 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut of Sight, Out of Track: Adversarial Attacks on Propagation-based Multi-Object Trackers via Query State Manipulation
Apr 01, 2026Recent Tracking-by-Query-Propagation (TBP) methods have advanced Multi-Object Tracking (MOT) by enabling end-to-end (E2E) pipelines with long-range temporal modeling. However, this reliance on query propagation introduces unexplored architectural vulnerabilities to adversarial attacks. We present FADE, a novel attack framework designed to exploit these specific vulnerabilities. FADE employs two attack strategies targeting core TBP mechanisms: (i) Temporal Query Flooding: Generates spurious temporally consistent track queries to exhaust the tracker's limited query budget, forcing it to terminate valid tracks. (ii) Temporal Memory Corruption: Directly attacks the query updater's memory by severing temporal links via state de-correlation and erasing the learned feature identity of matched tracks. Furthermore, we introduce a differentiable pipeline to optimize these attacks for physical-world realizability by leveraging simulations of advanced perception sensor spoofing. Experiments on MOT17 and MOT20 benchmarks demonstrate that FADE is highly effective against state-of-the-art TBP trackers, causing significant identity switches and track terminations.
HELIOS: Hierarchical Graph Abstraction for Structure-Aware LLM Decompilation
Jan 21, 2026Large language models (LLMs) have recently been applied to binary decompilation, yet they still treat code as plain text and ignore the graphs that govern program control flow. This limitation often yields syntactically fragile and logically inconsistent output, especially for optimized binaries. This paper presents \textsc{HELIOS}, a framework that reframes LLM-based decompilation as a structured reasoning task. \textsc{HELIOS} summarizes a binary's control flow and function calls into a hierarchical text representation that spells out basic blocks, their successors, and high-level patterns such as loops and conditionals. This representation is supplied to a general-purpose LLM, along with raw decompiler output, optionally combined with a compiler-in-the-loop that returns error messages when the generated code fails to build. On HumanEval-Decompile for \texttt{x86\_64}, \textsc{HELIOS} raises average object file compilability from 45.0\% to 85.2\% for Gemini~2.0 and from 71.4\% to 89.6\% for GPT-4.1~Mini. With compiler feedback, compilability exceeds 94\% and functional correctness improves by up to 5.6 percentage points over text-only prompting. Across six architectures drawn from x86, ARM, and MIPS, \textsc{HELIOS} reduces the spread in functional correctness while keeping syntactic correctness consistently high, all without fine-tuning. These properties make \textsc{HELIOS} a practical building block for reverse engineering workflows in security settings where analysts need recompilable, semantically faithful code across diverse hardware targets.
Hyperdimensional Uncertainty Quantification for Multimodal Uncertainty Fusion in Autonomous Vehicles Perception
Mar 25, 2025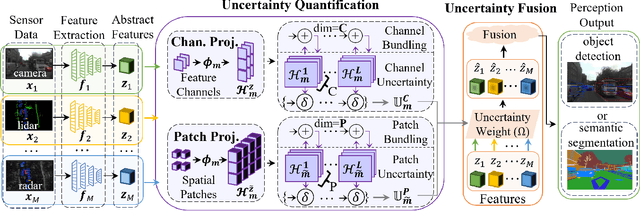
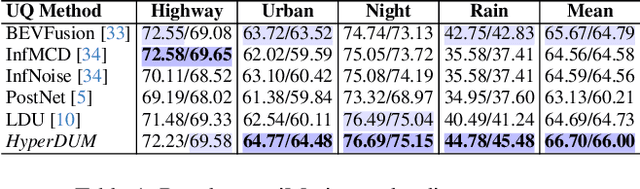
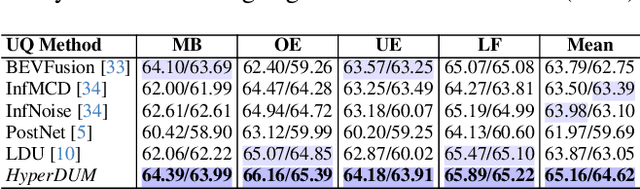

Uncertainty Quantification (UQ) is crucial for ensuring the reliability of machine learning models deployed in real-world autonomous systems. However, existing approaches typically quantify task-level output prediction uncertainty without considering epistemic uncertainty at the multimodal feature fusion level, leading to sub-optimal outcomes. Additionally, popular uncertainty quantification methods, e.g., Bayesian approximations, remain challenging to deploy in practice due to high computational costs in training and inference. In this paper, we propose HyperDUM, a novel deterministic uncertainty method (DUM) that efficiently quantifies feature-level epistemic uncertainty by leveraging hyperdimensional computing. Our method captures the channel and spatial uncertainties through channel and patch -wise projection and bundling techniques respectively. Multimodal sensor features are then adaptively weighted to mitigate uncertainty propagation and improve feature fusion. Our evaluations show that HyperDUM on average outperforms the state-of-the-art (SOTA) algorithms by up to 2.01%/1.27% in 3D Object Detection and up to 1.29% improvement over baselines in semantic segmentation tasks under various types of uncertainties. Notably, HyperDUM requires 2.36x less Floating Point Operations and up to 38.30x less parameters than SOTA methods, providing an efficient solution for real-world autonomous systems.
