 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-Shot and Pseudo-Label Guided Speech Quality Evaluation with Large Language Models
Apr 15, 2026In this paper, we introduce GatherMOS, a novel framework that leverages large language models (LLM) as meta-evaluators to aggregate diverse signals into quality predictions. GatherMOS integrates lightweight acoustic descriptors with pseudo-labels from DNSMOS and VQScore, enabling the LLM to reason over heterogeneous inputs and infer perceptual mean opinion scores (MOS). We further explore both zero-shot and few-shot in-context learning setups, showing that zero-shot GatherMOS maintains stable performance across diverse conditions, while few-shot guidance yields large gains when support samples match the test conditions. Experiments on the VoiceBank-DEMAND dataset demonstrate that GatherMOS consistently outperforms DNSMOS, VQScore, naive score averaging, and even learning-based models such as CNN-BLSTM and MOS-SSL when trained under limited labeled-data conditions. These results highlight the potential of LLM-based aggregation as a practical strategy for non-intrusive speech quality evaluation.
MOS-Bias: From Hidden Gender Bias to Gender-Aware Speech Quality Assessment
Mar 11, 2026The Mean Opinion Score (MOS) serves as the standard metric for speech quality assessment, yet biases in human annotations remain underexplored. We conduct the first systematic analysis of gender bias in MOS, revealing that male listeners consistently assign higher scores than female listeners--a gap that is most pronounced in low-quality speech and gradually diminishes as quality improves. This quality-dependent structure proves difficult to eliminate through simple calibration. We further demonstrate that automated MOS models trained on aggregated labels exhibit predictions skewed toward male standards of perception. To address this, we propose a gender-aware model that learns gender-specific scoring patterns through abstracting binary group embeddings, thereby improving overall and gender-specific prediction accuracy. This study establishes that gender bias in MOS constitutes a systematic, learnable pattern demanding attention in equitable speech evaluation.
Improving Perceptual Audio Aesthetic Assessment via Triplet Loss and Self-Supervised Embeddings
Sep 03, 2025We present a system for automatic multi-axis perceptual quality prediction of generative audio, developed for Track 2 of the AudioMOS Challenge 2025. The task is to predict four Audio Aesthetic Scores--Production Quality, Production Complexity, Content Enjoyment, and Content Usefulness--for audio generated by text-to-speech (TTS), text-to-audio (TTA), and text-to-music (TTM) systems. A main challenge is the domain shift between natural training data and synthetic evaluation data. To address this, we combine BEATs, a pretrained transformer-based audio representation model, with a multi-branch long short-term memory (LSTM) predictor and use a triplet loss with buffer-based sampling to structure the embedding space by perceptual similarity. Our results show that this improves embedding discriminability and generalization, enabling domain-robust audio quality assessment without synthetic training data.
A Study on Speech Assessment with Visual Cues
Jun 11, 2025Non-intrusive assessment of speech quality and intelligibility is essential when clean reference signals are unavailable. In this work, we propose a multimodal framework that integrates audio features and visual cues to predict PESQ and STOI scores. It employs a dual-branch architecture, where spectral features are extracted using STFT, and visual embeddings are obtained via a visual encoder. These features are then fused and processed by a CNN-BLSTM with attention, followed by multi-task learning to simultaneously predict PESQ and STOI. Evaluations on the LRS3-TED dataset, augmented with noise from the DEMAND corpus, show that our model outperforms the audio-only baseline. Under seen noise conditions, it improves LCC by 9.61% (0.8397->0.9205) for PESQ and 11.47% (0.7403->0.8253) for STOI. These results highlight the effectiveness of incorporating visual cues in enhancing the accuracy of non-intrusive speech assessment.
A Study on Zero-shot Non-intrusive Speech Assessment using Large Language Models
Sep 16, 2024This work investigates two strategies for zero-shot non-intrusive speech assessment leveraging large language models. First, we explore the audio analysis capabilities of GPT-4o. Second, we propose GPT-Whisper, which uses Whisper as an audio-to-text module and evaluates the naturalness of text via targeted prompt engineering. We evaluate assessment metrics predicted by GPT-4o and GPT-Whisper examining their correlations with human-based quality and intelligibility assessments, and character error rate (CER) of automatic speech recognition. Experimental results show that GPT-4o alone is not effective for audio analysis; whereas, GPT-Whisper demonstrates higher prediction, showing moderate correlation with speech quality and intelligibility, and high correlation with CER. Compared to supervised non-intrusive neural speech assessment models, namely MOS-SSL and MTI-Net, GPT-Whisper yields a notably higher Spearman's rank correlation with the CER of Whisper. These findings validate GPT-Whisper as a reliable method for accurate zero-shot speech assessment without requiring additional training data (speech data and corresponding assessment scores).
