 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinguistic Knowledge Transfer Learning for Speech Enhancement
Mar 10, 2025Linguistic knowledge plays a crucial role in spoken language comprehension. It provides essential semantic and syntactic context for speech perception in noisy environments. However, most speech enhancement (SE) methods predominantly rely on acoustic features to learn the mapping relationship between noisy and clean speech, with limited exploration of linguistic integration. While text-informed SE approaches have been investigated, they often require explicit speech-text alignment or externally provided textual data, constraining their practicality in real-world scenarios. Additionally, using text as input poses challenges in aligning linguistic and acoustic representations due to their inherent differences. In this study, we propose the Cross-Modality Knowledge Transfer (CMKT) learning framework, which leverages pre-trained large language models (LLMs) to infuse linguistic knowledge into SE models without requiring text input or LLMs during inference. Furthermore, we introduce a misalignment strategy to improve knowledge transfer. This strategy applies controlled temporal shifts, encouraging the model to learn more robust representations. Experimental evaluations demonstrate that CMKT consistently outperforms baseline models across various SE architectures and LLM embeddings, highlighting its adaptability to different configurations. Additionally, results on Mandarin and English datasets confirm its effectiveness across diverse linguistic conditions, further validating its robustness. Moreover, CMKT remains effective even in scenarios without textual data, underscoring its practicality for real-world applications. By bridging the gap between linguistic and acoustic modalities, CMKT offers a scalable and innovative solution for integrating linguistic knowledge into SE models, leading to substantial improvements in both intelligibility and enhancement performance.
MECG-E: Mamba-based ECG Enhancer for Baseline Wander Removal
Sep 27, 2024Electrocardiogram (ECG) is an important non-invasive method for diagnosing cardiovascular disease. However, ECG signals are susceptible to noise contamination, such as electrical interference or signal wandering, which reduces diagnostic accuracy. Various ECG denoising methods have been proposed, but most existing methods yield suboptimal performance under very noisy conditions or require several steps during inference, leading to latency during online processing. In this paper, we propose a novel ECG denoising model, namely Mamba-based ECG Enhancer (MECG-E), which leverages the Mamba architecture known for its fast inference and outstanding nonlinear mapping capabilities. Experimental results indicate that MECG-E surpasses several well-known existing models across multiple metrics under different noise conditions. Additionally, MECG-E requires less inference time than state-of-the-art diffusion-based ECG denoisers, demonstrating the model's functionality and efficiency.
Robust Audio-Visual Speech Enhancement: Correcting Misassignments in Complex Environments with Advanced Post-Processing
Sep 22, 2024



This paper addresses the prevalent issue of incorrect speech output in audio-visual speech enhancement (AVSE) systems, which is often caused by poor video quality and mismatched training and test data. We introduce a post-processing classifier (PPC) to rectify these erroneous outputs, ensuring that the enhanced speech corresponds accurately to the intended speaker. We also adopt a mixup strategy in PPC training to improve its robustness. Experimental results on the AVSE-challenge dataset show that integrating PPC into the AVSE model can significantly improve AVSE performance, and combining PPC with the AVSE model trained with permutation invariant training (PIT) yields the best performance. The proposed method substantially outperforms the baseline model by a large margin. This work highlights the potential for broader applications across various modalities and architectures, providing a promising direction for future research in this field.
