 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep denoising autoencoder-based non-invasive blood flow detection for arteriovenous fistula
Jun 12, 2023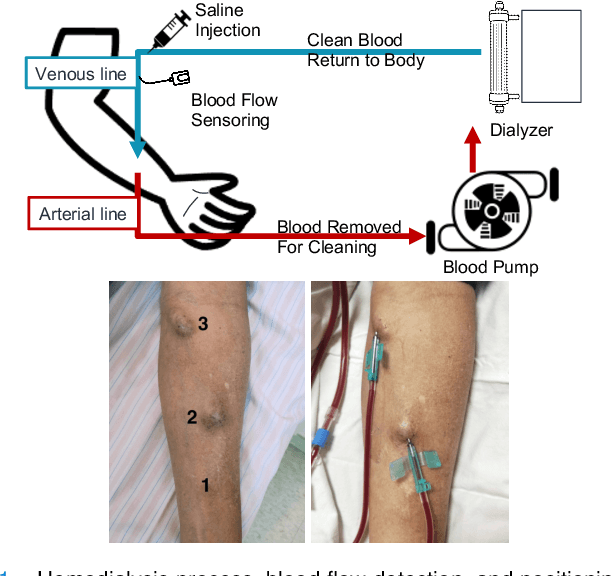
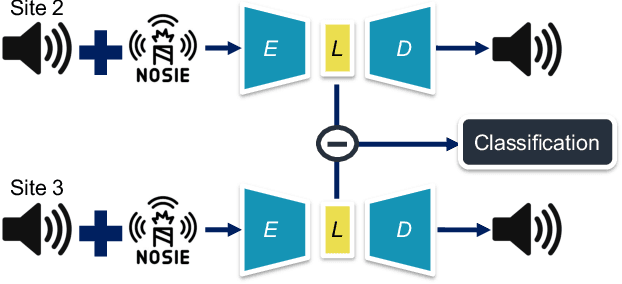
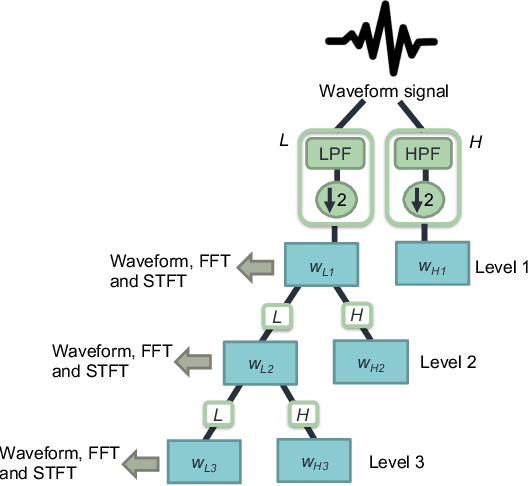
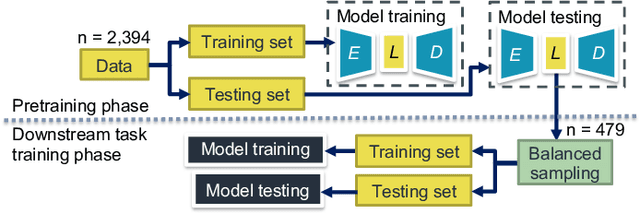
Clinical guidelines underscore the importance of regularly monitoring and surveilling arteriovenous fistula (AVF) access in hemodialysis patients to promptly detect any dysfunction. Although phono-angiography/sound analysis overcomes the limitations of standardized AVF stenosis diagnosis tool, prior studies have depended on conventional feature extraction methods, restricting their applicability in diverse contexts. In contrast, representation learning captures fundamental underlying factors that can be readily transferred across different contexts. We propose an approach based on deep denoising autoencoders (DAEs) that perform dimensionality reduction and reconstruction tasks using the waveform obtained through one-level discrete wavelet transform, utilizing representation learning. Our results demonstrate that the latent representation generated by the DAE surpasses expectations with an accuracy of 0.93. The incorporation of noise-mixing and the utilization of a noise-to-clean scheme effectively enhance the discriminative capabilities of the latent representation. Moreover, when employed to identify patient-specific characteristics, the latent representation exhibited performance by surpassing an accuracy of 0.92. Appropriate light-weighted methods can restore the detection performance of the excessively reduced dimensionality version and enable operation on less computational devices. Our findings suggest that representation learning is a more feasible approach for extracting auscultation features in AVF, leading to improved generalization and applicability across multiple tasks. The manipulation of latent representations holds immense potential for future advancements. Further investigations in this area are promising and warrant continued exploration.