Bridging the PLC Binary Analysis Gap: A Cross-Compiler Dataset and Neural Framework for Industrial Control Systems
Feb 27, 2025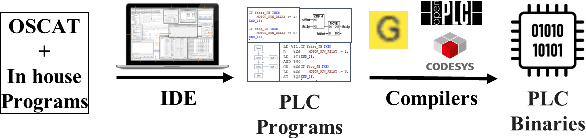
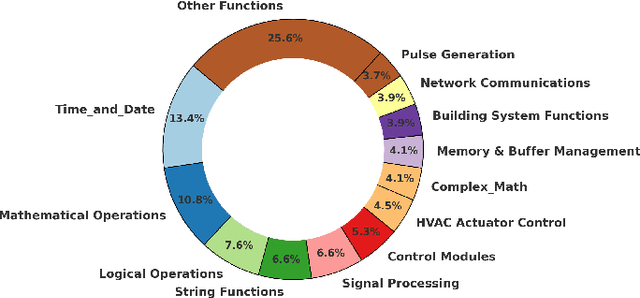
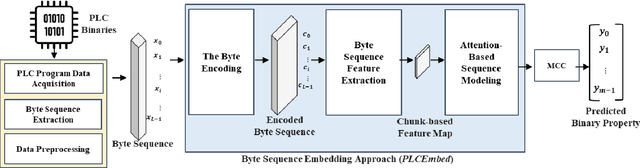
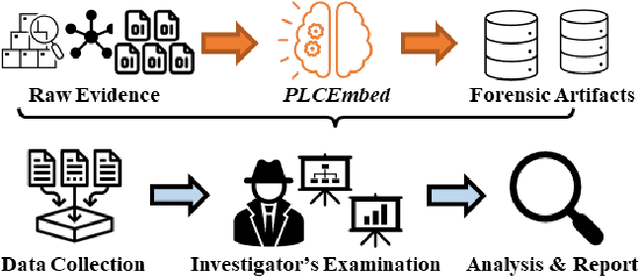
Industrial Control Systems (ICS) rely heavily on Programmable Logic Controllers (PLCs) to manage critical infrastructure, yet analyzing PLC executables remains challenging due to diverse proprietary compilers and limited access to source code. To bridge this gap, we introduce PLC-BEAD, a comprehensive dataset containing 2431 compiled binaries from 700+ PLC programs across four major industrial compilers (CoDeSys, GEB, OpenPLC-V2, OpenPLC-V3). This novel dataset uniquely pairs each binary with its original Structured Text source code and standardized functionality labels, enabling both binary-level and source-level analysis. We demonstrate the dataset's utility through PLCEmbed, a transformer-based framework for binary code analysis that achieves 93\% accuracy in compiler provenance identification and 42\% accuracy in fine-grained functionality classification across 22 industrial control categories. Through comprehensive ablation studies, we analyze how compiler optimization levels, code patterns, and class distributions influence model performance. We provide detailed documentation of the dataset creation process, labeling taxonomy, and benchmark protocols to ensure reproducibility. Both PLC-BEAD and PLCEmbed are released as open-source resources to foster research in PLC security, reverse engineering, and ICS forensics, establishing new baselines for data-driven approaches to industrial cybersecurity.
