) speech embeddings with Whisper embeddings to deploy cross-domain features. On the other hand, MBI-Net++ further employs a more elaborate design, incorporating an auxiliary task to predict frame-level and utterance-level scores of the objective speech intelligibility metric HASPI (Hearing Aid Speech Perception Index) and multi-task learning. Experimental results confirm that both MBI-Net++ and MBI-Net+ achieve better prediction performance than MBI-Net in terms of multiple metrics, and MBI-Net++ is better than MBI-Net+.
Multi-Task Pseudo-Label Learning for Non-Intrusive Speech Quality Assessment Model
Aug 18, 2023This study introduces multi-task pseudo-label (MPL) learning for a non-intrusive speech quality assessment model. MPL consists of two stages which are obtaining pseudo-label scores from a pretrained model and performing multi-task learning. The 3QUEST metrics, namely Speech-MOS (S-MOS), Noise-MOS (N-MOS), and General-MOS (G-MOS) are selected as the primary ground-truth labels. Additionally, the pretrained MOSA-Net model is utilized to estimate three pseudo-labels: perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI). Multi-task learning stage of MPL is then employed to train the MTQ-Net model (multi-target speech quality assessment network). The model is optimized by incorporating Loss supervision (derived from the difference between the estimated score and the real ground-truth labels) and Loss semi-supervision (derived from the difference between the estimated score and pseudo-labels), where Huber loss is employed to calculate the loss function. Experimental results first demonstrate the advantages of MPL compared to training the model from scratch and using knowledge transfer mechanisms. Secondly, the benefits of Huber Loss in improving the prediction model of MTQ-Net are verified. Finally, the MTQ-Net with the MPL approach exhibits higher overall prediction capabilities when compared to other SSL-based speech assessment models.
ConDistFL: Conditional Distillation for Federated Learning from Partially Annotated Data
Aug 08, 2023



Developing a generalized segmentation model capable of simultaneously delineating multiple organs and diseases is highly desirable. Federated learning (FL) is a key technology enabling the collaborative development of a model without exchanging training data. However, the limited access to fully annotated training data poses a major challenge to training generalizable models. We propose "ConDistFL", a framework to solve this problem by combining FL with knowledge distillation. Local models can extract the knowledge of unlabeled organs and tumors from partially annotated data from the global model with an adequately designed conditional probability representation. We validate our framework on four distinct partially annotated abdominal CT datasets from the MSD and KiTS19 challenges. The experimental results show that the proposed framework significantly outperforms FedAvg and FedOpt baselines. Moreover, the performance on an external test dataset demonstrates superior generalizability compared to models trained on each dataset separately. Our ablation study suggests that ConDistFL can perform well without frequent aggregation, reducing the communication cost of FL. Our implementation will be available at https://github.com/NVIDIA/NVFlare/tree/dev/research/condist-fl.