The VoiceMOS Challenge 2024: Beyond Speech Quality Prediction
Sep 11, 2024



We present the third edition of the VoiceMOS Challenge, a scientific initiative designed to advance research into automatic prediction of human speech ratings. There were three tracks. The first track was on predicting the quality of ``zoomed-in'' high-quality samples from speech synthesis systems. The second track was to predict ratings of samples from singing voice synthesis and voice conversion with a large variety of systems, listeners, and languages. The third track was semi-supervised quality prediction for noisy, clean, and enhanced speech, where a very small amount of labeled training data was provided. Among the eight teams from both academia and industry, we found that many were able to outperform the baseline systems. Successful techniques included retrieval-based methods and the use of non-self-supervised representations like spectrograms and pitch histograms. These results showed that the challenge has advanced the field of subjective speech rating prediction.
HAAQI-Net: A non-intrusive neural music quality assessment model for hearing aids
Jan 02, 2024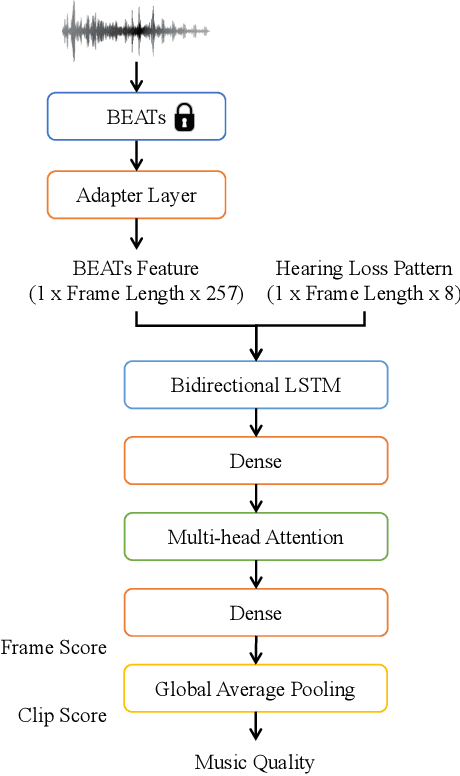
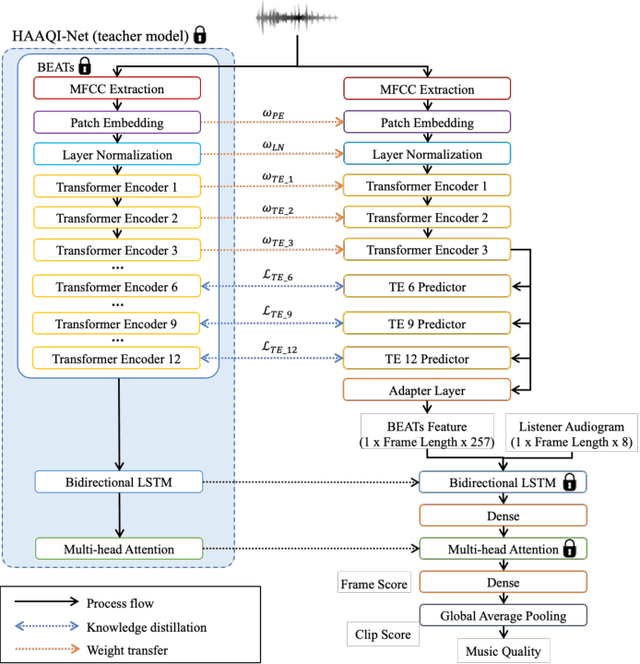
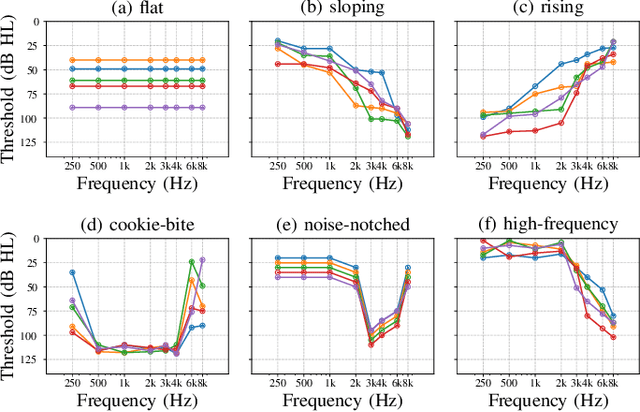
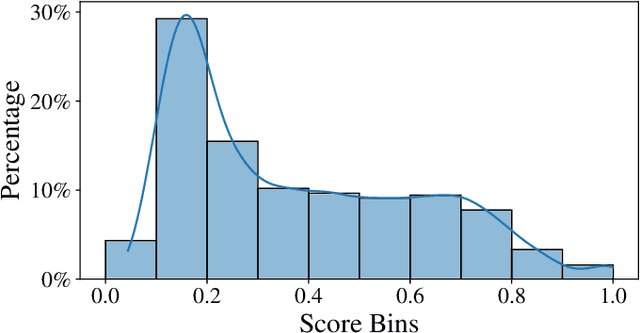
This paper introduces HAAQI-Net, a non-intrusive deep learning model for music quality assessment tailored to hearing aid users. In contrast to traditional methods like the Hearing Aid Audio Quality Index (HAAQI), HAAQI-Net utilizes a Bidirectional Long Short-Term Memory (BLSTM) with attention. It takes an assessed music sample and a hearing loss pattern as input, generating a predicted HAAQI score. The model employs the pre-trained Bidirectional Encoder representation from Audio Transformers (BEATs) for acoustic feature extraction. Comparing predicted scores with ground truth, HAAQI-Net achieves a Longitudinal Concordance Correlation (LCC) of 0.9257, Spearman's Rank Correlation Coefficient (SRCC) of 0.9394, and Mean Squared Error (MSE) of 0.0080. Notably, this high performance comes with a substantial reduction in inference time: from 62.52 seconds (by HAAQI) to 2.71 seconds (by HAAQI-Net), serving as an efficient music quality assessment model for hearing aid users.