Transformer-Based Contrastive Meta-Learning For Low-Resource Generalizable Activity Recognition
Dec 28, 2024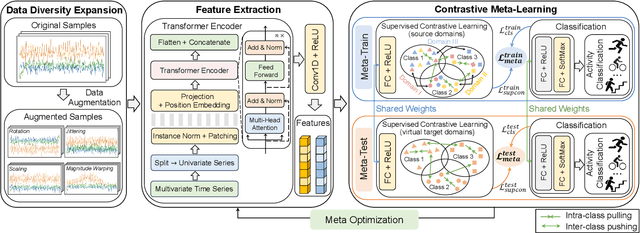
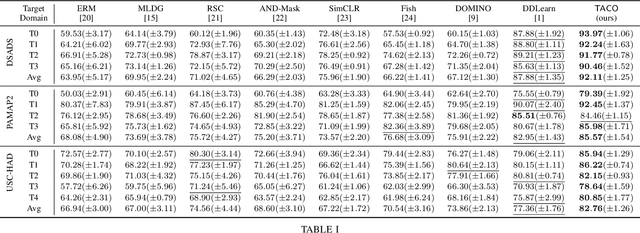
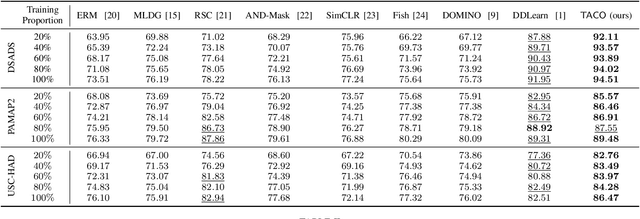
Deep learning has been widely adopted for human activity recognition (HAR) while generalizing a trained model across diverse users and scenarios remains challenging due to distribution shifts. The inherent low-resource challenge in HAR, i.e., collecting and labeling adequate human-involved data can be prohibitively costly, further raising the difficulty of tackling DS. We propose TACO, a novel transformer-based contrastive meta-learning approach for generalizable HAR. TACO addresses DS by synthesizing virtual target domains in training with explicit consideration of model generalizability. Additionally, we extract expressive feature with the attention mechanism of Transformer and incorporate the supervised contrastive loss function within our meta-optimization to enhance representation learning. Our evaluation demonstrates that TACO achieves notably better performance across various low-resource DS scenarios.
Performance Implications of Multi-Chiplet Neural Processing Units on Autonomous Driving Perception
Nov 24, 2024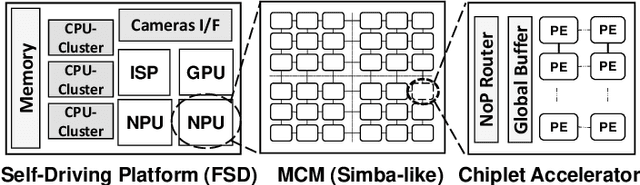
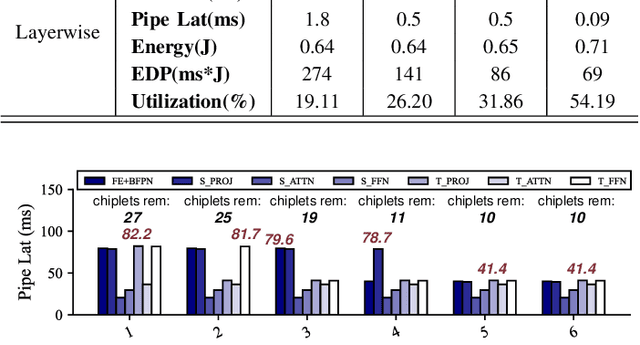
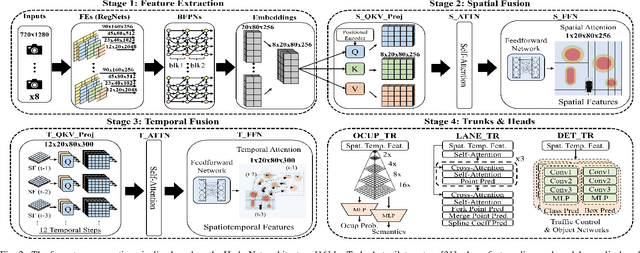
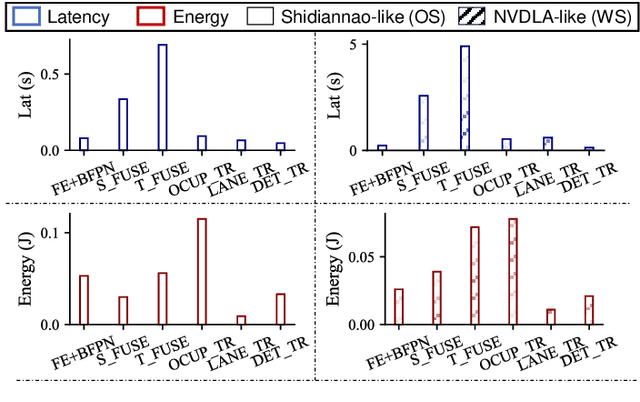
We study the application of emerging chiplet-based Neural Processing Units to accelerate vehicular AI perception workloads in constrained automotive settings. The motivation stems from how chiplets technology is becoming integral to emerging vehicular architectures, providing a cost-effective trade-off between performance, modularity, and customization; and from perception models being the most computationally demanding workloads in a autonomous driving system. Using the Tesla Autopilot perception pipeline as a case study, we first breakdown its constituent models and profile their performance on different chiplet accelerators. From