MTI-Net: A Multi-Target Speech Intelligibility Prediction Model
Apr 07, 2022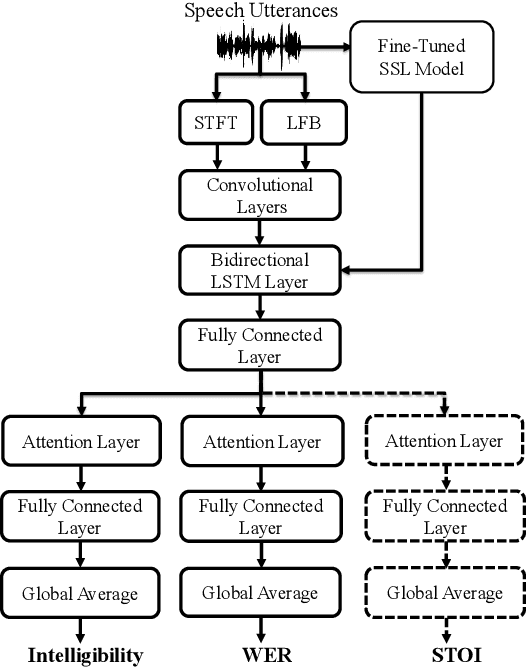
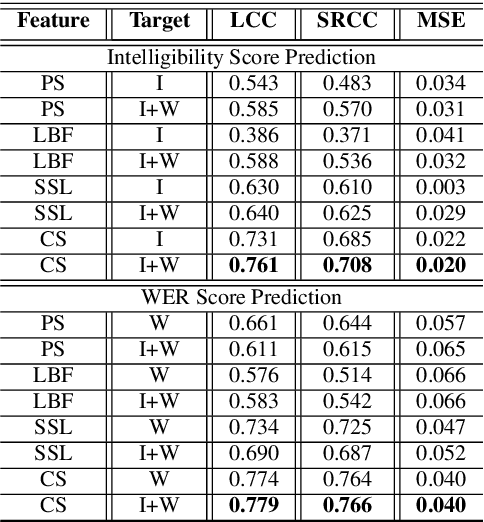
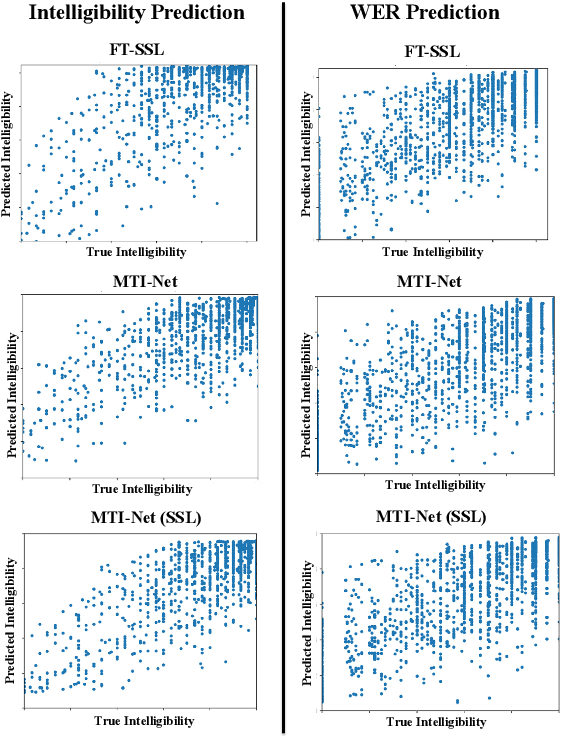
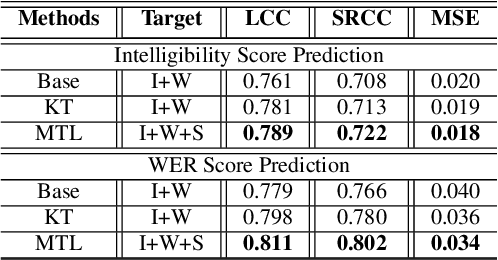
Recently, deep learning (DL)-based non-intrusive speech assessment models have attracted great attention. Many studies report that these DL-based models yield satisfactory assessment performance and good flexibility, but their performance in unseen environments remains a challenge. Furthermore, compared to quality scores, fewer studies elaborate deep learning models to estimate intelligibility scores. This study proposes a multi-task speech intelligibility prediction model, called MTI-Net, for simultaneously predicting human and machine intelligibility measures. Specifically, given a speech utterance, MTI-Net is designed to predict subjective listening test results and word error rate (WER) scores. We also investigate several methods that can improve the prediction performance of MTI-Net. First, we compare different features (including low-level features and embeddings from self-supervised learning (SSL) models) and prediction targets of MTI-Net. Second, we explore the effect of transfer learning and multi-tasking learning on training MTI-Net. Finally, we examine the potential advantages of fine-tuning SSL embeddings. Experimental results demonstrate the effectiveness of using cross-domain features, multi-task learning, and fine-tuning SSL embeddings. Furthermore, it is confirmed that the intelligibility and WER scores predicted by MTI-Net are highly correlated with the ground-truth scores.
