 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLightly Weighted Automatic Audio Parameter Extraction for the Quality Assessment of Consensus Auditory-Perceptual Evaluation of Voice
Nov 27, 2023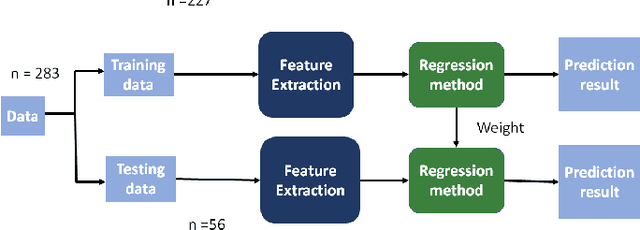
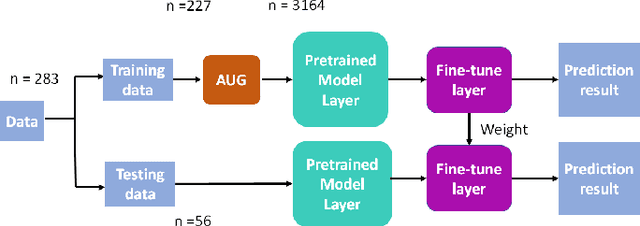
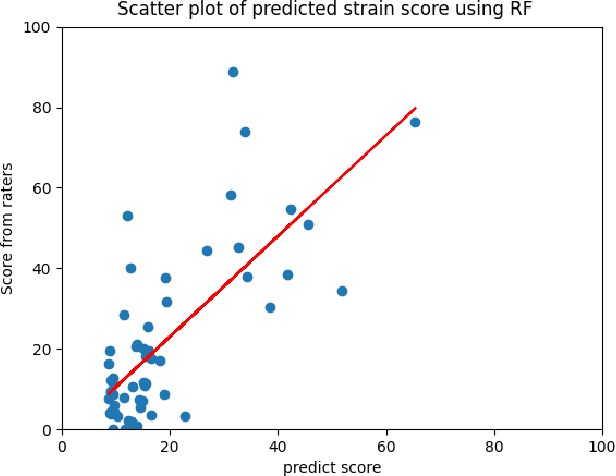

The Consensus Auditory-Perceptual Evaluation of Voice is a widely employed tool in clinical voice quality assessment that is significant for streaming communication among clinical professionals and benchmarking for the determination of further treatment. Currently, because the assessment relies on experienced clinicians, it tends to be inconsistent, and thus, difficult to standardize. To address this problem, we propose to leverage lightly weighted automatic audio parameter extraction, to increase the clinical relevance, reduce the complexity, and enhance the interpretability of voice quality assessment. The proposed method utilizes age, sex, and five audio parameters: jitter, absolute jitter, shimmer, harmonic-to-noise ratio (HNR), and zero crossing. A classical machine learning approach is employed. The result reveals that our approach performs similar to state-of-the-art (SOTA) methods, and outperforms the latent representation obtained by using popular audio pre-trained models. This approach provide insights into the feasibility of different feature extraction approaches for voice evaluation. Audio parameters such as jitter and the HNR are proven to be suitable for characterizing voice quality attributes, such as roughness and strain. Conversely, pre-trained models exhibit limitations in effectively addressing noise-related scorings. This study contributes toward more comprehensive and precise voice quality evaluations, achieved by a comprehensively exploring diverse assessment methodologies.