A Study on Incorporating Whisper for Robust Speech Assessment
Sep 22, 2023



This research introduces an enhanced version of the multi-objective speech assessment model, called MOSA-Net+, by leveraging the acoustic features from large pre-trained weakly supervised models, namely Whisper, to create embedding features. The first part of this study investigates the correlation between the embedding features of Whisper and two self-supervised learning (SSL) models with subjective quality and intelligibility scores. The second part evaluates the effectiveness of Whisper in deploying a more robust speech assessment model. Third, the possibility of combining representations from Whisper and SSL models while deploying MOSA-Net+ is analyzed. The experimental results reveal that Whisper's embedding features correlate more strongly with subjective quality and intelligibility than other SSL's embedding features, contributing to more accurate prediction performance achieved by MOSA-Net+. Moreover, combining the embedding features from Whisper and SSL models only leads to marginal improvement. As compared to MOSA-Net and other SSL-based speech assessment models, MOSA-Net+ yields notable improvements in estimating subjective quality and intelligibility scores across all evaluation metrics. We further tested MOSA-Net+ on Track 3 of the VoiceMOS Challenge 2023 and obtained the top-ranked performance.
Utilizing Whisper to Enhance Multi-Branched Speech Intelligibility Prediction Model for Hearing Aids
Sep 18, 2023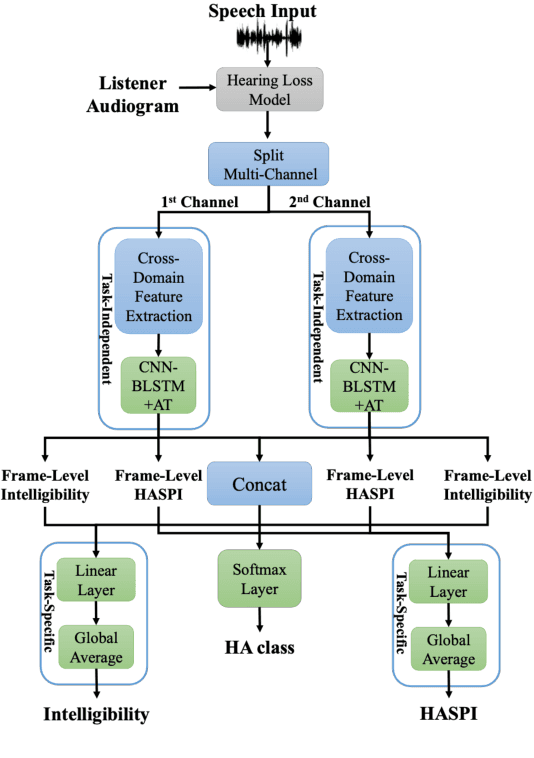
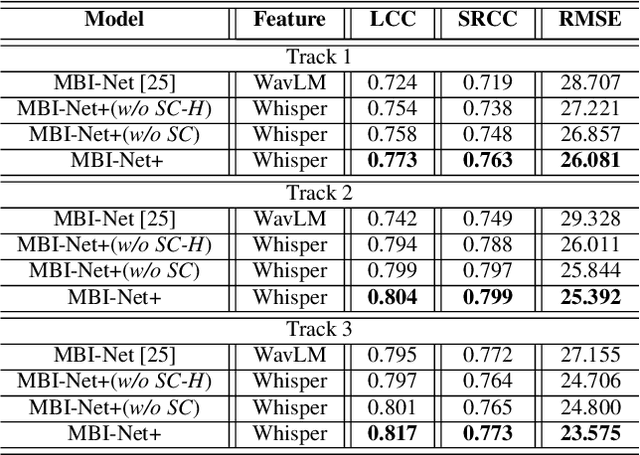
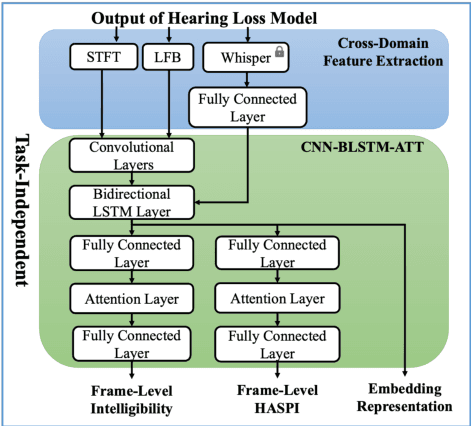
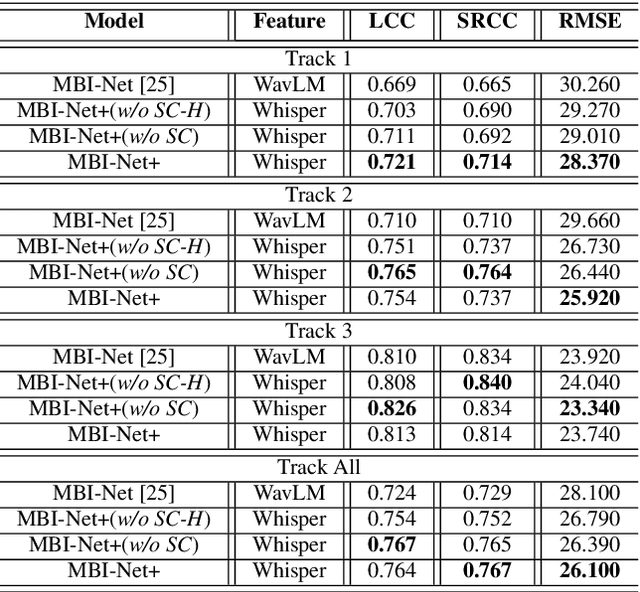
Automated assessment of speech intelligibility in hearing aid (HA) devices is of great importance. Our previous work introduced a non-intrusive multi-branched speech intelligibility prediction model called MBI-Net, which achieved top performance in the Clarity Prediction Challenge 2022. Based on the promising results of the MBI-Net model, we aim to further enhance its performance by leveraging Whisper embeddings to enrich acoustic features. In this study, we propose two improved models, namely