SDRM3: A Dynamic Scheduler for Dynamic Real-time Multi-model ML Workloads
Dec 07, 2022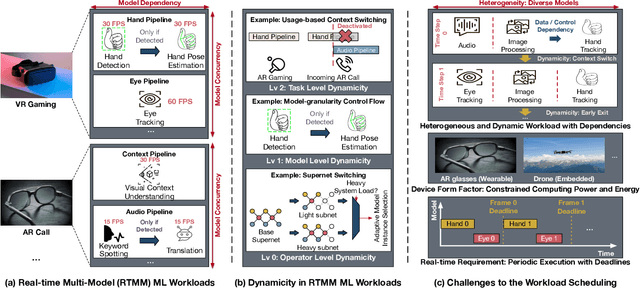
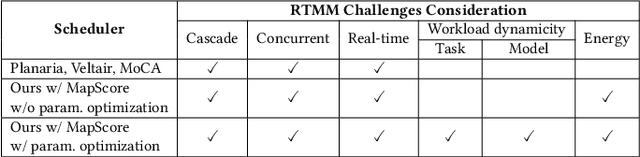
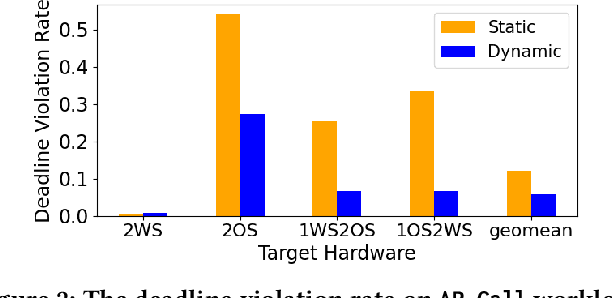
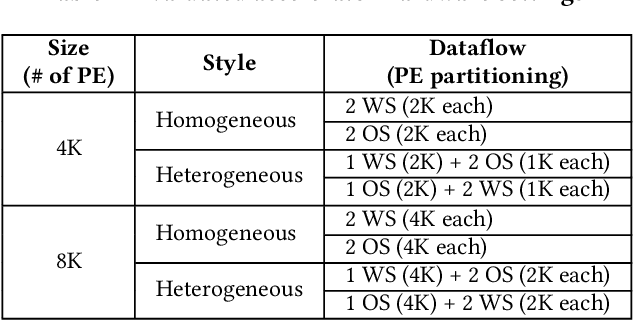
Emerging real-time multi-model ML (RTMM) workloads such as AR/VR and drone control often involve dynamic behaviors in various levels; task, model, and layers (or, ML operators) within a model. Such dynamic behaviors are new challenges to the system software in an ML system because the overall system load is unpredictable unlike traditional ML workloads. Also, the real-time processing requires to meet deadlines, and multi-model workloads involve highly heterogeneous models. As RTMM workloads often run on resource-constrained devices (e.g., VR headset), developing an effective scheduler is an important research problem. Therefore, we propose a new scheduler, SDRM3, that effectively handles various dynamicity in RTMM style workloads targeting multi-accelerator systems. To make scheduling decisions, SDRM3 quantifies the unique requirements for RTMM workloads and utilizes the quantified scores to drive scheduling decisions, considering the current system load and other inference jobs on different models and input frames. SDRM3 has tunable parameters that provide fast adaptivity to dynamic workload changes based on a gradient descent-like online optimization, which typically converges within five steps for new workloads. In addition, we also propose a method to exploit model level dynamicity based on Supernet for exploiting the trade-off between the scheduling effectiveness and model performance (e.g., accuracy), which dynamically selects a proper sub-network in a Supernet based on the system loads. In our evaluation on five realistic RTMM workload scenarios, SDRM3 reduces the overall UXCost, which is a energy-delay-product (EDP)-equivalent metric for real-time applications defined in the paper, by 37.7% and 53.2% on geometric mean (up to 97.6% and 97.1%) compared to state-of-the-art baselines, which shows the efficacy of our scheduling methodology.
Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation
Nov 23, 2021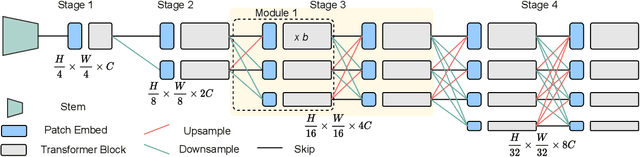

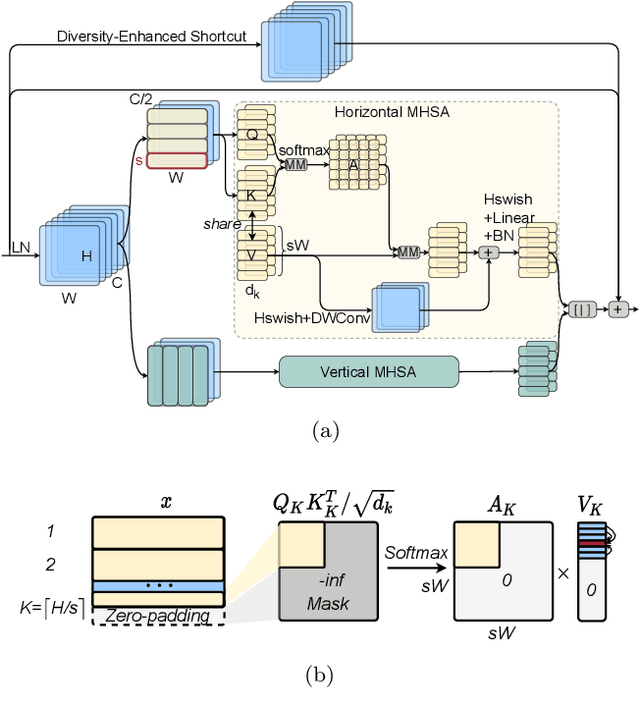
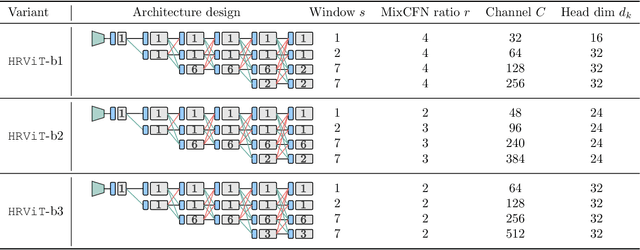
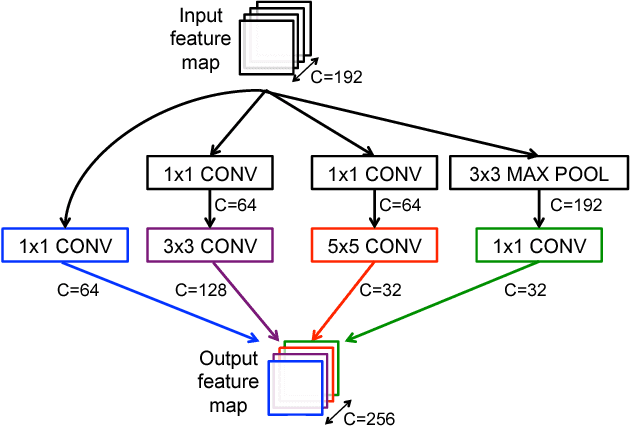
Vision Transformers (ViTs) have emerged with superior performance on computer vision tasks compared to convolutional neural network (CNN)-based models. However, ViTs are mainly designed for image classification that generate single-scale low-resolution representations, which makes dense prediction tasks such as semantic segmentation challenging for ViTs. Therefore, we propose HRViT, which enhances ViTs to learn semantically-rich and spatially-precise multi-scale representations by integrating high-resolution multi-branch architectures with ViTs. We balance the model performance and efficiency of HRViT by various branch-block co-optimization techniques. Specifically, we explore heterogeneous branch designs, reduce the redundancy in linear layers, and augment the attention block with enhanced expressiveness. Those approaches enabled HRViT to push the Pareto frontier of performance and efficiency on semantic segmentation to a new level, as our evaluation results on ADE20K and Cityscapes show. HRViT achieves 50.20% mIoU on ADE20K and 83.16% mIoU on Cityscapes, surpassing state-of-the-art MiT and CSWin backbones with an average of +1.78 mIoU improvement, 28% parameter saving, and 21% FLOPs reduction, demonstrating the potential of HRViT as a strong vision backbone for semantic segmentation.
