 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Implications of Multi-Chiplet Neural Processing Units on Autonomous Driving Perception
Nov 24, 2024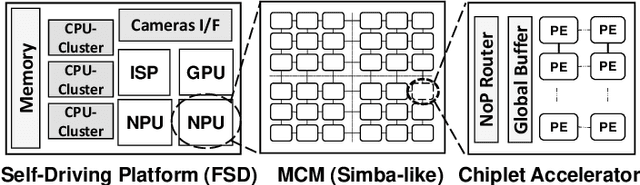
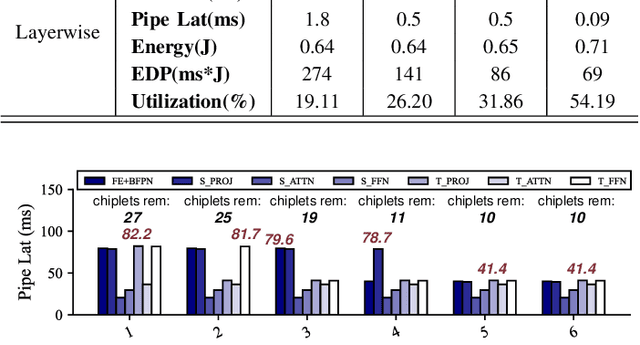
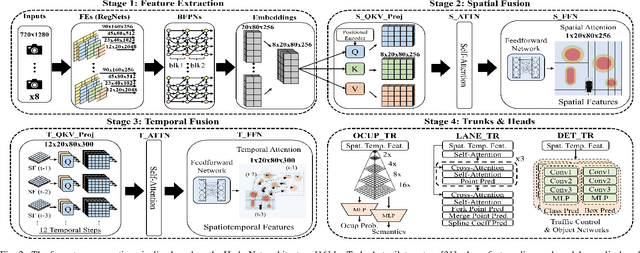
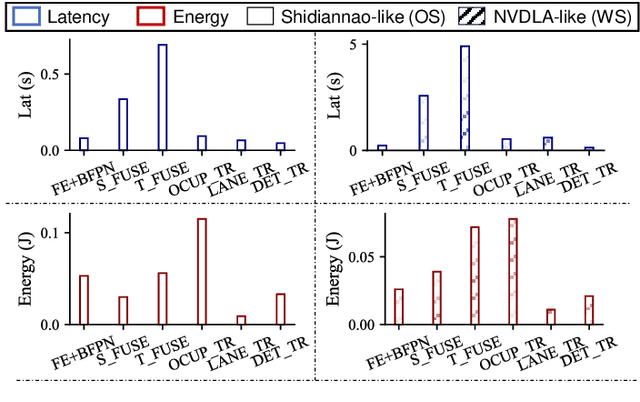
We study the application of emerging chiplet-based Neural Processing Units to accelerate vehicular AI perception workloads in constrained automotive settings. The motivation stems from how chiplets technology is becoming integral to emerging vehicular architectures, providing a cost-effective trade-off between performance, modularity, and customization; and from perception models being the most computationally demanding workloads in a autonomous driving system. Using the Tesla Autopilot perception pipeline as a case study, we first breakdown its constituent models and profile their performance on different chiplet accelerators. From the insights, we propose a novel scheduling strategy to efficiently deploy perception workloads on multi-chip AI accelerators. Our experiments using a standard DNN performance simulator, MAESTRO, show our approach realizes 82% and 2.8x increase in throughput and processing engines utilization compared to monolithic accelerator designs.