the insights, we propose a novel scheduling strategy to efficiently deploy perception workloads on multi-chip AI accelerators. Our experiments using a standard DNN performance simulator, MAESTRO, show our approach realizes 82% and 2.8x increase in throughput and processing engines utilization compared to monolithic accelerator designs.
SCAR: Scheduling Multi-Model AI Workloads on Heterogeneous Multi-Chiplet Module Accelerators
May 01, 2024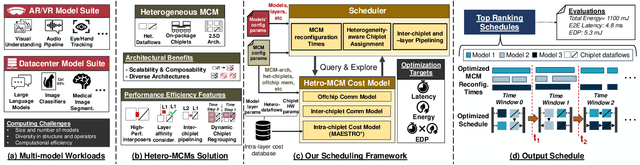
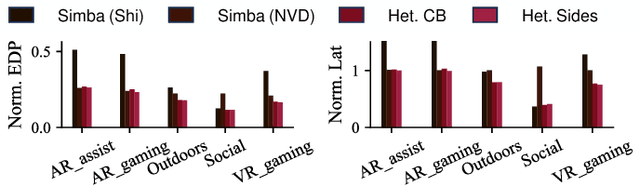

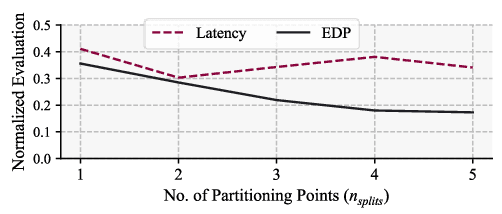
Emerging multi-model workloads with heavy models like recent large language models significantly increased the compute and memory demands on hardware. To address such increasing demands, designing a scalable hardware architecture became a key problem. Among recent solutions, the 2.5D silicon interposer multi-chip module (MCM)-based AI accelerator has been actively explored as a promising scalable solution due to their significant benefits in the low engineering cost and composability. However, previous MCM accelerators are based on homogeneous architectures with fixed dataflow, which encounter major challenges from highly heterogeneous multi-model workloads due to their limited workload adaptivity. Therefore, in this work, we explore the opportunity in the heterogeneous dataflow MCM AI accelerators. We identify the scheduling of multi-model workload on heterogeneous dataflow MCM AI accelerator is an important and challenging problem due to its significance and scale, which reaches O(10^18) scale even for a single model case on 6x6 chiplets. We develop a set of heuristics to navigate the huge scheduling space and codify them into a scheduler with advanced techniques such as inter-chiplet pipelining. Our evaluation on ten multi-model workload scenarios for datacenter multitenancy and AR/VR use-cases has shown the efficacy of our approach, achieving on average 35.3% and 31.4% less energy-delay product (EDP) for the respective applications settings compared to homogeneous baselines.
