 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharacterizing State Space Model (SSM) and SSM-Transformer Hybrid Language Model Performance with Long Context Length
Jul 16, 2025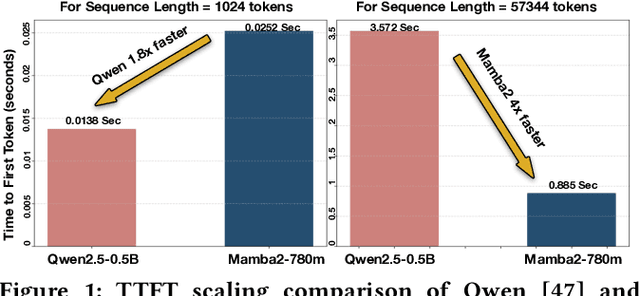

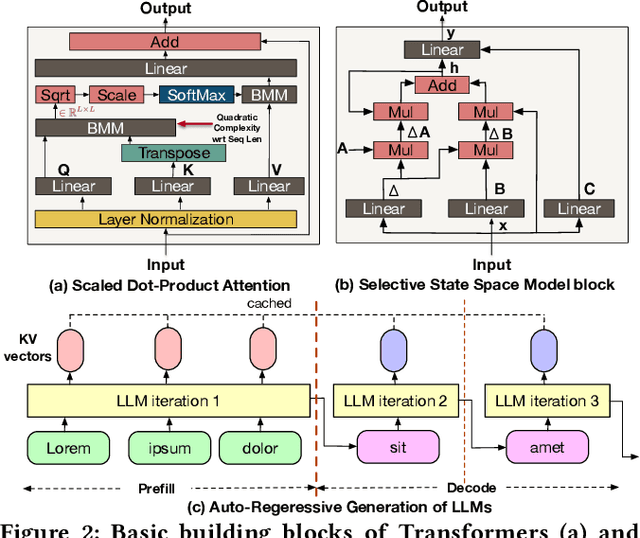
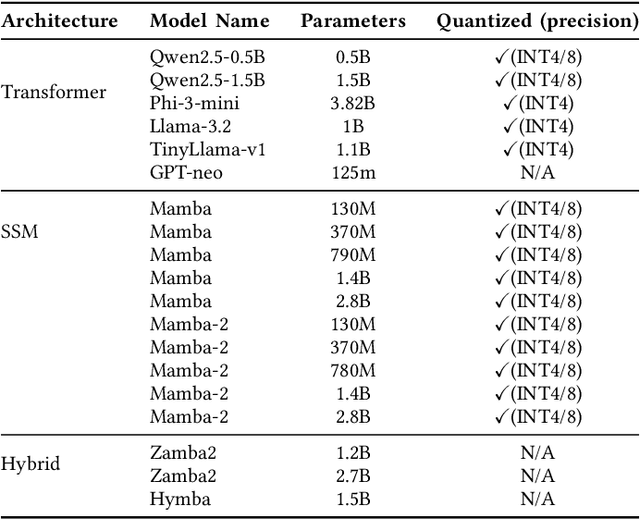
The demand for machine intelligence capable of processing continuous, long-context inputs on local devices is growing rapidly. However, the quadratic complexity and memory requirements of traditional Transformer architectures make them inefficient and often unusable for these tasks. This has spurred a paradigm shift towards new architectures like State Space Models (SSMs) and hybrids, which promise near-linear scaling. While most current research focuses on the accuracy and theoretical throughput of these models, a systematic performance characterization on practical consumer hardware is critically needed to guide system-level optimization and unlock new applications. To address this gap, we present a comprehensive, comparative benchmarking of carefully selected Transformer, SSM, and hybrid models specifically for long-context inference on consumer and embedded GPUs. Our analysis reveals that SSMs are not only viable but superior for this domain, capable of processing sequences up to 220K tokens on a 24GB consumer GPU-approximately 4x longer than comparable Transformers. While Transformers may be up to 1.8x faster at short sequences, SSMs demonstrate a dramatic performance inversion, becoming up to 4x faster at very long contexts (~57K tokens). Our operator-level analysis reveals that custom, hardware-aware SSM kernels dominate the inference runtime, accounting for over 55% of latency on edge platforms, identifying them as a primary target for future hardware acceleration. We also provide detailed, device-specific characterization results to guide system co-design for the edge. To foster further research, we will open-source our characterization framework.
