 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneral Demographic Foundation Models for Enhancing Predictive Performance Across Diseases
Sep 09, 2025Demographic attributes are universally present in electronic health records and serve as vital predictors in clinical risk stratification and treatment decisions. Despite their significance, these attributes are often relegated to auxiliary roles in model design, with limited attention has been given to learning their representations. This study proposes a General Demographic Pre-trained (GDP) model as a foundational representation framework tailored to age and gender. The model is pre-trained and evaluated using datasets with diverse diseases and population compositions from different geographic regions. The GDP architecture explores combinations of ordering strategies and encoding methods to transform tabular demographic inputs into latent embeddings. Experimental results demonstrate that sequential ordering substantially improves model performance in discrimination, calibration, and the corresponding information gain at each decision tree split, particularly in diseases where age and gender contribute significantly to risk stratification. Even in datasets where demographic attributes hold relatively low predictive value, GDP enhances the representational importance, increasing their influence in downstream gradient boosting models. The findings suggest that foundational models for tabular demographic attributes can generalize across tasks and populations, offering a promising direction for improving predictive performance in healthcare applications.
Lightly Weighted Automatic Audio Parameter Extraction for the Quality Assessment of Consensus Auditory-Perceptual Evaluation of Voice
Nov 27, 2023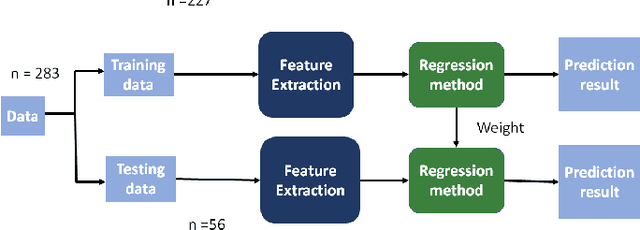
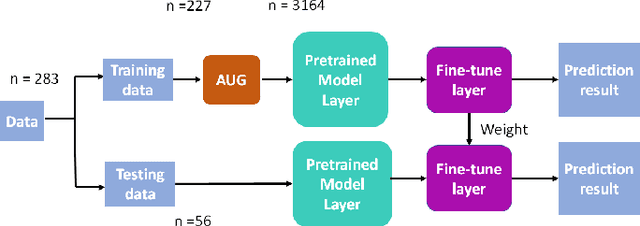
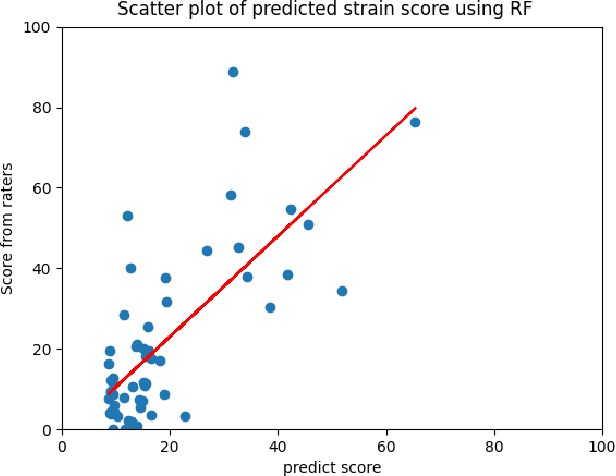

The Consensus Auditory-Perceptual Evaluation of Voice is a widely employed tool in clinical voice quality assessment that is significant for streaming communication among clinical professionals and benchmarking for the determination of further treatment. Currently, because the assessment relies on experienced clinicians, it tends to be inconsistent, and thus, difficult to standardize. To address this problem, we propose to leverage lightly weighted automatic audio parameter extraction, to increase the clinical relevance, reduce the complexity, and enhance the interpretability of voice quality assessment. The proposed method utilizes age, sex, and five audio parameters: jitter, absolute jitter, shimmer, harmonic-to-noise ratio (HNR), and zero crossing. A classical machine learning approach is employed. The result reveals that our approach performs similar to state-of-the-art (SOTA) methods, and outperforms the latent representation obtained by using popular audio pre-trained models. This approach provide insights into the feasibility of different feature extraction approaches for voice evaluation. Audio parameters such as jitter and the HNR are proven to be suitable for characterizing voice quality attributes, such as roughness and strain. Conversely, pre-trained models exhibit limitations in effectively addressing noise-related scorings. This study contributes toward more comprehensive and precise voice quality evaluations, achieved by a comprehensively exploring diverse assessment methodologies.