Deep denoising autoencoder-based non-invasive blood flow detection for arteriovenous fistula
Jun 12, 2023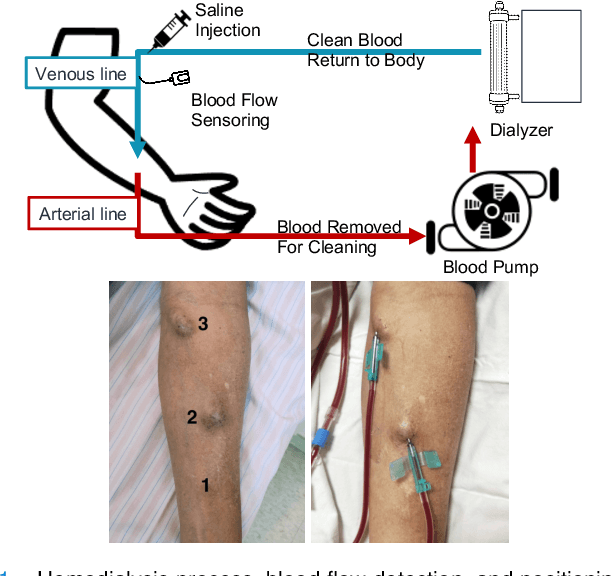
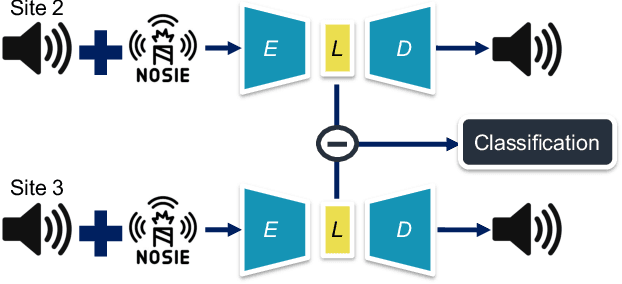
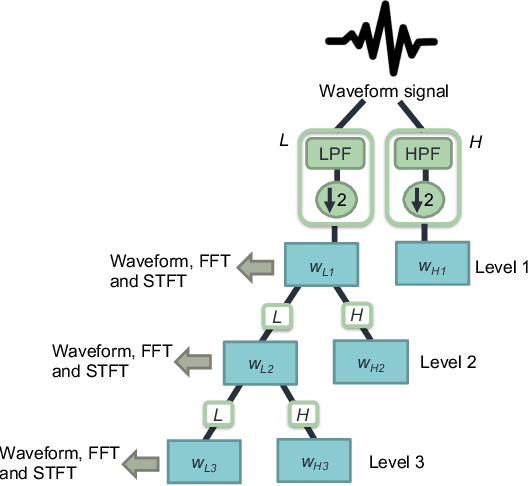
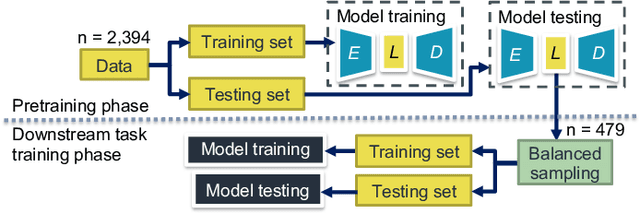
Clinical guidelines underscore the importance of regularly monitoring and surveilling arteriovenous fistula (AVF) access in hemodialysis patients to promptly detect any dysfunction. Although phono-angiography/sound analysis overcomes the limitations of standardized AVF stenosis diagnosis tool, prior studies have depended on conventional feature extraction methods, restricting their applicability in diverse contexts. In contrast, representation learning captures fundamental underlying factors that can be readily transferred across different contexts. We propose an approach based on deep denoising autoencoders (DAEs) that perform dimensionality reduction and reconstruction tasks using the waveform obtained through one-level discrete wavelet transform, utilizing representation learning. Our results demonstrate that the latent representation generated by the DAE surpasses expectations with an accuracy of 0.93. The incorporation of noise-mixing and the utilization of a noise-to-clean scheme effectively enhance the discriminative capabilities of the latent representation. Moreover, when employed to identify patient-specific characteristics, the latent representation exhibited performance by surpassing an accuracy of 0.92. Appropriate light-weighted methods can restore the detection performance of the excessively reduced dimensionality version and enable operation on less computational devices. Our findings suggest that representation learning is a more feasible approach for extracting auscultation features in AVF, leading to improved generalization and applicability across multiple tasks. The manipulation of latent representations holds immense potential for future advancements. Further investigations in this area are promising and warrant continued exploration.