Leveraging Joint Spectral and Spatial Learning with MAMBA for Multichannel Speech Enhancement
Sep 16, 2024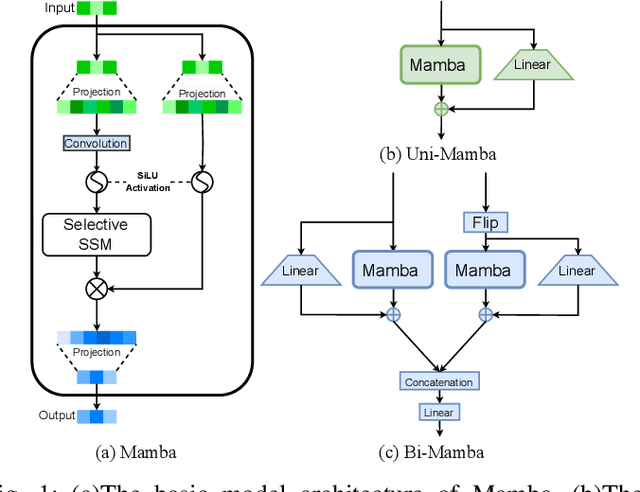
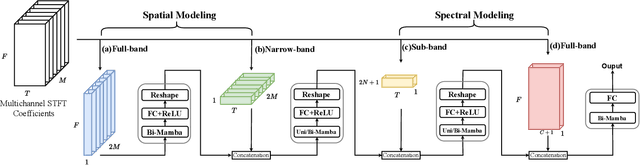
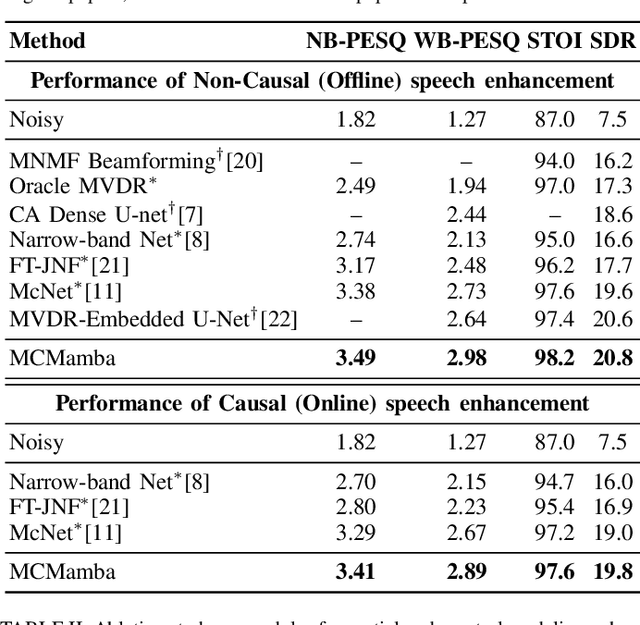
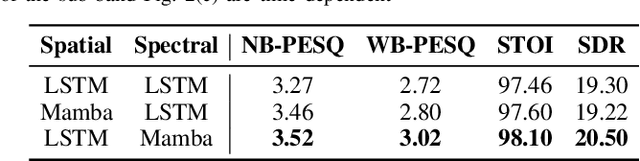
In multichannel speech enhancement, effectively capturing spatial and spectral information across different microphones is crucial for noise reduction. Traditional methods, such as CNN or LSTM, attempt to model the temporal dynamics of full-band and sub-band spectral and spatial features. However, these approaches face limitations in fully modeling complex temporal dependencies, especially in dynamic acoustic environments. To overcome these challenges, we modify the current advanced model McNet by introducing an improved version of Mamba, a state-space model, and further propose MCMamba. MCMamba has been completely reengineered to integrate full-band and narrow-band spatial information with sub-band and full-band spectral features, providing a more comprehensive approach to modeling spatial and spectral information. Our experimental results demonstrate that MCMamba significantly improves the modeling of spatial and spectral features in multichannel speech enhancement, outperforming McNet and achieving state-of-the-art performance on the CHiME-3 dataset. Additionally, we find that Mamba performs exceptionally well in modeling spectral information.