Performance Implications of Multi-Chiplet Neural Processing Units on Autonomous Driving Perception
Nov 24, 2024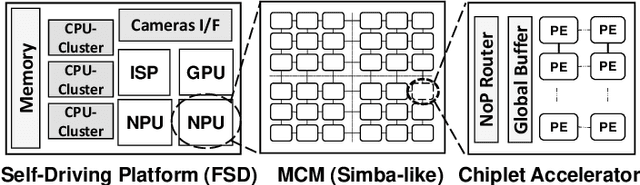
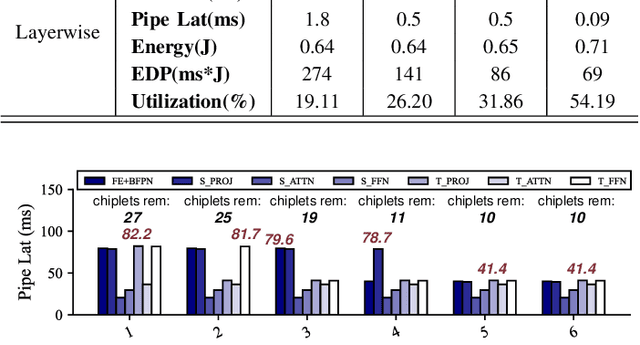
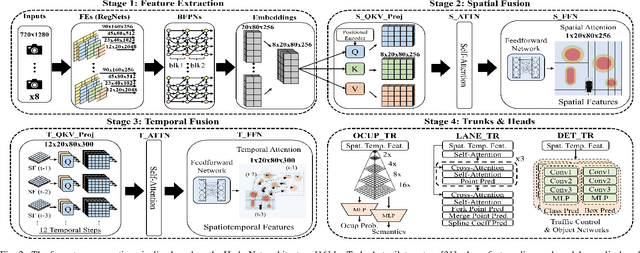
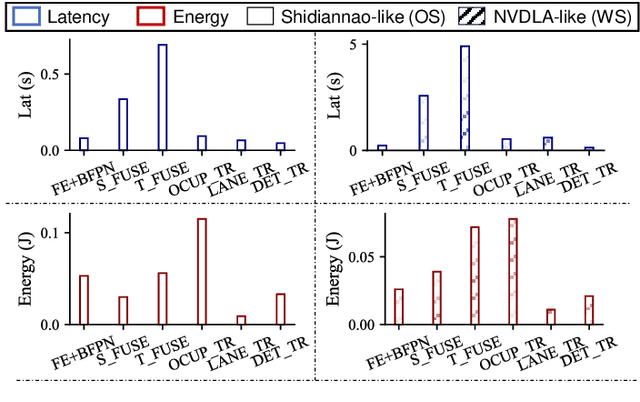
We study the application of emerging chiplet-based Neural Processing Units to accelerate vehicular AI perception workloads in constrained automotive settings. The motivation stems from how chiplets technology is becoming integral to emerging vehicular architectures, providing a cost-effective trade-off between performance, modularity, and customization; and from perception models being the most computationally demanding workloads in a autonomous driving system. Using the Tesla Autopilot perception pipeline as a case study, we first breakdown its constituent models and profile their performance on different chiplet accelerators. From the insights, we propose a novel scheduling strategy to efficiently deploy perception workloads on multi-chip AI accelerators. Our experiments using a standard DNN performance simulator, MAESTRO, show our approach realizes 82% and 2.8x increase in throughput and processing engines utilization compared to monolithic accelerator designs.