Eyeriss v2: A Flexible and High-Performance Accelerator for Emerging Deep Neural Networks
Jul 10, 2018
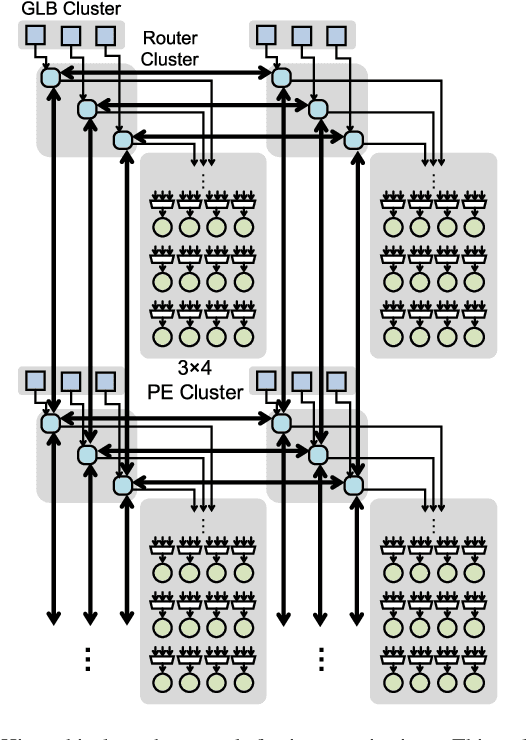
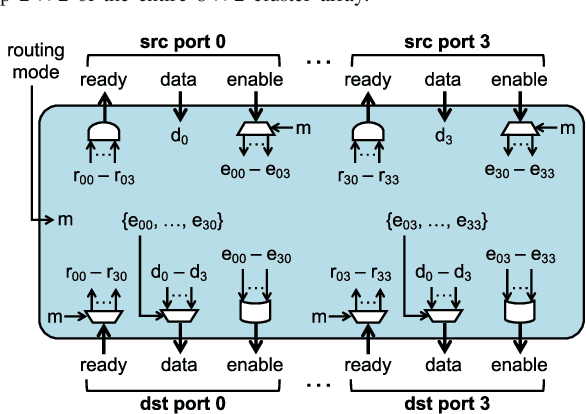
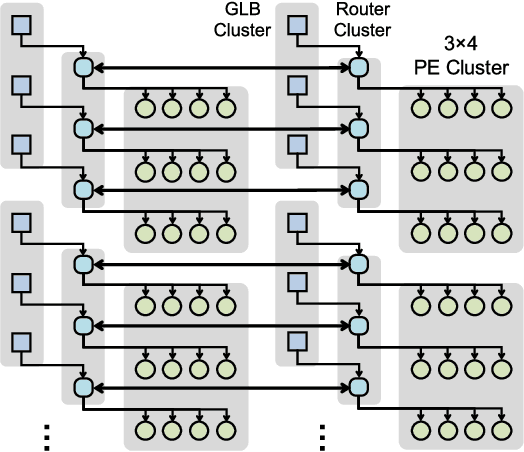
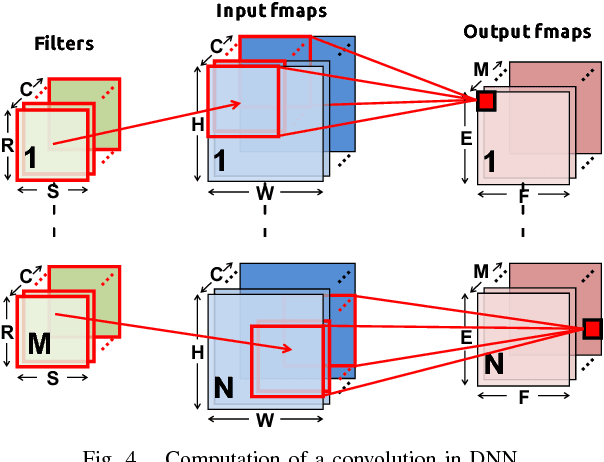
The design of DNNs has increasingly focused on reducing the computational complexity in addition to improving accuracy. While emerging DNNs tend to have fewer weights and operations, they also reduce the amount of data reuse with more widely varying layer shapes and sizes. This leads to a diverse set of DNNs, ranging from large ones with high reuse (e.g., AlexNet) to compact ones with high bandwidth requirements (e.g., MobileNet). However, many existing DNN processors depend on certain DNN properties, e.g., a large number of channels, to achieve high performance and energy efficiency and do not have sufficient flexibility to efficiently process a diverse set of DNNs. In this work, we present Eyexam, a performance analysis framework that quantitatively identifies the sources of performance loss in DNN processors. It highlights two architectural bottlenecks in many existing designs. First, their dataflows are not flexible enough to adapt to the varying layer shapes and sizes of different DNNs. Second, their network-on-chip (NoC) can't adapt to support both high data reuse and high bandwidth scenarios. Based on this analysis, we present Eyeriss v2, a high-performance DNN accelerator that adapts to a wide range of DNNs. Eyeriss v2 has a new dataflow, called Row-Stationary Plus (RS+), that enables the spatial tiling of data from all dimensions to fully utilize the parallelism for high performance. To support RS+, it has a low-cost and scalable NoC design, called hierarchical mesh, that connects the high-bandwidth global buffer to the array of processing elements (PEs) in a two-level hierarchy. This enables high-bandwidth data delivery while still being able to harness any available data reuse. Compared with Eyeriss, Eyeriss v2 has a performance increase of 10.4x-17.9x for 256 PEs, 37.7x-71.5x for 1024 PEs, and 448.8x-1086.7x for 16384 PEs on DNNs with widely varying amounts of data reuse.