Exploiting Consistency-Preserving Loss and Perceptual Contrast Stretching to Boost SSL-based Speech Enhancement
Aug 08, 2024Self-supervised representation learning (SSL) has attained SOTA results on several downstream speech tasks, but SSL-based speech enhancement (SE) solutions still lag behind. To address this issue, we exploit three main ideas: (i) Transformer-based masking generation, (ii) consistency-preserving loss, and (iii) perceptual contrast stretching (PCS). In detail, conformer layers, leveraging an attention mechanism, are introduced to effectively model frame-level representations and obtain the Ideal Ratio Mask (IRM) for SE. Moreover, we incorporate consistency in the loss function, which processes the input to account for the inconsistency effects of signal reconstruction from the spectrogram. Finally, PCS is employed to improve the contrast of input and target features according to perceptual importance. Evaluated on the VoiceBank-DEMAND task, the proposed solution outperforms previously SSL-based SE solutions when tested on several objective metrics, attaining a SOTA PESQ score of 3.54.
Self-Supervised Speech Quality Estimation and Enhancement Using Only Clean Speech
Feb 26, 2024Speech quality estimation has recently undergone a paradigm shift from human-hearing expert designs to machine-learning models. However, current models rely mainly on supervised learning, which is time-consuming and expensive for label collection. To solve this problem, we propose VQScore, a self-supervised metric for evaluating speech based on the quantization error of a vector-quantized-variational autoencoder (VQ-VAE). The training of VQ-VAE relies on clean speech; hence, large quantization errors can be expected when the speech is distorted. To further improve correlation with real quality scores, domain knowledge of speech processing is incorporated into the model design. We found that the vector quantization mechanism could also be used for self-supervised speech enhancement (SE) model training. To improve the robustness of the encoder for SE, a novel self-distillation mechanism combined with adversarial training is introduced. In summary, the proposed speech quality estimation method and enhancement models require only clean speech for training without any label requirements. Experimental results show that the proposed VQScore and enhancement model are competitive with supervised baselines. The code will be released after publication.
Study on the Correlation between Objective Evaluations and Subjective Speech Quality and Intelligibility
Jul 10, 2023Subjective tests are the gold standard for evaluating speech quality and intelligibility, but they are time-consuming and expensive. Thus, objective measures that align with human perceptions are crucial. This study evaluates the correlation between commonly used objective measures and subjective speech quality and intelligibility using a Chinese speech dataset. Moreover, new objective measures are proposed combining current objective measures using deep learning techniques to predict subjective quality and intelligibility. The proposed deep learning model reduces the amount of training data without significantly impacting prediction performance. We interpret the deep learning model to understand how objective measures reflect subjective quality and intelligibility. We also explore the impact of including subjective speech quality ratings on speech intelligibility prediction. Our findings offer valuable insights into the relationship between objective measures and human perceptions.
Preoperative Prognosis Assessment of Lumbar Spinal Surgery for Low Back Pain and Sciatica Patients based on Multimodalities and Multimodal Learning
Mar 16, 2023



Low back pain (LBP) and sciatica may require surgical therapy when they are symptomatic of severe pain. However, there is no effective measures to evaluate the surgical outcomes in advance. This work combined elements of Eastern medicine and machine learning, and developed a preoperative assessment tool to predict the prognosis of lumbar spinal surgery in LBP and sciatica patients. Standard operative assessments, traditional Chinese medicine body constitution assessments, planned surgical approach, and vowel pronunciation recordings were collected and stored in different modalities. Our work provides insights into leveraging modality combinations, multimodals, and fusion strategies. The interpretability of models and correlations between modalities were also inspected. Based on the recruited 105 patients, we found that combining standard operative assessments, body constitution assessments, and planned surgical approach achieved the best performance in 0.81 accuracy. Our approach is effective and can be widely applied in general practice due to simplicity and effective.