Deep denoising autoencoder-based non-invasive blood flow detection for arteriovenous fistula
Jun 12, 2023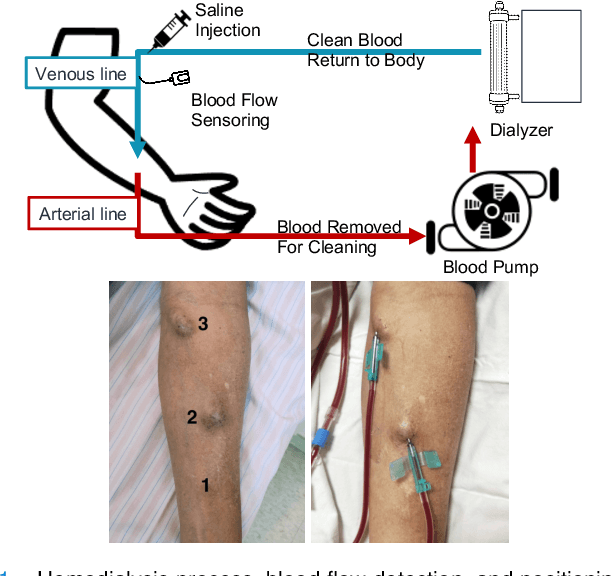
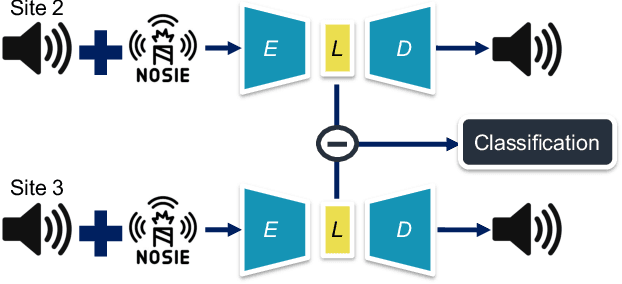
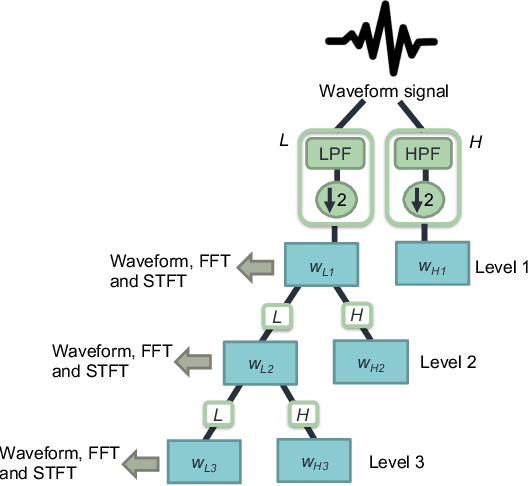
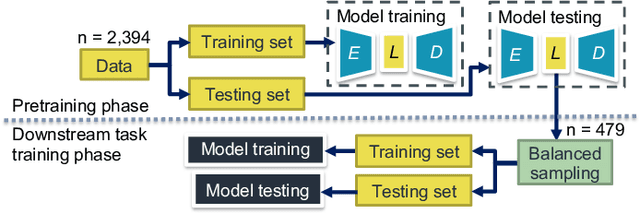
Clinical guidelines underscore the importance of regularly monitoring and surveilling arteriovenous fistula (AVF) access in hemodialysis patients to promptly detect any dysfunction. Although phono-angiography/sound analysis overcomes the limitations of standardized AVF stenosis diagnosis tool, prior studies have depended on conventional feature extraction methods, restricting their applicability in diverse contexts. In contrast, representation learning captures fundamental underlying factors that can be readily transferred across different contexts. We propose an approach based on deep denoising autoencoders (DAEs) that perform dimensionality reduction and reconstruction tasks using the waveform obtained through one-level discrete wavelet transform, utilizing representation learning. Our results demonstrate that the latent representation generated by the DAE surpasses expectations with an accuracy of 0.93. The incorporation of noise-mixing and the utilization of a noise-to-clean scheme effectively enhance the discriminative capabilities of the latent representation. Moreover, when employed to identify patient-specific characteristics, the latent representation exhibited performance by surpassing an accuracy of 0.92. Appropriate light-weighted methods can restore the detection performance of the excessively reduced dimensionality version and enable operation on less computational devices. Our findings suggest that representation learning is a more feasible approach for extracting auscultation features in AVF, leading to improved generalization and applicability across multiple tasks. The manipulation of latent representations holds immense potential for future advancements. Further investigations in this area are promising and warrant continued exploration.