Hardware for Machine Learning: Challenges and Opportunities
Oct 17, 2017

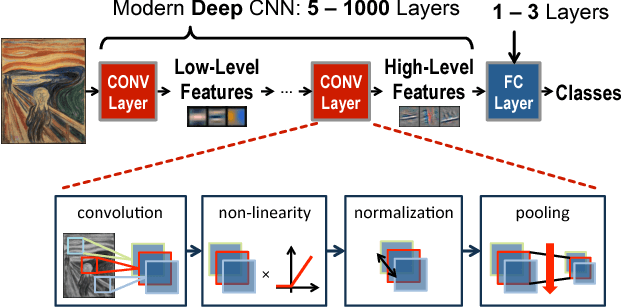
Machine learning plays a critical role in extracting meaningful information out of the zetabytes of sensor data collected every day. For some applications, the goal is to analyze and understand the data to identify trends (e.g., surveillance, portable/wearable electronics); in other applications, the goal is to take immediate action based the data (e.g., robotics/drones, self-driving cars, smart Internet of Things). For many of these applications, local embedded processing near the sensor is preferred over the cloud due to privacy or latency concerns, or limitations in the communication bandwidth. However, at the sensor there are often stringent constraints on energy consumption and cost in addition to throughput and accuracy requirements. Furthermore, flexibility is often required such that the processing can be adapted for different applications or environments (e.g., update the weights and model in the classifier). In many applications, machine learning often involves transforming the input data into a higher dimensional space, which, along with programmable weights, increases data movement and consequently energy consumption. In this paper, we will discuss how these challenges can be addressed at various levels of hardware design ranging from architecture, hardware-friendly algorithms, mixed-signal circuits, and advanced technologies (including memories and sensors).
Efficient Processing of Deep Neural Networks: A Tutorial and Survey
Aug 13, 2017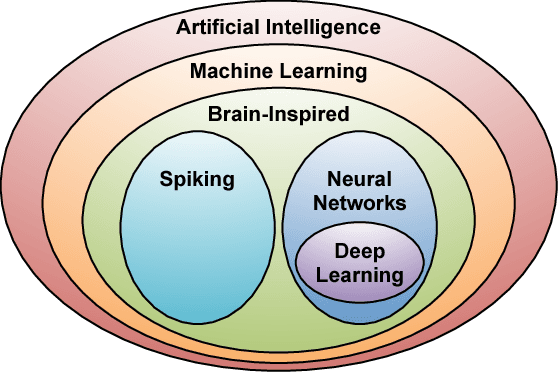

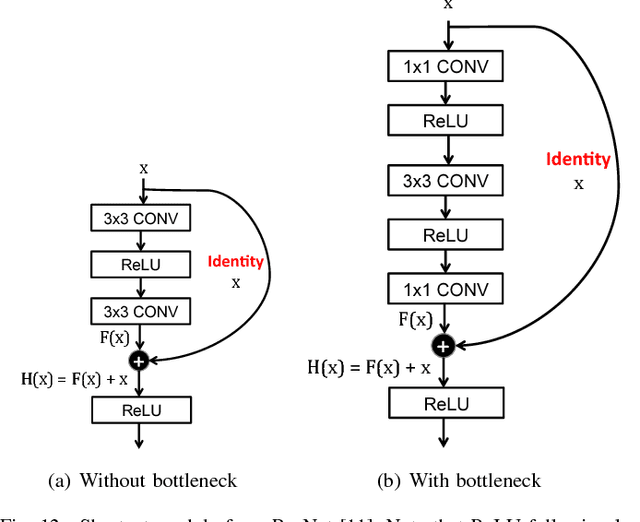
Deep neural networks (DNNs) are currently widely used for many artificial intelligence (AI) applications including computer vision, speech recognition, and robotics. While DNNs deliver state-of-the-art accuracy on many AI tasks, it comes at the cost of high computational complexity. Accordingly, techniques that enable efficient processing of DNNs to improve energy efficiency and throughput without sacrificing application accuracy or increasing hardware cost are critical to the wide deployment of DNNs in AI systems. This article aims to provide a comprehensive tutorial and survey about the recent advances towards the goal of enabling efficient