Self-supervised based general laboratory progress pretrained model for cardiovascular event detection
Mar 15, 2023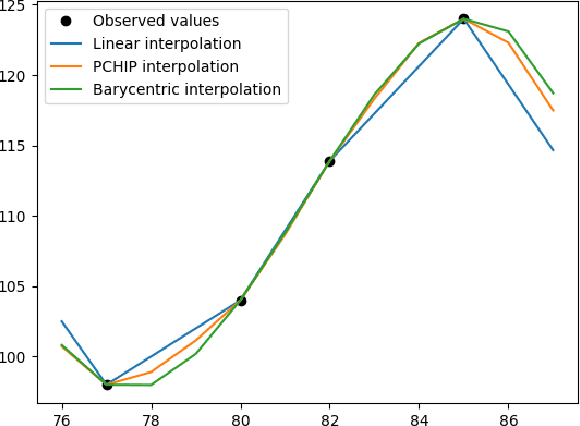
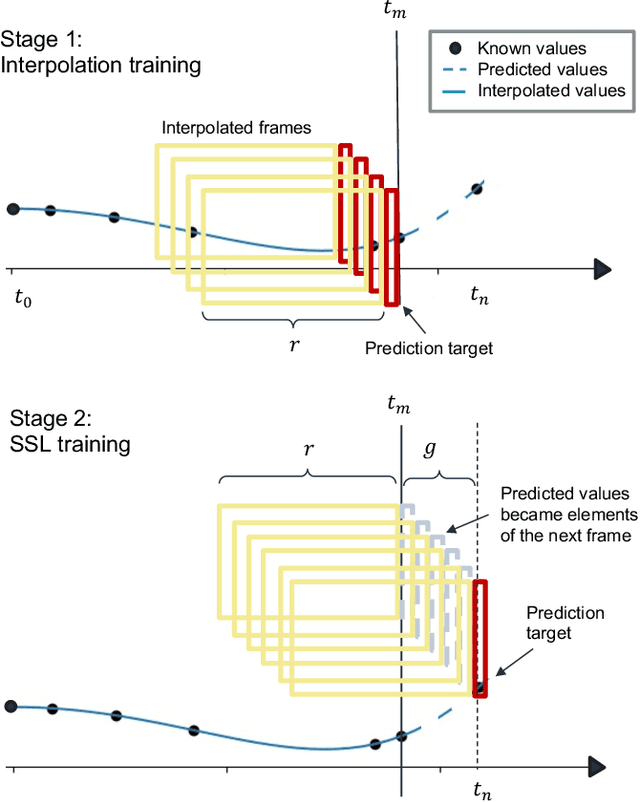
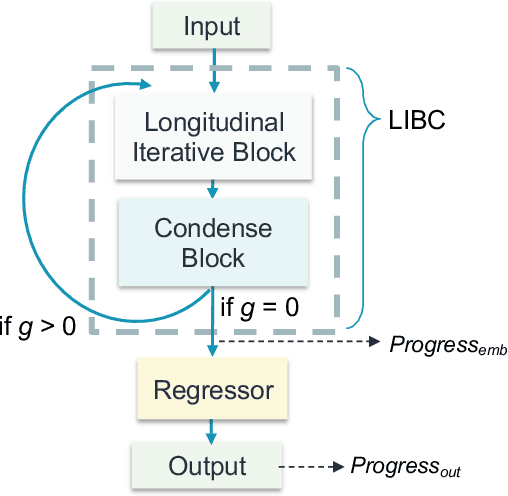
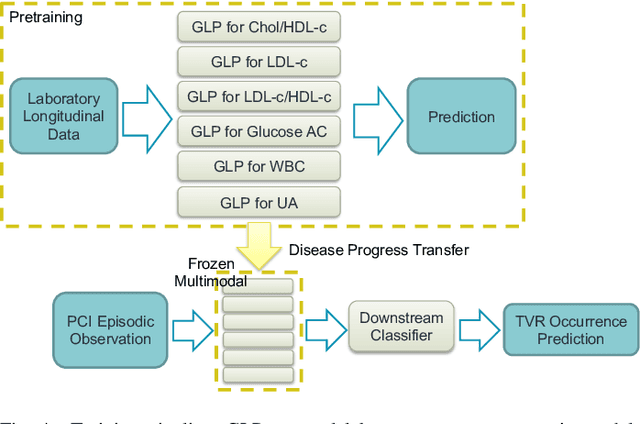
Regular surveillance is an indispensable aspect of managing cardiovascular disorders. Patient recruitment for rare or specific diseases is often limited due to their small patient size and episodic observations, whereas prevalent cases accumulate longitudinal data easily due to regular follow-ups. These data, however, are notorious for their irregularity, temporality, absenteeism, and sparsity. In this study, we leveraged self-supervised learning (SSL) and transfer learning to overcome the above-mentioned barriers, transferring patient progress trends in cardiovascular laboratory parameters from prevalent cases to rare or specific cardiovascular events detection. We pretrained a general laboratory progress (GLP) pretrain model using hypertension patients (who were yet to be diabetic), and transferred their laboratory progress trend to assist in detecting target vessel revascularization (TVR) in percutaneous coronary intervention patients. GLP adopted a two-stage training process that utilized interpolated data, enhancing the performance of SSL. After pretraining GLP, we fine-tuned it for TVR prediction. The proposed two-stage training process outperformed SSL. Upon processing by GLP, the classification demonstrated a marked improvement, increasing from 0.63 to 0.90 in averaged accuracy. All metrics were significantly superior (p < 0.01) to the performance of prior GLP processing. The