Efficient Depth Estimation for Unstable Stereo Camera Systems on AR Glasses
Nov 15, 2024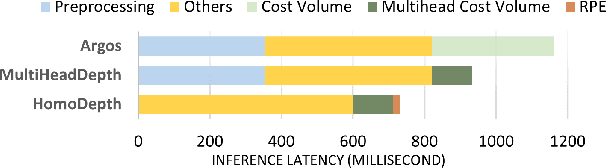
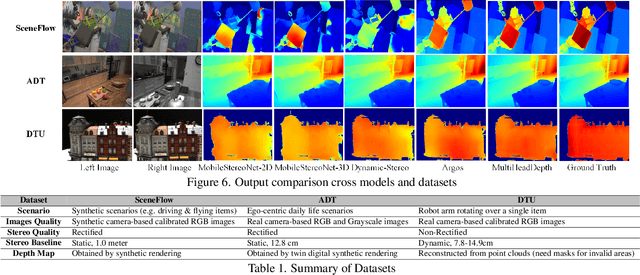

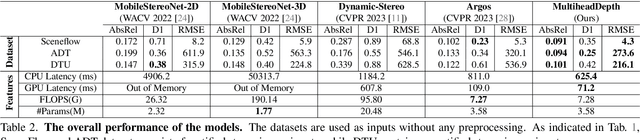
Stereo depth estimation is a fundamental component in augmented reality (AR) applications. Although AR applications require very low latency for their real-time applications, traditional depth estimation models often rely on time-consuming preprocessing steps such as rectification to achieve high accuracy. Also, non standard ML operator based algorithms such as cost volume also require significant latency, which is aggravated on compute resource-constrained mobile platforms. Therefore, we develop hardware-friendly alternatives to the costly cost volume and preprocessing and design two new models based on them, MultiHeadDepth and HomoDepth. Our approaches for cost volume is replacing it with a new group-pointwise convolution-based operator and approximation of consine similarity based on layernorm and dot product. For online stereo rectification (preprocessing), we introduce homograhy matrix prediction network with a rectification positional encoding (RPE), which delivers both low latency and robustness to unrectified images, which eliminates the needs for preprocessing. Our MultiHeadDepth, which includes optimized cost volume, provides 11.8-30.3% improvements in accuracy and 22.9-25.2% reduction in latency compared to a state-of-the-art depth estimation model for AR glasses from industry. Our HomoDepth, which includes optimized preprocessing (Homograhpy + RPE) upon MultiHeadDepth, can process unrectified images and reduce the end-to-end latency by 44.5%. We adopt a multi-task learning framework to handle misaligned stereo inputs on HomoDepth, which reduces theAbsRel error by 10.0-24.3%. The results demonstrate the efficacy of our approaches in achieving both high model performance with low latency, which makes a step forward toward practical depth estimation on future AR devices.
Characterizing the Accuracy - Efficiency Trade-off of Low-rank Decomposition in Language Models
May 10, 2024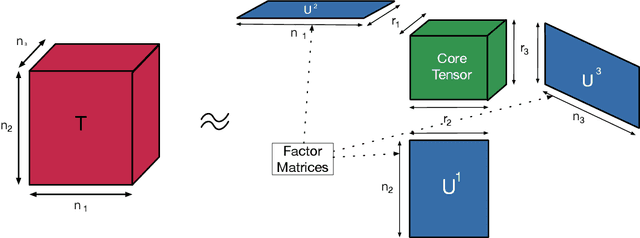

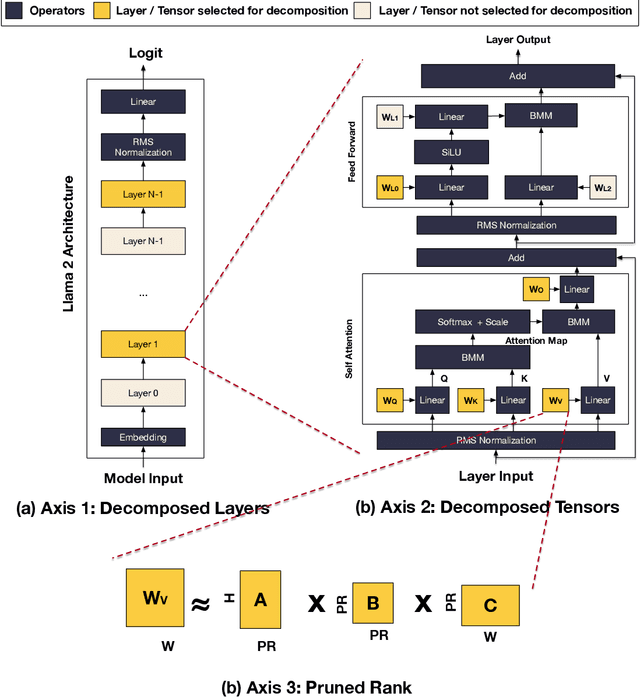

Large language models (LLMs) have emerged and presented their general problem-solving capabilities with one model. However, the model size has increased dramatically with billions of parameters to enable such broad problem-solving capabilities. In addition, due to the dominance of matrix-matrix and matrix-vector multiplications in LLMs, the compute-to-model size ratio is significantly lower than that of CNNs. This shift pushes LLMs from a computation-bound regime to a memory-bound regime. Therefore, optimizing the memory footprint and traffic is an important optimization direction for LLMs today. Model compression methods such as quantization and parameter pruning have been actively explored for