SCAR: Scheduling Multi-Model AI Workloads on Heterogeneous Multi-Chiplet Module Accelerators
May 01, 2024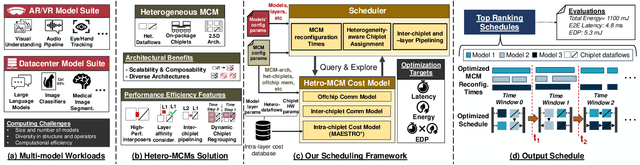
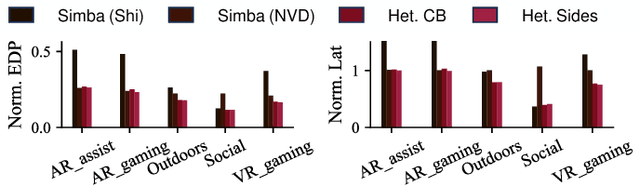

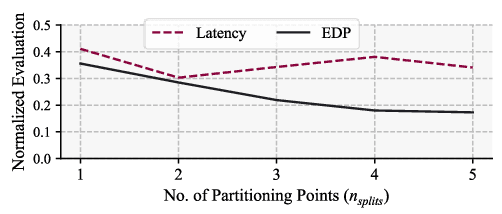
Emerging multi-model workloads with heavy models like recent large language models significantly increased the compute and memory demands on hardware. To address such increasing demands, designing a scalable hardware architecture became a key problem. Among recent solutions, the 2.5D silicon interposer multi-chip module (MCM)-based AI accelerator has been actively explored as a promising scalable solution due to their significant benefits in the low engineering cost and composability. However, previous MCM accelerators are based on homogeneous architectures with fixed dataflow, which encounter major challenges from highly heterogeneous multi-model workloads due to their limited workload adaptivity. Therefore, in this work, we explore the opportunity in the heterogeneous dataflow MCM AI accelerators. We identify the scheduling of multi-model workload on heterogeneous dataflow MCM AI accelerator is an important and challenging problem due to its significance and scale, which reaches O(10^18) scale even for a single model case on 6x6 chiplets. We develop a set of heuristics to navigate the huge scheduling space and codify them into a scheduler with advanced techniques such as inter-chiplet pipelining. Our evaluation on ten multi-model workload scenarios for datacenter multitenancy and AR/VR use-cases has shown the efficacy of our approach, achieving on average 35.3% and 31.4% less energy-delay product (EDP) for the respective applications settings compared to homogeneous baselines.
Inter-Layer Scheduling Space Exploration for Multi-model Inference on Heterogeneous Chiplets
Dec 14, 2023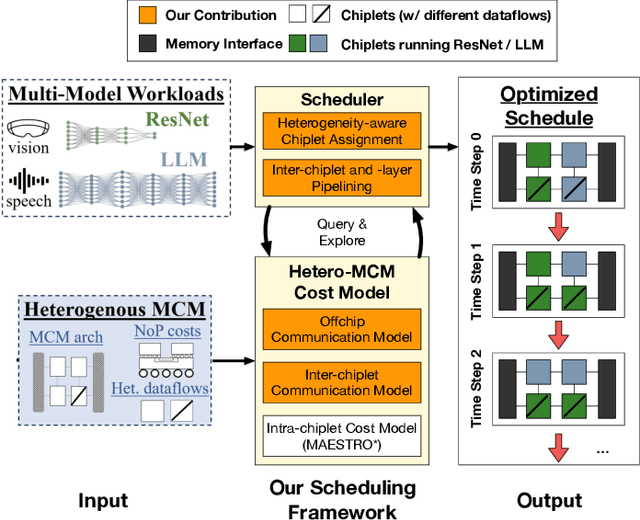
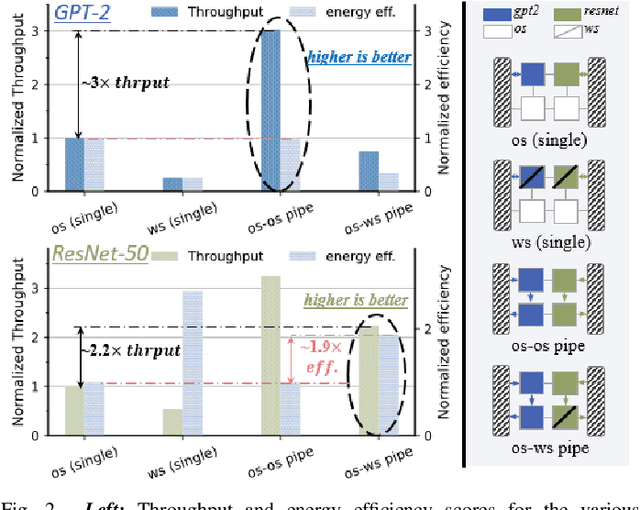
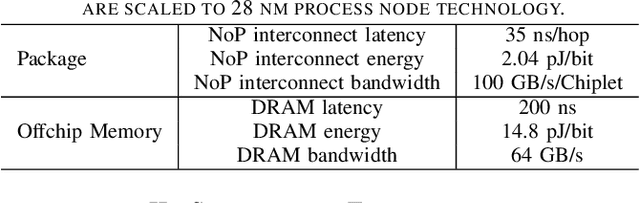