MBI-Net: A Non-Intrusive Multi-Branched Speech Intelligibility Prediction Model for Hearing Aids
Apr 07, 2022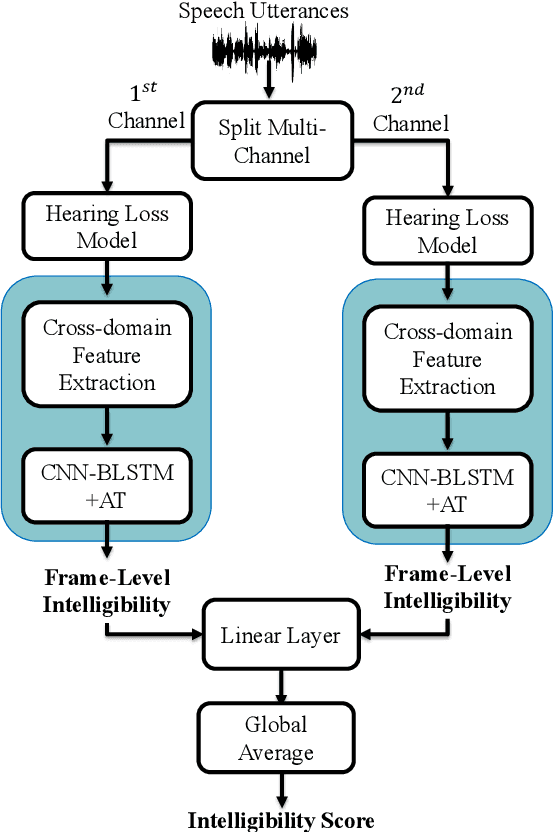
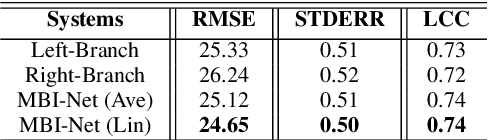
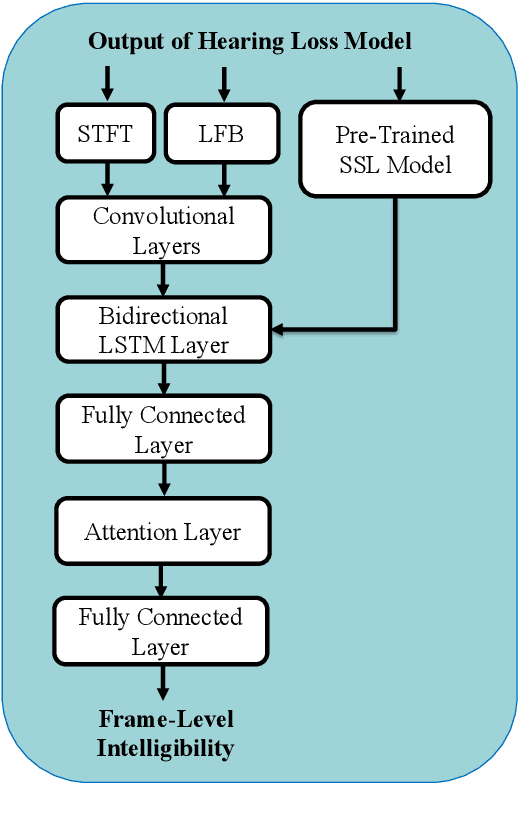
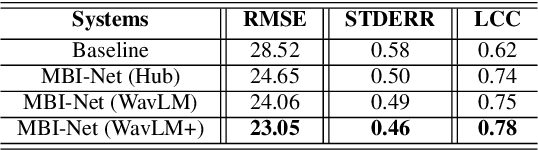
Improving the user's hearing ability to understand speech in noisy environments is critical to the development of hearing aid (HA) devices. For this, it is important to derive a metric that can fairly predict speech intelligibility for HA users. A straightforward approach is to conduct a subjective listening test and use the test results as an evaluation metric. However, conducting large-scale listening tests is time-consuming and expensive. Therefore, several evaluation metrics were derived as surrogates for subjective listening test results. In this study, we propose a multi-branched speech intelligibility prediction model (MBI-Net), for predicting the subjective intelligibility scores of HA users. MBI-Net consists of two branches of models, with each branch consisting of a hearing loss model, a cross-domain feature extraction module, and a speech intelligibility prediction model, to process speech signals from one channel. The outputs of the two branches are fused through a linear layer to obtain predicted speech intelligibility scores. Experimental results confirm the effectiveness of MBI-Net, which produces higher prediction scores than the baseline system in Track 1 and Track 2 on the Clarity Prediction Challenge 2022 dataset.