achieving the memory footprint and traffic optimization. However, the accuracy-efficiency trade-off of rank pruning for LLMs is not well-understood yet. Therefore, we characterize the accuracy-efficiency trade-off of a low-rank decomposition method, specifically Tucker decomposition, on recent language models, including an open-source LLM, Llama 2. We formalize the low-rank decomposition design space and show that the decomposition design space is enormous (e.g., O($2^{37}$) for Llama2-7B). To navigate such a vast design space, we formulate the design space and perform thorough case studies of accuracy-efficiency trade-offs using six widely used LLM benchmarks on BERT and Llama 2 models. Our results show that we can achieve a 9\% model size reduction with minimal accuracy drops, which range from 4\%p to 10\%p, depending on the difficulty of the benchmark, without any retraining to recover accuracy after decomposition. The results show that low-rank decomposition can be a promising direction for LLM-based applications that require real-time service in scale (e.g., AI agent assist and real-time coding assistant), where the latency is as important as the model accuracy.
SCAR: Scheduling Multi-Model AI Workloads on Heterogeneous Multi-Chiplet Module Accelerators
May 01, 2024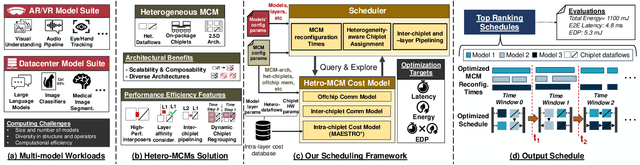
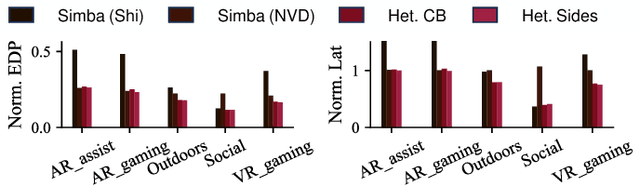

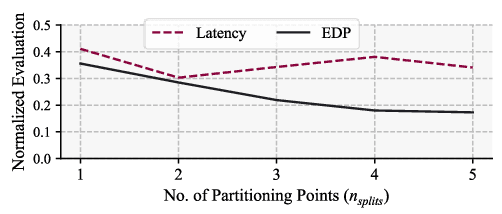
Emerging multi-model workloads with heavy models like recent large language models significantly increased the compute and memory demands on hardware. To address such increasing demands, designing a scalable hardware architecture became a key problem. Among recent solutions, the 2.5D silicon interposer multi-chip module (MCM)-based AI accelerator has been actively explored as a promising scalable solution due to their significant benefits in the low engineering cost and composability. However, previous MCM accelerators are based on homogeneous architectures with fixed dataflow, which encounter major challenges from highly heterogeneous multi-model workloads due to their limited workload adaptivity. Therefore, in this work, we explore the opportunity in the heterogeneous dataflow MCM AI accelerators. We identify the scheduling of multi-model workload on heterogeneous dataflow MCM AI accelerator is an important and challenging problem due to its significance and scale, which reaches O(10^18) scale even for a single model case on 6x6 chiplets. We develop a set of heuristics to navigate the huge scheduling space and codify them into a scheduler with advanced techniques such as inter-chiplet pipelining. Our evaluation on ten multi-model workload scenarios for datacenter multitenancy and AR/VR use-cases has shown the efficacy of our approach, achieving on average 35.3% and 31.4% less energy-delay product (EDP) for the respective applications settings compared to homogeneous baselines.