To address increasing compute demand from recent multi-model workloads with heavy models like large language models, we propose to deploy heterogeneous chiplet-based multi-chip module (MCM)-based accelerators. We develop an advanced scheduling framework for heterogeneous MCM accelerators that comprehensively consider complex heterogeneity and inter-chiplet pipelining. Our experiments using our framework on GPT-2 and ResNet-50 models on a 4-chiplet system have shown upto 2.2x and 1.9x increase in throughput and energy efficiency, compared to a monolithic accelerator with an optimized output-stationary dataflow.
MaGNAS: A Mapping-Aware Graph Neural Architecture Search Framework for Heterogeneous MPSoC Deployment
Jul 16, 2023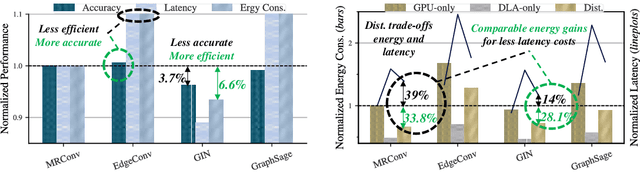
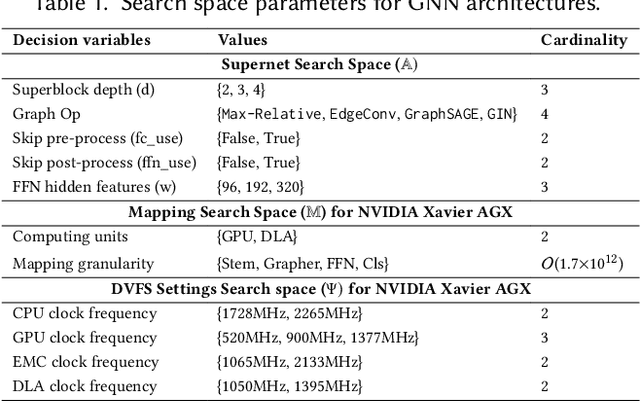
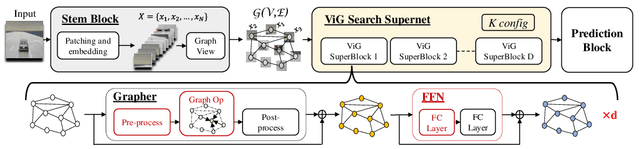
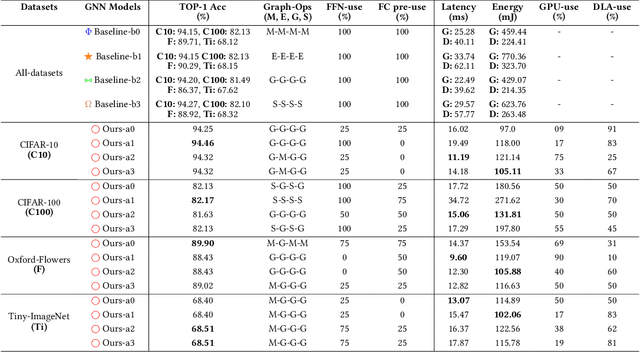
Graph Neural Networks (GNNs) are becoming increasingly popular for vision-based applications due to their intrinsic capacity in modeling structural and contextual relations between various parts of an image frame. On another front, the rising popularity of deep vision-based applications at the edge has been facilitated by the recent advancements in heterogeneous multi-processor Systems on Chips (MPSoCs) that enable inference under real-time, stringent execution requirements. By extension, GNNs employed for vision-based applications must adhere to the same execution requirements. Yet contrary to typical deep neural networks, the irregular flow of graph learning operations poses a challenge to running GNNs on such heterogeneous MPSoC platforms. In this paper, we propose a novel unified design-mapping approach for efficient processing of vision GNN workloads on heterogeneous MPSoC platforms. Particularly, we develop MaGNAS, a mapping-aware Graph Neural Architecture Search framework. MaGNAS proposes a GNN architectural design space coupled with prospective mapping options on a heterogeneous SoC to identify model architectures that maximize on-device resource