representation displayed distinct separability independent of algorithmic mechanisms, and diverse data distribution trend. Our approach effectively transferred the progression trends of cardiovascular laboratory parameters from prevalent cases to small-numbered cases, thereby demonstrating its efficacy in aiding the risk assessment of cardiovascular events without limiting to episodic observation. The potential for extending this approach to other laboratory tests and diseases is promising.
Interpretations of Domain Adaptations via Layer Variational Analysis
Feb 03, 2023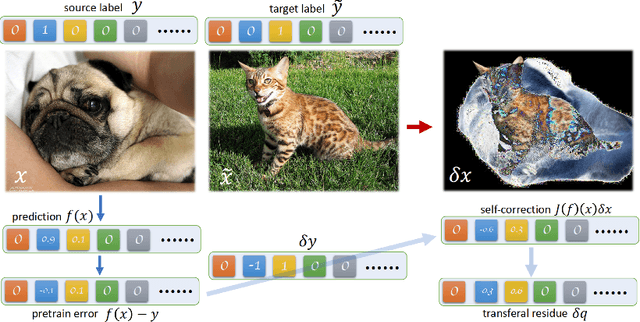
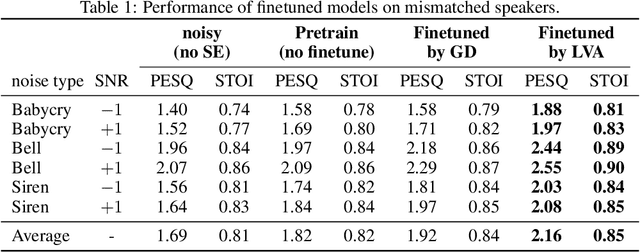

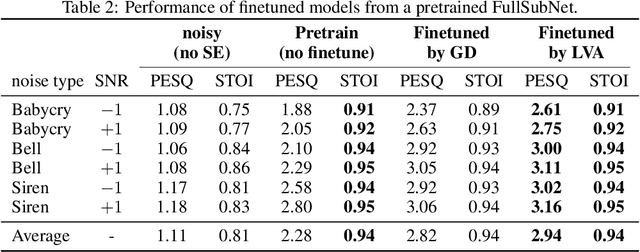
Transfer learning is known to perform efficiently in many applications empirically, yet limited literature reports the mechanism behind the scene. This study establishes both formal derivations and heuristic analysis to formulate the theory of transfer learning in deep learning. Our framework utilizing layer variational analysis proves that the success of transfer learning can be guaranteed with corresponding data conditions. Moreover, our theoretical calculation yields intuitive interpretations towards the knowledge transfer process. Subsequently, an alternative method for network-based transfer learning is derived. The method shows an increase in efficiency and accuracy for domain adaptation. It is particularly advantageous when new domain data is sufficiently sparse during adaptation. Numerical experiments over diverse tasks validated our theory and verified that our analytic expression achieved better performance in domain adaptation than the gradient descent method.