Deep Learning-based Non-Intrusive Multi-Objective Speech Assessment Model with Cross-Domain Features
Dec 01, 2021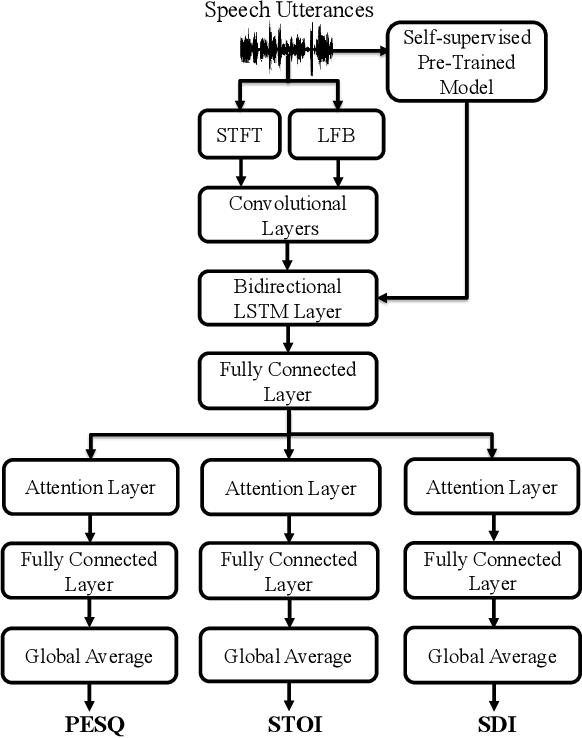
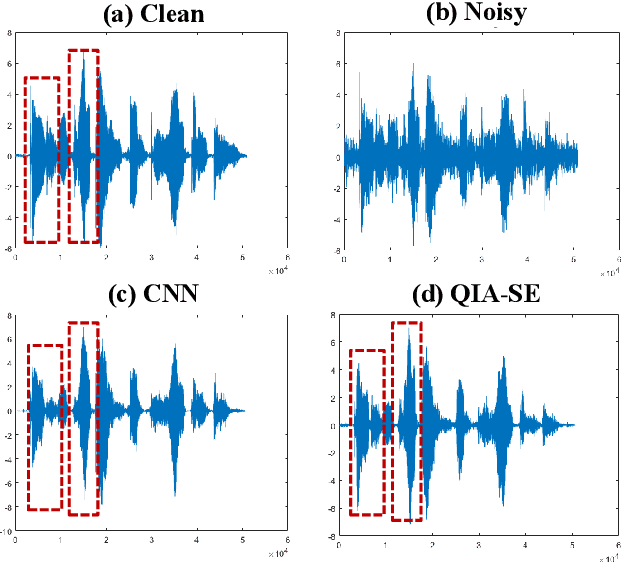
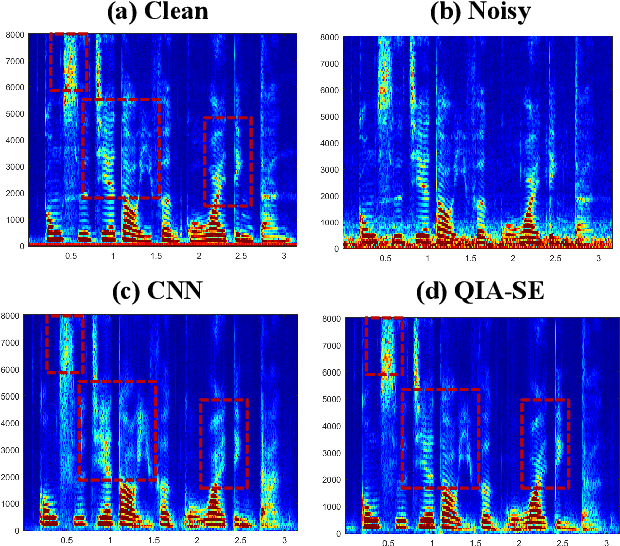
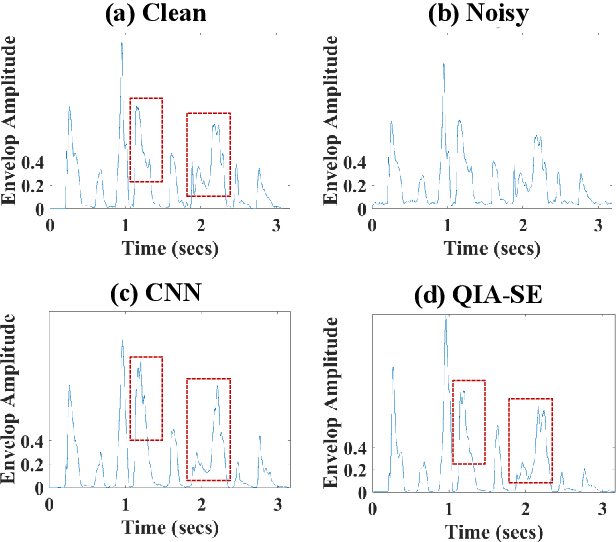
In this study, we propose a cross-domain multi-objective speech assessment model called MOSA-Net, which can estimate multiple speech assessment metrics simultaneously. More specifically, MOSA-Net is designed to estimate the speech quality, intelligibility, and distortion assessment scores of an input test speech signal. It comprises a convolutional neural network and bidirectional long short-term memory (CNN-BLSTM) architecture for representation extraction, and a multiplicative attention layer and a fully-connected layer for each assessment metric. In addition, cross-domain features (spectral and time-domain features) and latent representations from self-supervised learned models are used as inputs to combine rich acoustic information from different speech representations to obtain more accurate assessments. Experimental results show that MOSA-Net can precisely predict perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI) scores when tested on noisy and enhanced speech utterances under either seen test conditions or unseen test conditions. Moreover, MOSA-Net, originally trained to assess objective scores, can be used as a pre-trained model to be effectively adapted to an assessment model for predicting subjective quality and intelligibility scores with a limited amount of training data. In light of the confirmed prediction capability, we further adopt the latent representations of MOSA-Net to guide the speech enhancement (SE) process and derive a quality-intelligibility (QI)-aware SE (QIA-SE) approach accordingly. Experimental results show that QIA-SE provides superior enhancement performance compared with the baseline SE system in terms of objective evaluation metrics and qualitative evaluation test.