efficiency. To achieve this, MaGNAS employs a two-tier evolutionary search to identify optimal GNNs and mapping pairings that yield the best performance trade-offs. Through designing a supernet derived from the recent Vision GNN (ViG) architecture, we conducted experiments on four (04) state-of-the-art vision datasets using both (i) a real hardware SoC platform (NVIDIA Xavier AGX) and (ii) a performance/cost model simulator for DNN accelerators. Our experimental results demonstrate that MaGNAS is able to provide 1.57x latency speedup and is 3.38x more energy-efficient for several vision datasets executed on the Xavier MPSoC vs. the GPU-only deployment while sustaining an average 0.11% accuracy reduction from the baseline.
Map-and-Conquer: Energy-Efficient Mapping of Dynamic Neural Nets onto Heterogeneous MPSoCs
Feb 24, 2023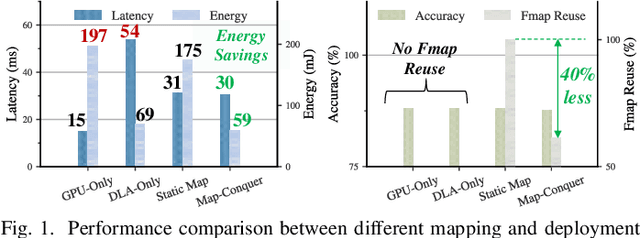
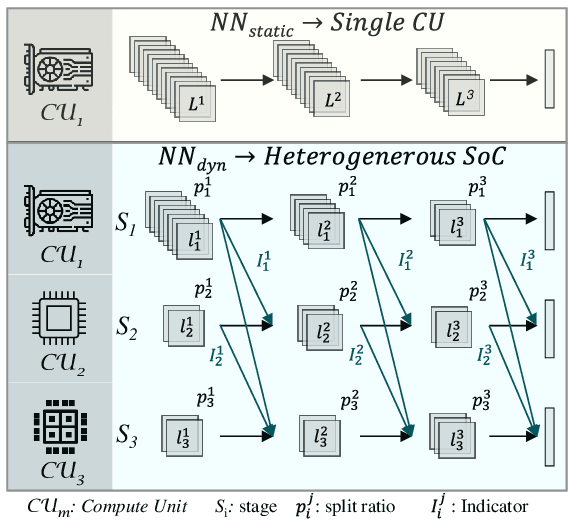

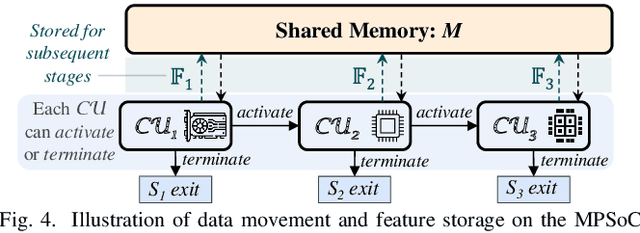
Heterogeneous MPSoCs comprise diverse processing units of varying compute capabilities. To date, the mapping strategies of neural networks (NNs) onto such systems are yet to exploit the full potential of processing parallelism, made possible through both the intrinsic NNs' structure and underlying hardware composition. In this paper, we propose a novel framework to effectively map NNs onto heterogeneous MPSoCs in a manner that enables them to leverage the underlying processing concurrency. Specifically, our approach identifies an optimal partitioning scheme of the NN along its `width' dimension, which facilitates deployment of concurrent NN blocks onto different hardware computing units. Additionally, our approach contributes a novel scheme to deploy partitioned NNs onto the MPSoC as dynamic multi-exit networks for additional performance gains. Our experiments on a standard MPSoC platform have yielded dynamic mapping configurations that are 2.1x more energy-efficient than the GPU-only mapping while incurring 1.7x less latency than DLA-only mapping.