Preoperative Prognosis Assessment of Lumbar Spinal Surgery for Low Back Pain and Sciatica Patients based on Multimodalities and Multimodal Learning
Mar 16, 2023



Low back pain (LBP) and sciatica may require surgical therapy when they are symptomatic of severe pain. However, there is no effective measures to evaluate the surgical outcomes in advance. This work combined elements of Eastern medicine and machine learning, and developed a preoperative assessment tool to predict the prognosis of lumbar spinal surgery in LBP and sciatica patients. Standard operative assessments, traditional Chinese medicine body constitution assessments, planned surgical approach, and vowel pronunciation recordings were collected and stored in different modalities. Our work provides insights into leveraging modality combinations, multimodals, and fusion strategies. The interpretability of models and correlations between modalities were also inspected. Based on the recruited 105 patients, we found that combining standard operative assessments, body constitution assessments, and planned surgical approach achieved the best performance in 0.81 accuracy. Our approach is effective and can be widely applied in general practice due to simplicity and effective.
Self-supervised based general laboratory progress pretrained model for cardiovascular event detection
Mar 15, 2023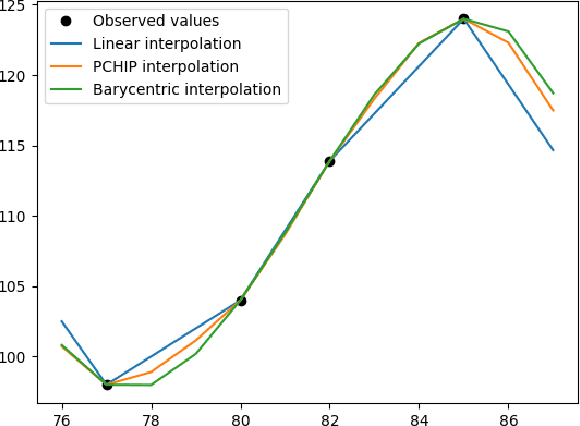
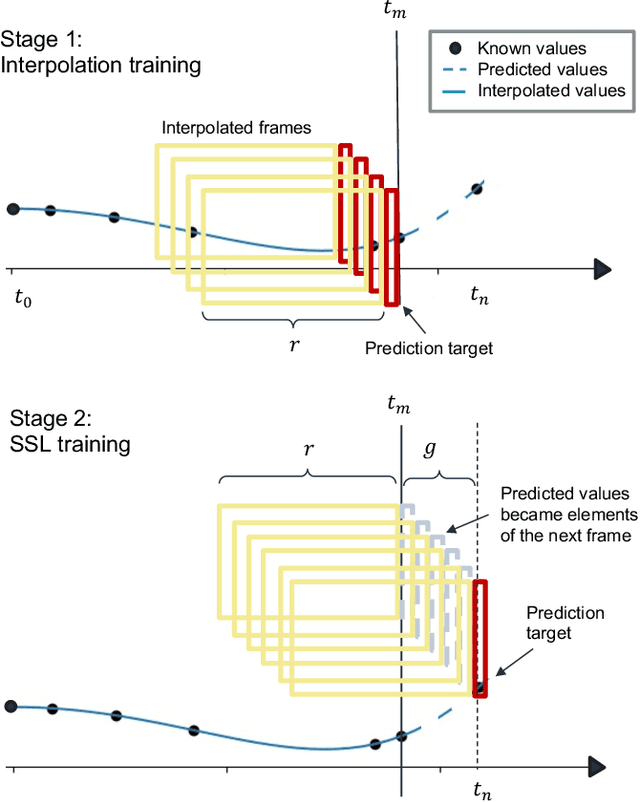
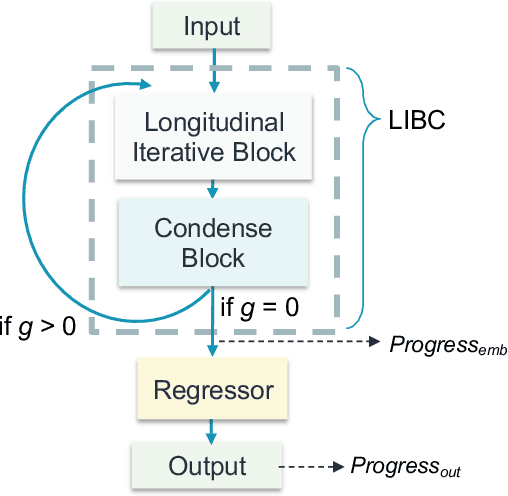
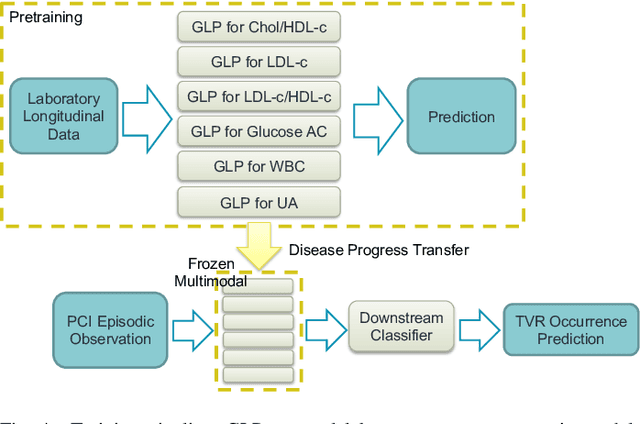