MBI-Net+ and MBI-Net++. MBI-Net+ maintains the same model architecture as MBI-Net, but replaces self-supervised learning (SSL) speech embeddings with Whisper embeddings to deploy cross-domain features. On the other hand, MBI-Net++ further employs a more elaborate design, incorporating an auxiliary task to predict frame-level and utterance-level scores of the objective speech intelligibility metric HASPI (Hearing Aid Speech Perception Index) and multi-task learning. Experimental results confirm that both MBI-Net++ and MBI-Net+ achieve better prediction performance than MBI-Net in terms of multiple metrics, and MBI-Net++ is better than MBI-Net+.
Multi-Task Pseudo-Label Learning for Non-Intrusive Speech Quality Assessment Model
Aug 18, 2023This study introduces multi-task pseudo-label (MPL) learning for a non-intrusive speech quality assessment model. MPL consists of two stages which are obtaining pseudo-label scores from a pretrained model and performing multi-task learning. The 3QUEST metrics, namely Speech-MOS (S-MOS), Noise-MOS (N-MOS), and General-MOS (G-MOS) are selected as the primary ground-truth labels. Additionally, the pretrained MOSA-Net model is utilized to estimate three pseudo-labels: perceptual evaluation of speech quality (PESQ), short-time objective intelligibility (STOI), and speech distortion index (SDI). Multi-task learning stage of MPL is then employed to train the MTQ-Net model (multi-target speech quality assessment network). The model is optimized by incorporating Loss supervision (derived from the difference between the estimated score and the real ground-truth labels) and Loss semi-supervision (derived from the difference between the estimated score and pseudo-labels), where Huber loss is employed to calculate the loss function. Experimental results first demonstrate the advantages of MPL compared to training the model from scratch and using knowledge transfer mechanisms. Secondly, the benefits of Huber Loss in improving the prediction model of MTQ-Net are verified. Finally, the MTQ-Net with the MPL approach exhibits higher overall prediction capabilities when compared to other SSL-based speech assessment models.