 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning-based Non-Intrusive Multi-Objective Speech Assessment Model with Cross-Domain Features
Paper and Code
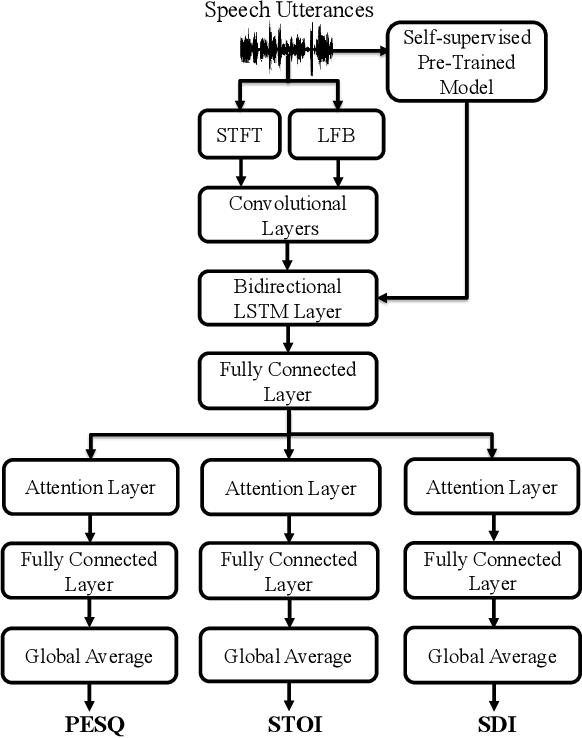
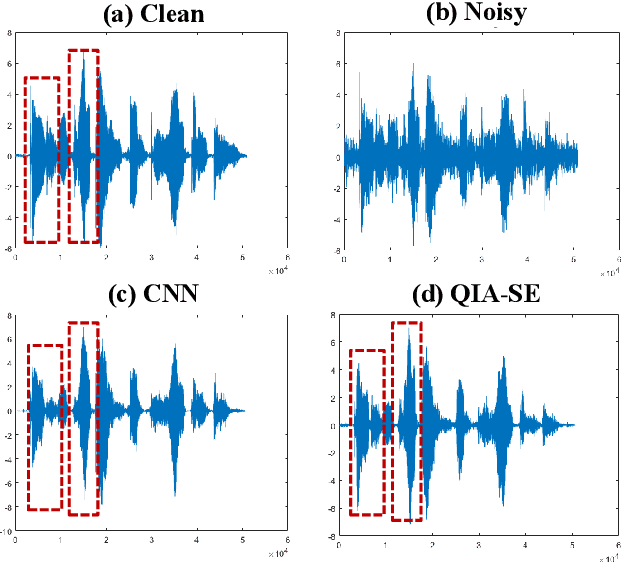
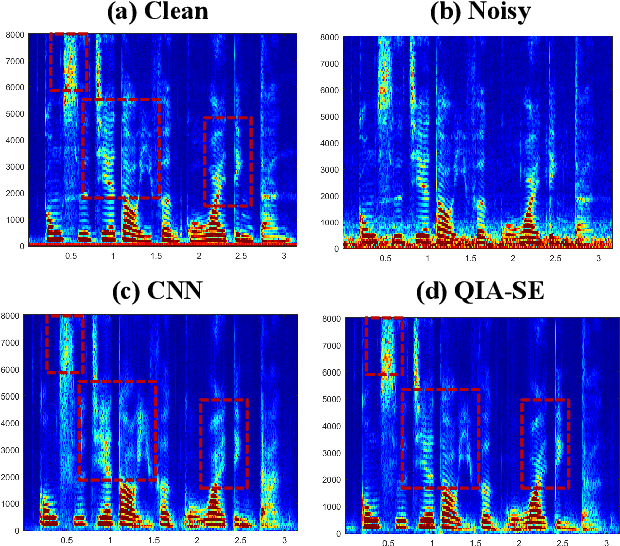
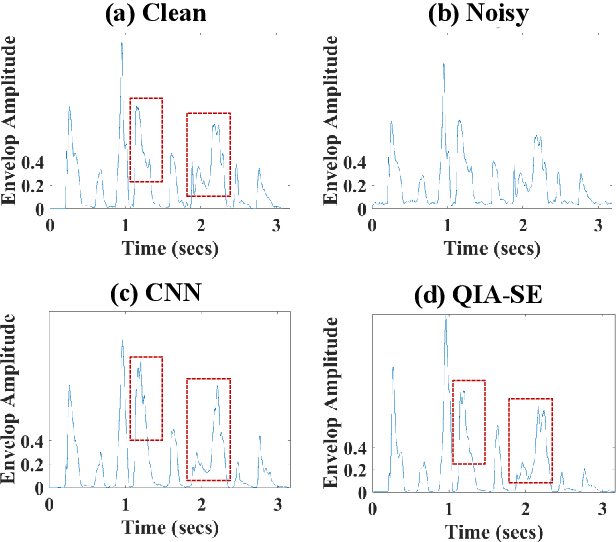
In this study, we propose a cross-domain multi-objective speech assessment model called MOSA-Net, which can estimate multiple speech assessment metrics simultaneously. More specifically, MOSA-Net is designed to estimate the speech quality, intelligibility, and distortion assessment scores of an input test speech signal. It comprises a convolutional neural network and bidirectional long short-term memory (CNN-BLSTM) architecture for representation extraction, and a multiplicative attention layer and a fully-connected layer for each assessment metric. In addition, cross-domain features (spectral and time-domain features) and latent representations from self-supervised learned models are used as inputs to combine rich acoustic information from different speech representations to obtain more accurate assessments. Experimental results show that MOSA-Net can precisely predict perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI) scores when tested on noisy and enhanced speech utterances under either seen test conditions or unseen test conditions. Moreover, MOSA-Net, originally trained to assess objective scores, can be used as a pre-trained model to be effectively adapted to an assessment model for predicting subjective quality and intelligibility scores with a limited amount of training data. In light of the confirmed prediction capability, we further adopt the latent representations of MOSA-Net to guide the speech enhancement (SE) process and derive a quality-intelligibility (QI)-aware SE (QIA-SE) approach accordingly. Experimental results show that QIA-SE provides superior enhancement performance compared with the baseline SE system in terms of objective evaluation metrics and qualitative evaluation test.