SEO: Safety-Aware Energy Optimization Framework for Multi-Sensor Neural Controllers at the Edge
Feb 24, 2023Runtime energy management has become quintessential for multi-sensor autonomous systems at the edge for achieving high performance given the platform constraints. Typical for such systems, however, is to have their controllers designed with formal guarantees on safety that precede in priority such optimizations, which in turn limits their application in real settings. In this paper, we propose a novel energy optimization framework that is aware of the autonomous system's safety state, and leverages it to regulate the application of energy optimization methods so that the system's formal safety properties are preserved. In particular, through the formal characterization of a system's safety state as a dynamic processing deadline, the computing workloads of the underlying models can be adapted accordingly. For our experiments, we model two popular runtime energy optimization methods, offloading and gating, and simulate an autonomous driving system (ADS) use-case in the CARLA simulation environment with performance characterizations obtained from the standard Nvidia Drive PX2 ADS platform. Our results demonstrate that through a formal awareness of the perceived risks in the test case scenario, energy efficiency gains are still achieved (reaching 89.9%) while maintaining the desired safety properties.
EnergyShield: Provably-Safe Offloading of Neural Network Controllers for Energy Efficiency
Feb 13, 2023To mitigate the high energy demand of Neural Network (NN) based Autonomous Driving Systems (ADSs), we consider the problem of offloading NN controllers from the ADS to nearby edge-computing infrastructure, but in such a way that formal vehicle safety properties are guaranteed. In particular, we propose the EnergyShield framework, which repurposes a controller ''shield'' as a low-power runtime safety monitor for the ADS vehicle. Specifically, the shield in EnergyShield provides not only safety interventions but also a formal, state-based quantification of the tolerable edge response time before vehicle safety is compromised. Using EnergyShield, an ADS can then save energy by wirelessly offloading NN computations to edge computers, while still maintaining a formal guarantee of safety until it receives a response (on-vehicle hardware provides a just-in-time fail safe). To validate the benefits of EnergyShield, we implemented and tested it in the Carla simulation environment. Our results show that EnergyShield maintains safe vehicle operation while providing significant energy savings compared to on-vehicle NN evaluation: from 24% to 54% less energy across a range of wireless conditions and edge delays.
HADAS: Hardware-Aware Dynamic Neural Architecture Search for Edge Performance Scaling
Dec 06, 2022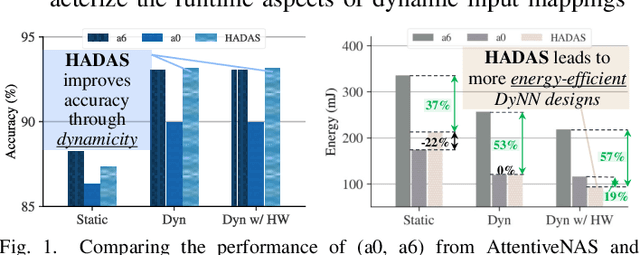