Multi-task Federated Learning for Heterogeneous Pancreas Segmentation
Aug 19, 2021
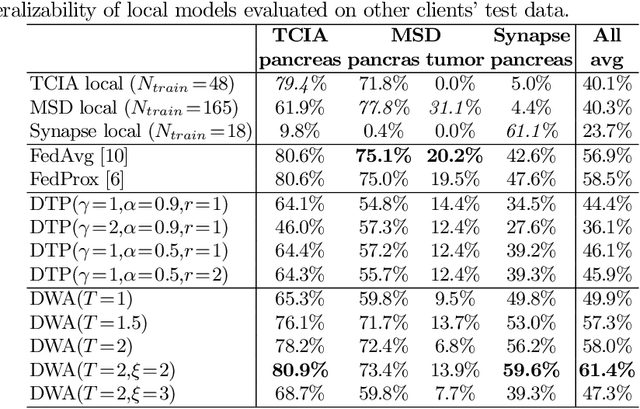
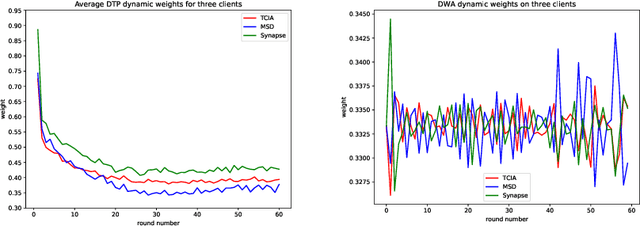

Federated learning (FL) for medical image segmentation becomes more challenging in multi-task settings where clients might have different categories of labels represented in their data. For example, one client might have patient data with "healthy'' pancreases only while datasets from other clients may contain cases with pancreatic tumors. The vanilla federated averaging algorithm makes it possible to obtain more generalizable deep learning-based segmentation models representing the training data from multiple institutions without centralizing datasets. However, it might be sub-optimal for the aforementioned multi-task scenarios. In this paper, we investigate heterogeneous optimization methods that show improvements for the automated segmentation of pancreas and pancreatic tumors in abdominal CT images with FL settings.
Speech Enhancement with Zero-Shot Model Selection
Dec 17, 2020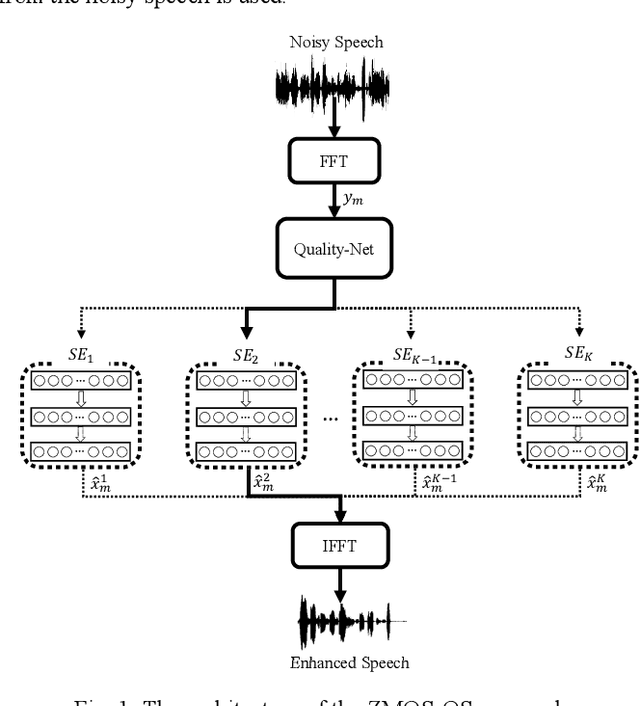
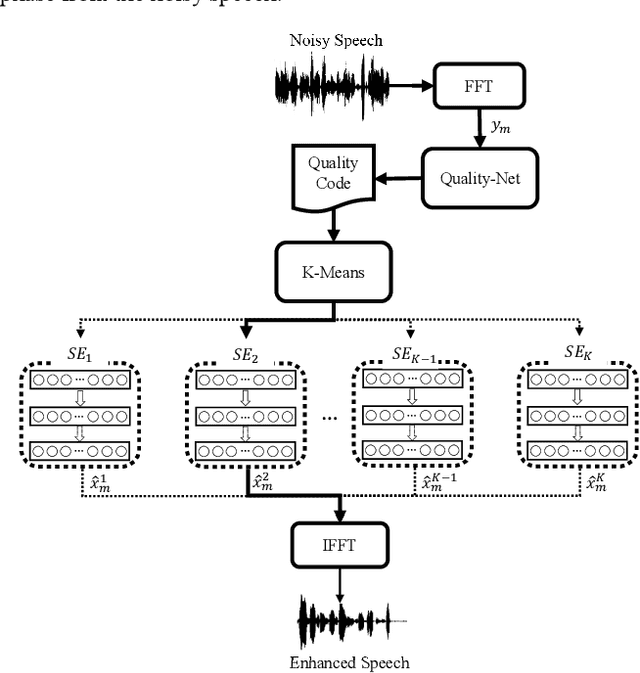
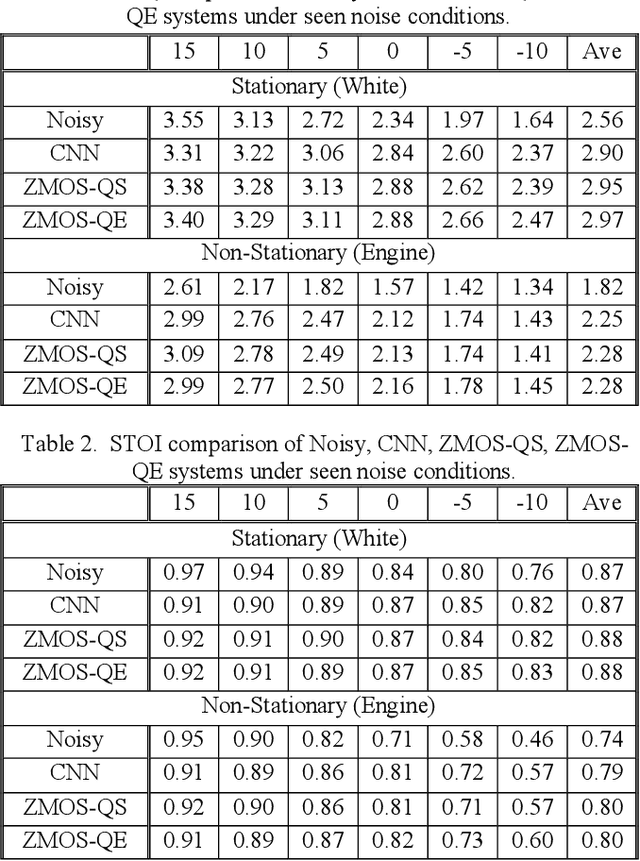
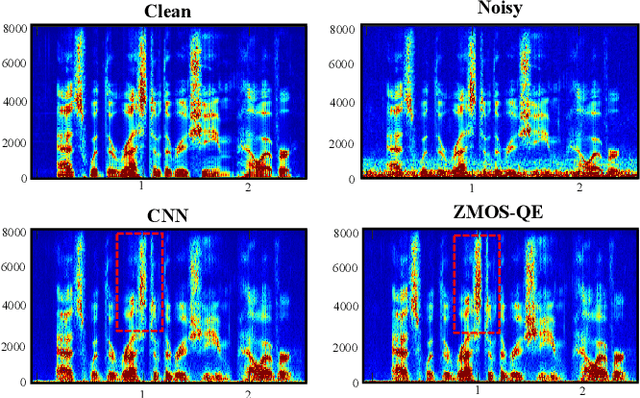
Recent research on speech enhancement (SE) has seen the emergence of deep learning-based methods. It is still a challenging task to determine effective ways to increase the generalizability of SE under diverse test conditions. In this paper, we combine zero-shot learning and ensemble learning to propose a zero-shot model selection (ZMOS) approach to increase the generalization of SE performance. The proposed approach is realized in two phases, namely offline and online phases. The offline phase clusters the entire set of training data into multiple subsets, and trains a specialized SE model (termed component SE model) with each subset. The online phase selects the most suitable component SE model to carry out enhancement. Two selection strategies are developed: selection based on quality score (QS) and selection based on quality embedding (QE). Both QS and QE are obtained by a Quality-Net, a non-intrusive quality assessment network. In the offline phase, the QS or QE of a train-ing utterance is used to group the training data into clusters. In the online phase, the QS or QE of the test utterance is used to identify the appropriate component SE model to perform enhancement on the test utterance. Experimental results have confirmed that the proposed ZMOS approach can achieve better performance in both seen and unseen noise types compared to the baseline systems, which indicates the effectiveness of the proposed approach to provide robust SE performance.