NonGEMM Bench: Understanding the Performance Horizon of the Latest ML Workloads with NonGEMM Workloads
Apr 17, 2024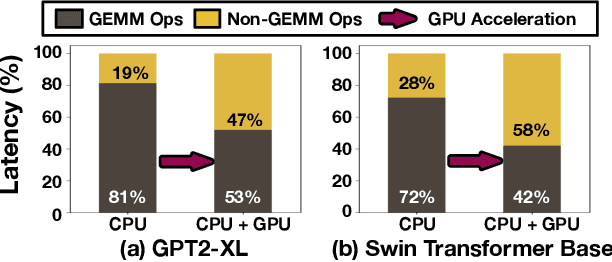
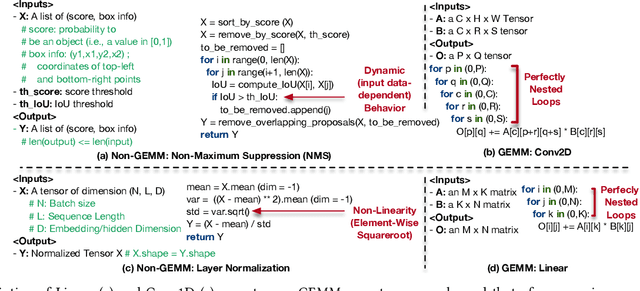
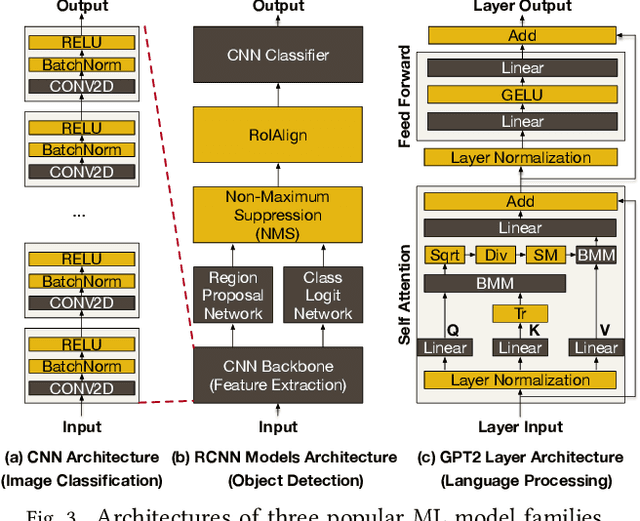
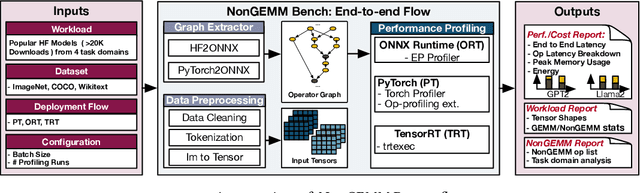
Machine Learning (ML) operators are the building blocks to design ML models with various target applications. GEneral Matrix Multiplication (GEMM) operators are the backbone of ML models. They are notorious for being computationally expensive requiring billions of multiply-and-accumulate. Therefore, significant effort has been put to study and optimize the GEMM operators in order to speed up the execution of ML models. GPUs and accelerators are widely deployed to accelerate ML workloads by optimizing the execution of GEMM operators. Nonetheless, the performance of NonGEMM operators have not been studied as thoroughly as GEMMs. Therefore, this paper describes \bench, a benchmark to study NonGEMM operators. We first construct \bench using popular ML workloads from different domains, then perform case studies on various grade GPU platforms to analyze the behavior of NonGEMM operators in GPU accelerated systems. Finally, we present some key takeaways to bridge the gap between GEMM and NonGEMM operators and to offer the community with potential new optimization directions.