Regular surveillance is an indispensable aspect of managing cardiovascular disorders. Patient recruitment for rare or specific diseases is often limited due to their small patient size and episodic observations, whereas prevalent cases accumulate longitudinal data easily due to regular follow-ups. These data, however, are notorious for their irregularity, temporality, absenteeism, and sparsity. In this study, we leveraged self-supervised learning (SSL) and transfer learning to overcome the above-mentioned barriers, transferring patient progress trends in cardiovascular laboratory parameters from prevalent cases to rare or specific cardiovascular events detection. We pretrained a general laboratory progress (GLP) pretrain model using hypertension patients (who were yet to be diabetic), and transferred their laboratory progress trend to assist in detecting target vessel revascularization (TVR) in percutaneous coronary intervention patients. GLP adopted a two-stage training process that utilized interpolated data, enhancing the performance of SSL. After pretraining GLP, we fine-tuned it for TVR prediction. The proposed two-stage training process outperformed SSL. Upon processing by GLP, the classification demonstrated a marked improvement, increasing from 0.63 to 0.90 in averaged accuracy. All metrics were significantly superior (p < 0.01) to the performance of prior GLP processing. The representation displayed distinct separability independent of algorithmic mechanisms, and diverse data distribution trend. Our approach effectively transferred the progression trends of cardiovascular laboratory parameters from prevalent cases to small-numbered cases, thereby demonstrating its efficacy in aiding the risk assessment of cardiovascular events without limiting to episodic observation. The potential for extending this approach to other laboratory tests and diseases is promising.