processing of DNNs. Specifically, it will provide an overview of DNNs, discuss various hardware platforms and architectures that support DNNs, and highlight key trends in reducing the computation cost of DNNs either solely via hardware design changes or via joint hardware design and DNN algorithm changes. It will also summarize various development resources that enable researchers and practitioners to quickly get started in this field, and highlight important benchmarking metrics and design considerations that should be used for evaluating the rapidly growing number of DNN hardware designs, optionally including algorithmic co-designs, being proposed in academia and industry. The reader will take away the following concepts from this article: understand the key design considerations for DNNs; be able to evaluate different DNN hardware implementations with benchmarks and comparison metrics; understand the trade-offs between various hardware architectures and platforms; be able to evaluate the utility of various DNN design techniques for efficient processing; and understand recent implementation trends and opportunities.
Designing Energy-Efficient Convolutional Neural Networks using Energy-Aware Pruning
Apr 18, 2017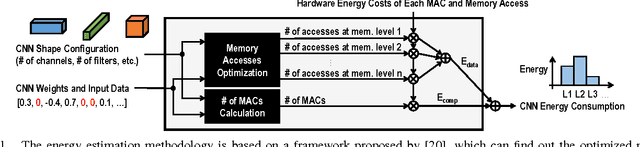
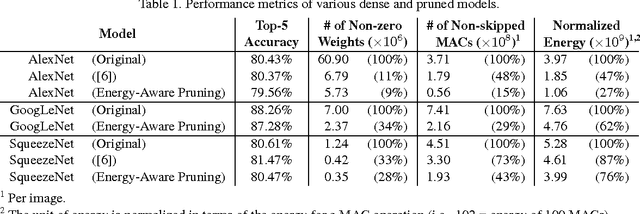
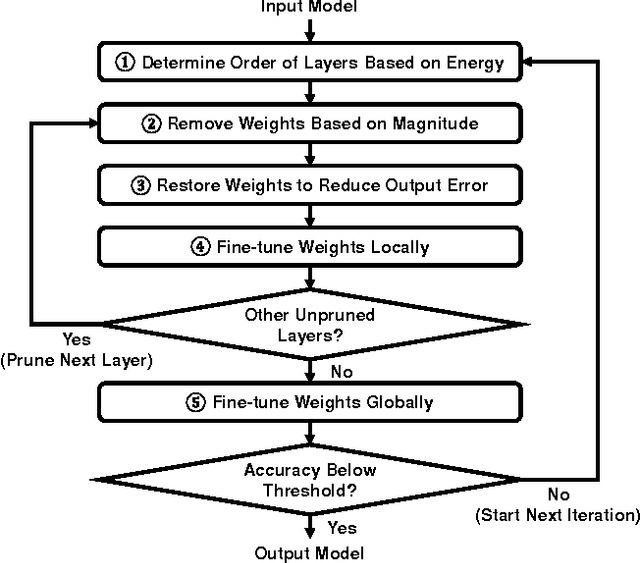
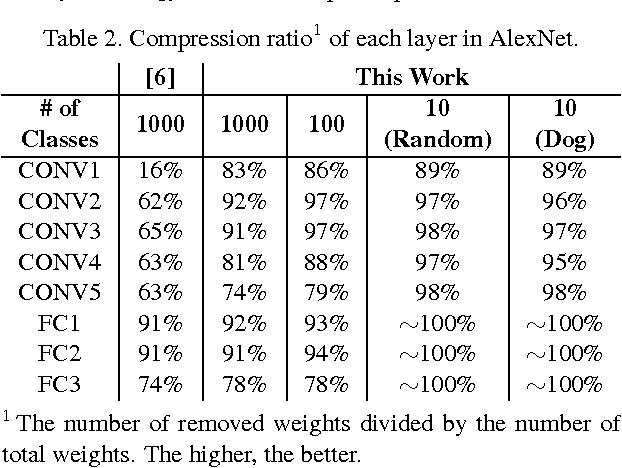
Deep convolutional neural networks (CNNs) are indispensable to state-of-the-art computer vision algorithms. However, they are still rarely deployed on battery-powered mobile devices, such as smartphones and wearable gadgets, where vision algorithms can enable many revolutionary real-world applications. The key limiting factor is the high energy consumption of CNN processing due to its high computational complexity. While there are many previous efforts that try to reduce the CNN model size or amount of computation, we find that they do not necessarily result in lower energy consumption, and therefore do not serve as a good metric for energy cost estimation. To close the gap between CNN design and energy consumption optimization, we propose an energy-aware pruning algorithm for CNNs that directly uses energy consumption estimation of a CNN to guide the pruning process. The energy estimation methodology uses