 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightly Weighted Automatic Audio Parameter Extraction for the Quality Assessment of Consensus Auditory-Perceptual Evaluation of Voice
Paper and Code
Nov 27, 2023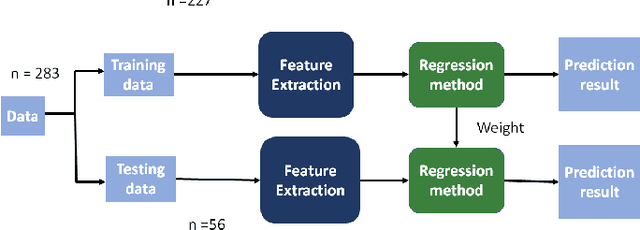
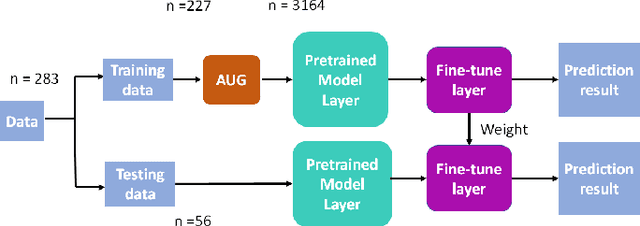
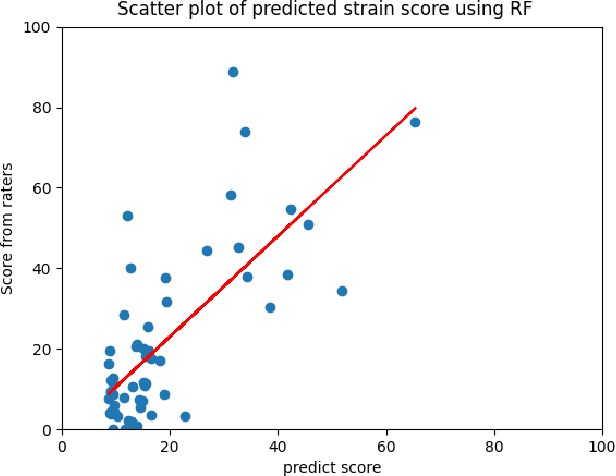

The Consensus Auditory-Perceptual Evaluation of Voice is a widely employed tool in clinical voice quality assessment that is significant for streaming communication among clinical professionals and benchmarking for the determination of further treatment. Currently, because the assessment relies on experienced clinicians, it tends to be inconsistent, and thus, difficult to standardize. To address this problem, we propose to leverage lightly weighted automatic audio parameter extraction, to increase the clinical relevance, reduce the complexity, and enhance the interpretability of voice quality assessment. The proposed method utilizes age, sex, and five audio parameters: jitter, absolute jitter, shimmer, harmonic-to-noise ratio (HNR), and zero crossing. A classical machine learning approach is employed. The result reveals that our approach performs similar to state-of-the-art (SOTA) methods, and outperforms the latent representation obtained by using popular audio pre-trained models. This approach provide insights into the feasibility of different feature extraction approaches for voice evaluation. Audio parameters such as jitter and the HNR are proven to be suitable for characterizing voice quality attributes, such as roughness and strain. Conversely, pre-trained models exhibit limitations in effectively addressing noise-related scorings. This study contributes toward more comprehensive and precise voice quality evaluations, achieved by a comprehensively exploring diverse assessment methodologies.