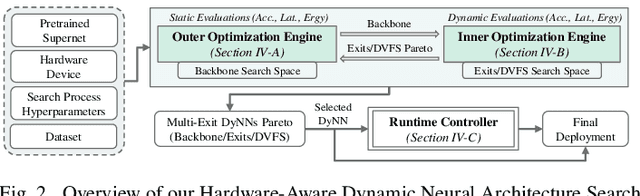
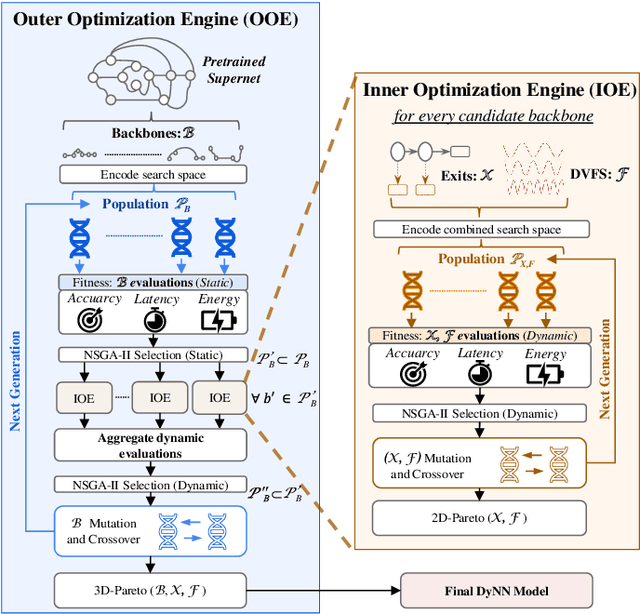
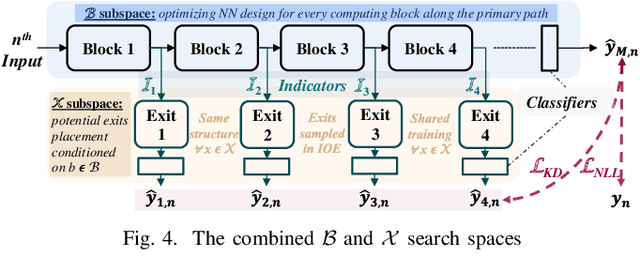
Dynamic neural networks (DyNNs) have become viable techniques to enable intelligence on resource-constrained edge devices while maintaining computational efficiency. In many cases, the implementation of DyNNs can be sub-optimal due to its underlying backbone architecture being developed at the design stage independent of both: (i) the dynamic computing features, e.g. early exiting, and (ii) the resource efficiency features of the underlying hardware, e.g., dynamic voltage and frequency scaling (DVFS). Addressing this, we present HADAS, a novel Hardware-Aware Dynamic Neural Architecture Search framework that realizes DyNN architectures whose backbone, early exiting features, and DVFS settings have been jointly optimized to maximize performance and resource efficiency. Our experiments using the CIFAR-100 dataset and a diverse set of edge computing platforms have seen HADAS dynamic models achieve up to 57% energy efficiency gains compared to the conventional dynamic ones while maintaining the desired level of accuracy scores. Our code is available at https://github.com/HalimaBouzidi/HADAS
Romanus: Robust Task Offloading in Modular Multi-Sensor Autonomous Driving Systems
Jul 18, 2022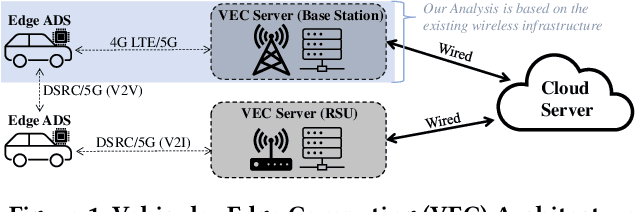
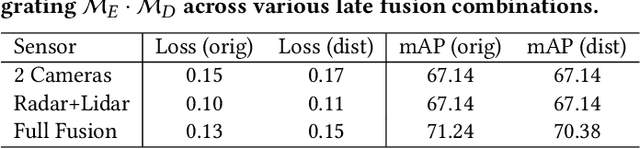

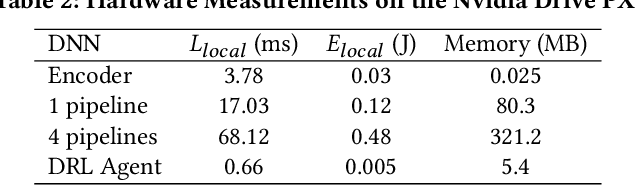
Due to the high performance and safety requirements of self-driving applications, the complexity of modern autonomous driving systems (ADS) has been growing, instigating the need for more sophisticated hardware which could add to the energy footprint of the ADS platform. Addressing this, edge computing is poised to encompass self-driving applications, enabling the compute-intensive autonomy-related tasks to be offloaded for processing at compute-capable edge servers. Nonetheless, the intricate hardware architecture of ADS platforms, in addition to the stringent robustness demands, set forth complications for task offloading which are unique to autonomous driving. Hence, we present $ROMANUS$, a methodology for robust and efficient task offloading for modular ADS platforms with multi-sensor processing pipelines. Our methodology entails two phases: (i) the introduction of efficient offloading points along the execution path of the involved deep learning models, and (ii) the implementation of a runtime solution based on Deep Reinforcement Learning to adapt the operating mode according to variations in the perceived road scene complexity, network connectivity, and server load. Experiments on the object detection use case demonstrated that our approach is 14.99% more energy-efficient than pure local execution while achieving a 77.06% reduction in risky behavior from a robust-agnostic offloading baseline.