Inter-Layer Scheduling Space Exploration for Multi-model Inference on Heterogeneous Chiplets
Dec 14, 2023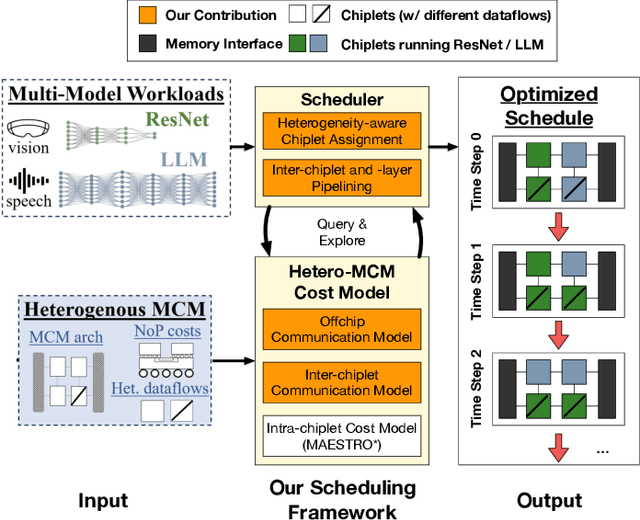
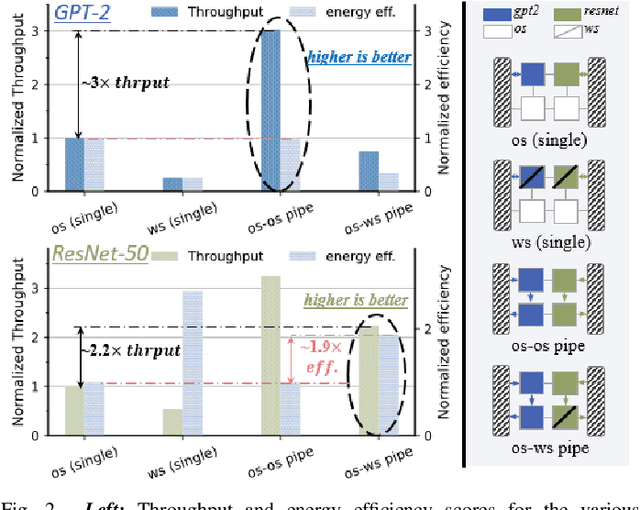
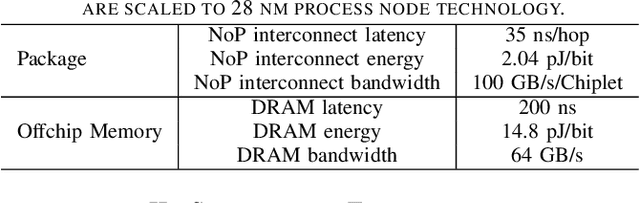
To address increasing compute demand from recent multi-model workloads with heavy models like large language models, we propose to deploy heterogeneous chiplet-based multi-chip module (MCM)-based accelerators. We develop an advanced scheduling framework for heterogeneous MCM accelerators that comprehensively consider complex heterogeneity and inter-chiplet pipelining. Our experiments using our framework on GPT-2 and ResNet-50 models on a 4-chiplet system have shown upto 2.2x and 1.9x increase in throughput and energy efficiency, compared to a monolithic accelerator with an optimized output-stationary dataflow.
SDRM3: A Dynamic Scheduler for Dynamic Real-time Multi-model ML Workloads
Dec 07, 2022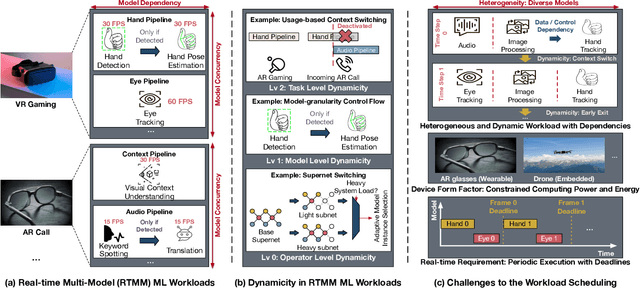
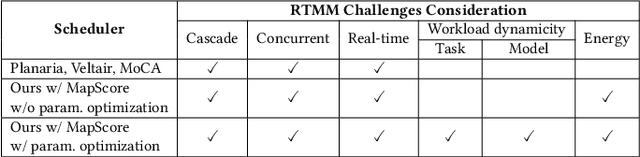
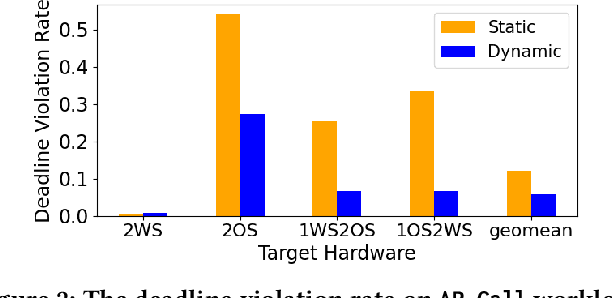
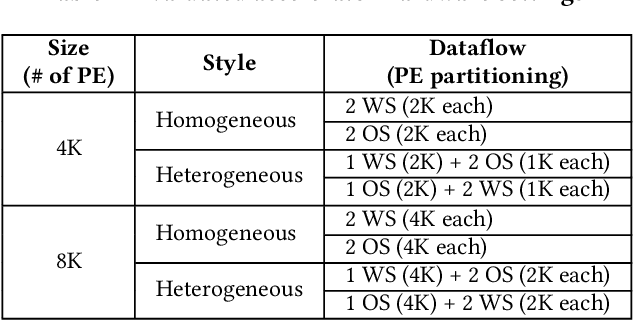
Emerging real-time multi-model ML (RTMM) workloads such as AR/VR and drone control often involve dynamic behaviors in various levels; task, model, and layers (or, ML operators) within a model. Such dynamic behaviors are new challenges to the system software in an ML system because the overall system load is unpredictable unlike traditional ML workloads. Also, the real-time processing requires to meet deadlines, and multi-model workloads involve highly heterogeneous models. As RTMM workloads often run on resource-constrained devices (e.g., VR headset), developing an effective scheduler is an important research problem. Therefore, we propose a new scheduler, SDRM3, that effectively handles various dynamicity in RTMM style workloads targeting multi-accelerator systems. To make scheduling decisions, SDRM3 quantifies the unique requirements for RTMM workloads and utilizes the quantified scores to drive scheduling decisions, considering the current system load and other inference jobs on different models and input frames. SDRM3 has tunable parameters that provide fast adaptivity