EPG2S: Speech Generation and Speech Enhancement based on Electropalatography and Audio Signals using Multimodal Learning
Jun 16, 2022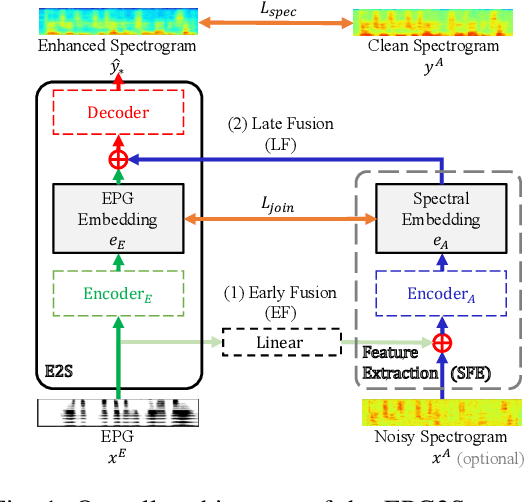
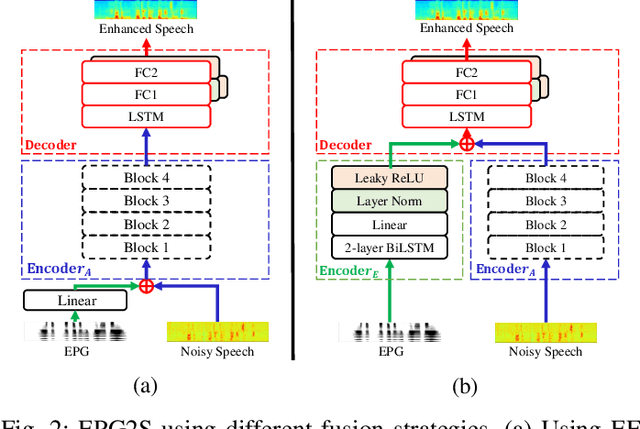
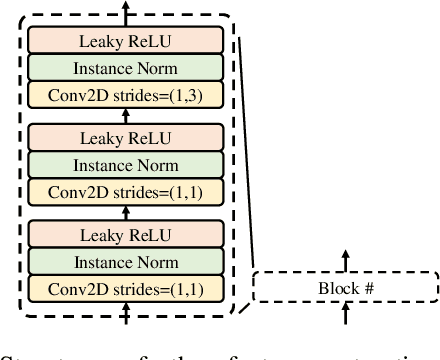
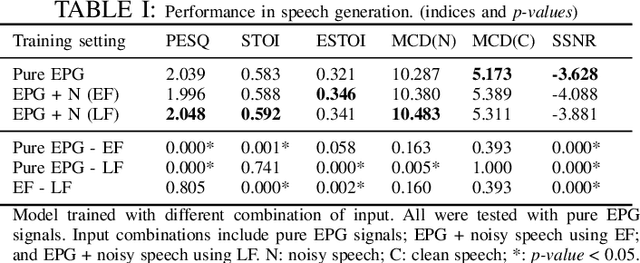
Speech generation and enhancement based on articulatory movements facilitate communication when the scope of verbal communication is absent, e.g., in patients who have lost the ability to speak. Although various techniques have been proposed to this end, electropalatography (EPG), which is a monitoring technique that records contact between the tongue and hard palate during speech, has not been adequately explored. Herein, we propose a novel multimodal EPG-to-speech (EPG2S) system that utilizes EPG and speech signals for speech generation and enhancement. Different fusion strategies based on multiple combinations of EPG and noisy speech signals are examined, and the viability of the proposed method is investigated. Experimental results indicate that EPG2S achieves desirable speech generation outcomes based solely on EPG signals. Further, the addition of noisy speech signals is observed to improve quality and intelligibility. Additionally, EPG2S is observed to achieve high-quality speech enhancement based solely on audio signals, with the addition of EPG signals further improving the performance. The late fusion strategy is deemed to be the most effective approach for simultaneous speech generation and enhancement.
Predicting the Travel Distance of Patients to Access Healthcare using Deep Neural Networks