SAGE: A Split-Architecture Methodology for Efficient End-to-End Autonomous Vehicle Control
Jul 22, 2021
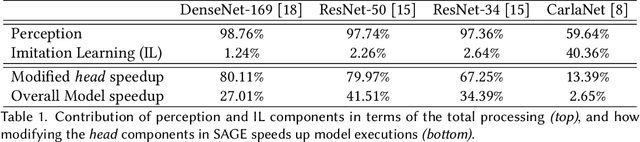
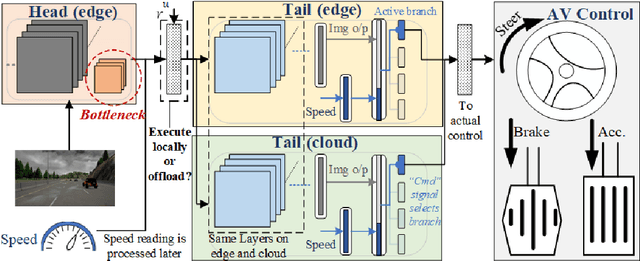
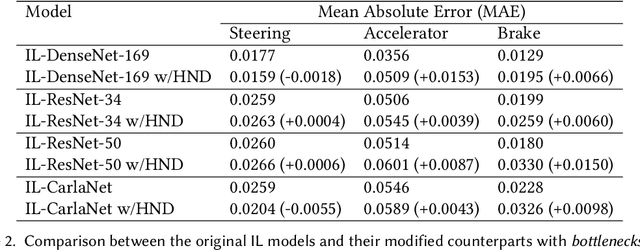
Autonomous vehicles (AV) are expected to revolutionize transportation and improve road safety significantly. However, these benefits do not come without cost; AVs require large Deep-Learning (DL) models and powerful hardware platforms to operate reliably in real-time, requiring between several hundred watts to one kilowatt of power. This power consumption can dramatically reduce vehicles' driving range and affect emissions. To address this problem, we propose SAGE: a methodology for selectively offloading the key energy-consuming modules of DL architectures to the cloud to optimize edge energy usage while meeting real-time latency constraints. Furthermore, we leverage Head Network Distillation (HND) to introduce efficient bottlenecks within the DL architecture in order to minimize the network overhead costs of offloading with almost no degradation in the model's performance. We evaluate SAGE using an Nvidia Jetson TX2 and an industry-standard Nvidia Drive PX2 as the AV edge devices and demonstrate that our offloading strategy is practical for a wide range of DL models and internet connection bandwidths on 3G, 4G LTE, and WiFi technologies. Compared to edge-only computation, SAGE reduces energy consumption by an average of 36.13%, 47.07%, and 55.66% for an AV with one low-resolution camera, one high-resolution camera, and three high-resolution cameras, respectively. SAGE also reduces upload data size by up to 98.40% compared to direct camera offloading.