to dynamic workload changes based on a gradient descent-like online optimization, which typically converges within five steps for new workloads. In addition, we also propose a method to exploit model level dynamicity based on Supernet for exploiting the trade-off between the scheduling effectiveness and model performance (e.g., accuracy), which dynamically selects a proper sub-network in a Supernet based on the system loads. In our evaluation on five realistic RTMM workload scenarios, SDRM3 reduces the overall UXCost, which is a energy-delay-product (EDP)-equivalent metric for real-time applications defined in the paper, by 37.7% and 53.2% on geometric mean (up to 97.6% and 97.1%) compared to state-of-the-art baselines, which shows the efficacy of our scheduling methodology.
XRBench: An Extended Reality (XR) Machine Learning Benchmark Suite for the Metaverse
Nov 16, 2022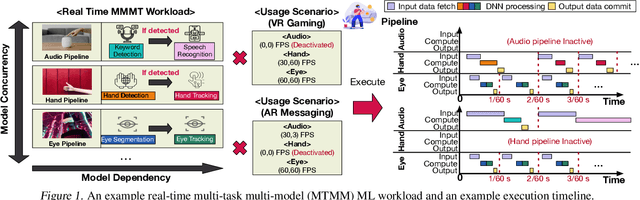
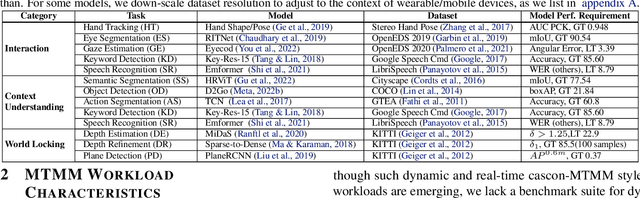

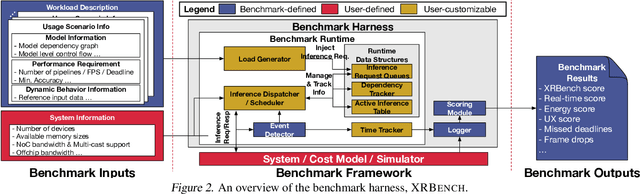
Real-time multi-model multi-task (MMMT) workloads, a new form of deep learning inference workloads, are emerging for applications areas like extended reality (XR) to support metaverse use cases. These workloads combine user interactivity with computationally complex machine learning (ML) activities. Compared to standard ML applications, these ML workloads present unique difficulties and constraints. Real-time MMMT workloads impose heterogeneity and concurrency requirements on future ML systems and devices, necessitating the development of new capabilities. This paper begins with a discussion of the various characteristics of these real-time MMMT ML workloads and presents an ontology for evaluating the performance of future ML hardware for XR systems. Next, we present XRBench, a collection of MMMT ML tasks, models, and usage scenarios that execute these models in three representative ways: cascaded, concurrent, and cascaded-concurrency for XR use cases. Finally, we emphasize the need for new metrics that capture the requirements properly. We hope that our work will stimulate research and lead to the development of a new generation of ML systems for XR use cases.