Dec 07, 2021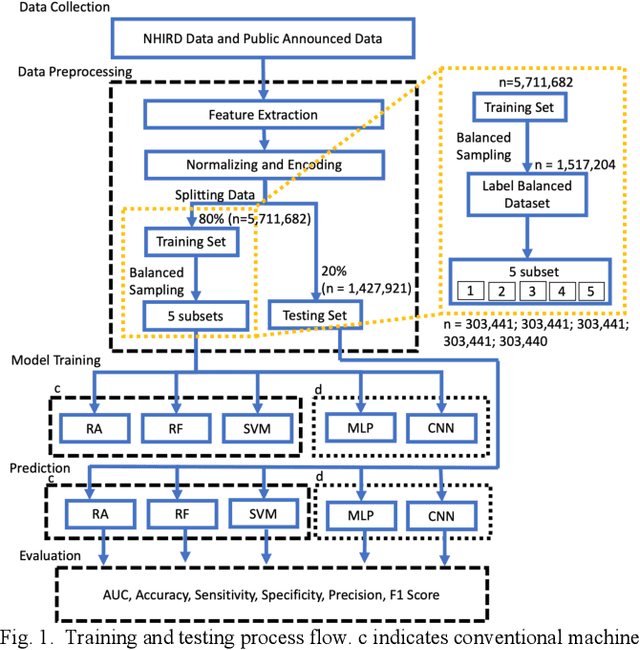
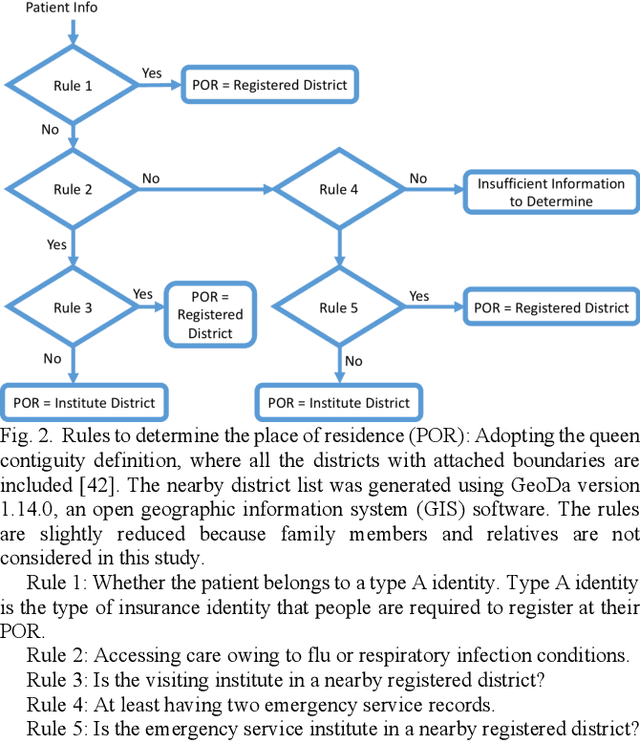
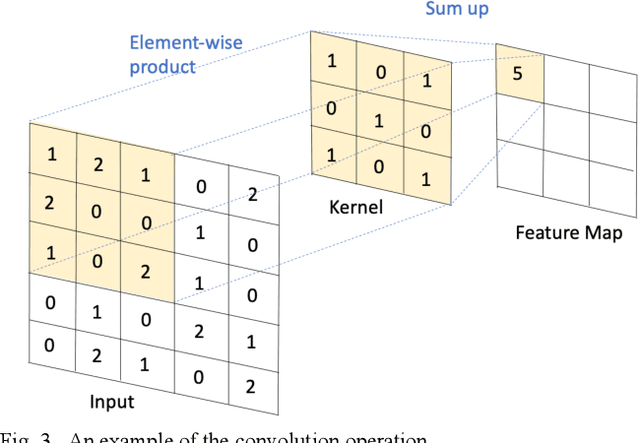

Objective: Improving geographical access remains a key issue in determining the sufficiency of regional medical resources during health policy design. However, patient choices can be the result of the complex interactivity of various factors. The aim of this study is to propose a deep neural network approach to model the complex decision of patient choice in travel distance to access care, which is an important indicator for policymaking in allocating resources. Method: We used the 4-year nationwide insurance data of Taiwan and accumulated the possible features discussed in earlier literature. This study proposes the use of a convolutional neural network (CNN)-based framework to make predictions. The model performance was tested against other machine learning methods. The proposed framework was further interpreted using Integrated Gradients (IG) to analyze the feature weights. Results: We successfully demonstrated the effectiveness of using a CNN-based framework to predict the travel distance of patients, achieving an accuracy of 0.968, AUC of 0.969, sensitivity of 0.960, and specificity of 0.989. The CNN-based framework outperformed all other methods. In this research, the IG weights are potentially explainable; however, the relationship does not correspond to known indicators in public health, similar to common consensus. Conclusions: Our results demonstrate the feasibility of the deep learning-based travel distance prediction model. It has the potential to guide policymaking in resource allocation.