parameters extrapolated from actual hardware measurements that target realistic battery-powered system setups. The proposed layer-by-layer pruning algorithm also prunes more aggressively than previously proposed pruning methods by minimizing the error in output feature maps instead of filter weights. For each layer, the weights are first pruned and then locally fine-tuned with a closed-form least-square solution to quickly restore the accuracy. After all layers are pruned, the entire network is further globally fine-tuned using back-propagation. With the proposed pruning method, the energy consumption of AlexNet and GoogLeNet are reduced by 3.7x and 1.6x, respectively, with less than 1% top-5 accuracy loss. Finally, we show that pruning the AlexNet with a reduced number of target classes can greatly decrease the number of weights but the energy reduction is limited. Energy modeling tool and energy-aware pruned models available at http://eyeriss.mit.edu/energy.html
Towards Closing the Energy Gap Between HOG and CNN Features for Embedded Vision
Mar 17, 2017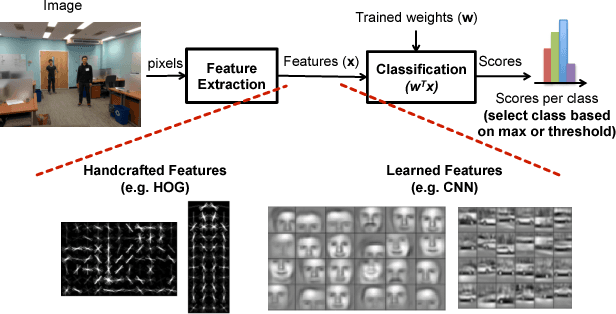
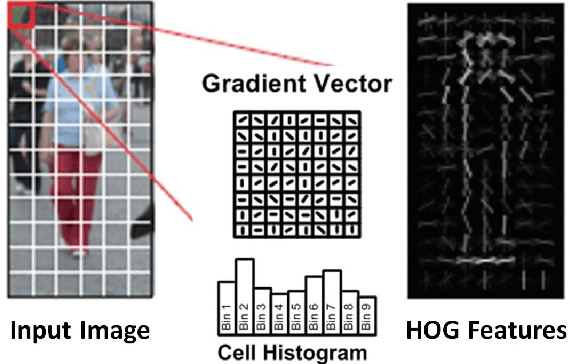


Computer vision enables a wide range of applications in robotics/drones, self-driving cars, smart Internet of Things, and portable/wearable electronics. For many of these applications, local embedded processing is preferred due to privacy and/or latency concerns. Accordingly, energy-efficient embedded vision hardware delivering real-time and robust performance is crucial. While deep learning is gaining popularity in several computer vision algorithms, a significant energy consumption difference exists compared to traditional hand-crafted approaches. In this paper, we provide an in-depth analysis of the computation, energy and accuracy trade-offs between learned features such as deep Convolutional Neural Networks (CNN) and hand-crafted features such as Histogram of Oriented Gradients (HOG). This analysis is supported by measurements from two chips that implement these algorithms. Our goal is to understand the source of the energy discrepancy between the two approaches and to provide insight about the potential areas where CNNs can be improved and eventually approach the energy-efficiency of HOG while maintaining its outstanding performance accuracy.