Multi-Scale High-Resolution Vision Transformer for Semantic Segmentation
Nov 23, 2021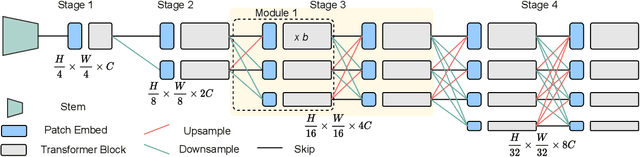

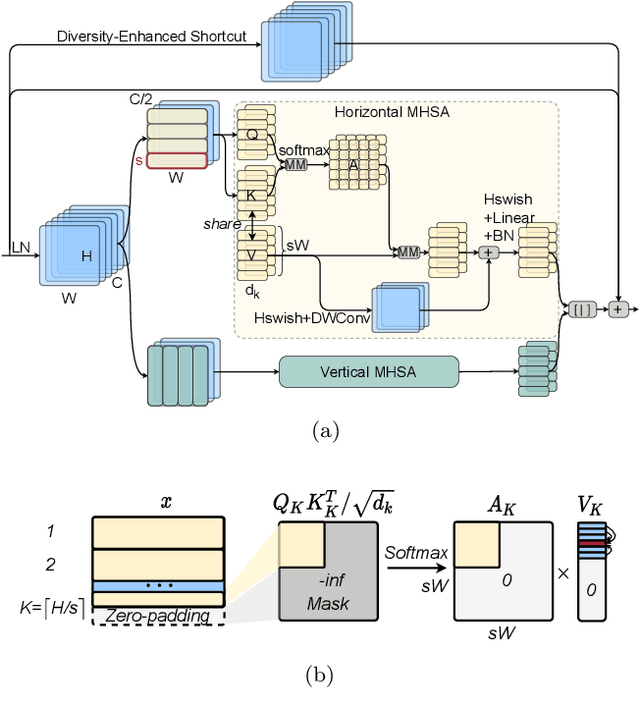
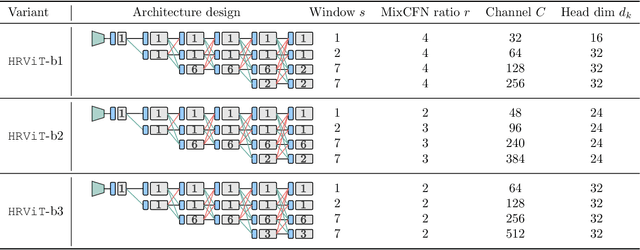
Vision Transformers (ViTs) have emerged with superior performance on computer vision tasks compared to convolutional neural network (CNN)-based models. However, ViTs are mainly designed for image classification that generate single-scale low-resolution representations, which makes dense prediction tasks such as semantic segmentation challenging for ViTs. Therefore, we propose HRViT, which enhances ViTs to learn semantically-rich and spatially-precise multi-scale representations by integrating high-resolution multi-branch architectures with ViTs. We balance the model performance and efficiency of HRViT by various branch-block co-optimization techniques. Specifically, we explore heterogeneous branch designs, reduce the redundancy in linear layers, and augment the attention block with enhanced expressiveness. Those approaches enabled HRViT to push the Pareto frontier of performance and efficiency on semantic segmentation to a new level, as our evaluation results on ADE20K and Cityscapes show. HRViT achieves 50.20% mIoU on ADE20K and 83.16% mIoU on Cityscapes, surpassing state-of-the-art MiT and CSWin backbones with an average of +1.78 mIoU improvement, 28% parameter saving, and 21% FLOPs reduction, demonstrating the potential of HRViT as a strong vision backbone for semantic segmentation.