Benchmarking of eight recurrent neural network variants for breath phase and adventitious sound detection on a self-developed open-access lung sound database-HF_Lung_V1
Mar 03, 2021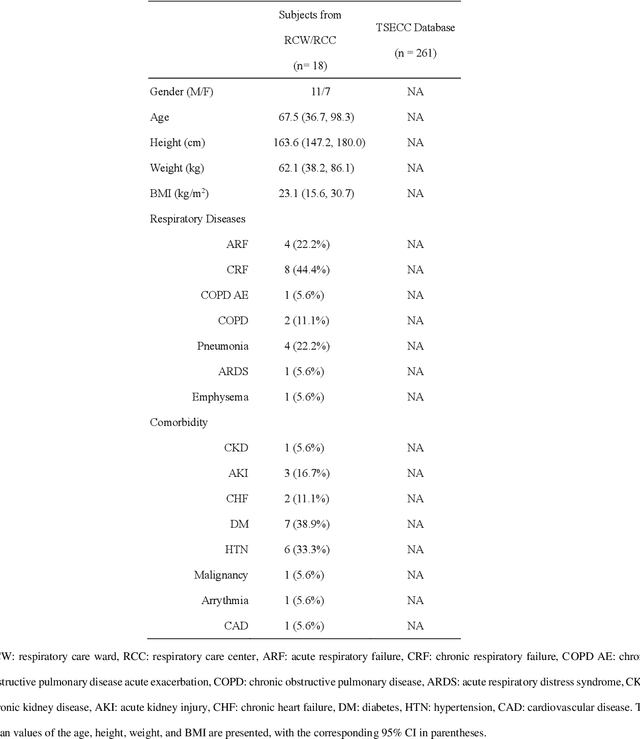

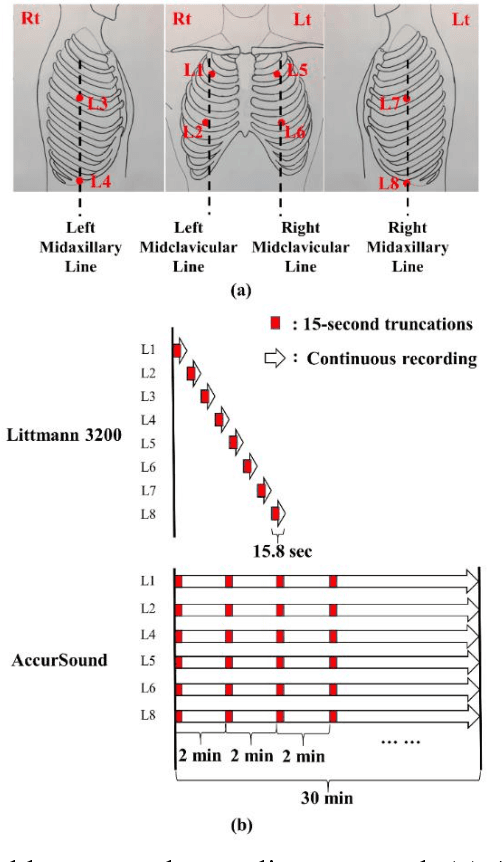

A reliable, remote, and continuous real-time respiratory sound monitor with automated respiratory sound analysis ability is urgently required in many clinical scenarios-such as in monitoring disease progression of coronavirus disease 2019-to replace conventional auscultation with a handheld stethoscope. However, a robust computerized respiratory sound analysis algorithm has not yet been validated in practical applications. In this study, we developed a lung sound database (HF_Lung_V1) comprising 9,765 audio files of lung sounds (duration of 15 s each), 34,095 inhalation labels, 18,349 exhalation labels, 13,883 continuous adventitious sound (CAS) labels (comprising 8,457 wheeze labels, 686 stridor labels, and 4,740 rhonchi labels), and 15,606 discontinuous adventitious sound labels (all crackles). We conducted benchmark tests for long short-term memory (LSTM), gated recurrent unit (GRU), bidirectional LSTM (BiLSTM), bidirectional GRU (BiGRU), convolutional neural network (CNN)-LSTM, CNN-GRU, CNN-BiLSTM, and CNN-BiGRU models for breath phase detection and adventitious sound detection. We also conducted a performance comparison between the LSTM-based and GRU-based models, between unidirectional and bidirectional models, and between models with and without a CNN. The results revealed that these models exhibited adequate performance in lung sound analysis. The GRU-based models outperformed, in terms of F1 scores and areas under the receiver operating characteristic curves, the LSTM-based models in most of the defined tasks. Furthermore, all bidirectional models outperformed their unidirectional counterparts. Finally, the addition of a CNN improved the accuracy of lung sound analysis, especially in the CAS detection tasks.