SMORE: Similarity-based Hyperdimensional Domain Adaptation for Multi-Sensor Time Series Classification
Feb 27, 2024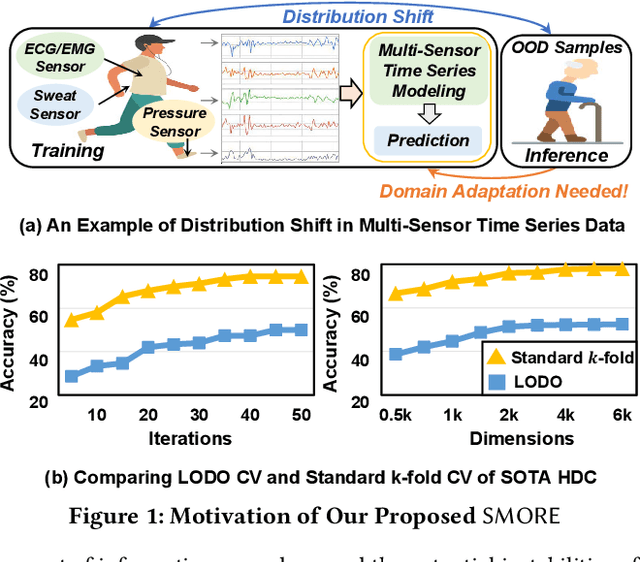
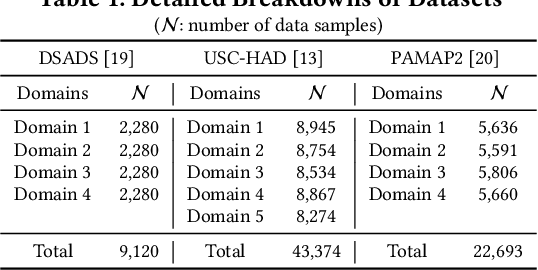
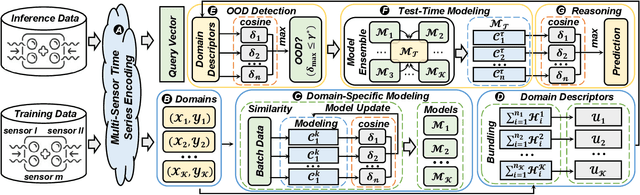
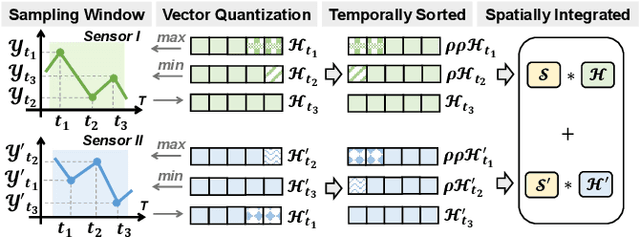
Many real-world applications of the Internet of Things (IoT) employ machine learning (ML) algorithms to analyze time series information collected by interconnected sensors. However, distribution shift, a fundamental challenge in data-driven ML, arises when a model is deployed on a data distribution different from the training data and can substantially degrade model performance. Additionally, increasingly sophisticated deep neural networks (DNNs) are required to capture intricate spatial and temporal dependencies in multi-sensor time series data, often exceeding the capabilities of today's edge devices. In this paper, we propose SMORE, a novel resource-efficient domain adaptation (DA) algorithm for multi-sensor time series classification, leveraging the efficient and parallel operations of hyperdimensional computing. SMORE dynamically customizes test-time models with explicit consideration of the domain context of each sample to mitigate the negative impacts of domain shifts. Our evaluation on a variety of multi-sensor time series classification tasks shows that SMORE achieves on average 1.98% higher accuracy than state-of-the-art (SOTA) DNN-based DA algorithms with 18.81x faster training and 4.63x faster inference.
Distributed Radiance Fields for Edge Video Compression and Metaverse Integration in Autonomous Driving
Feb 22, 2024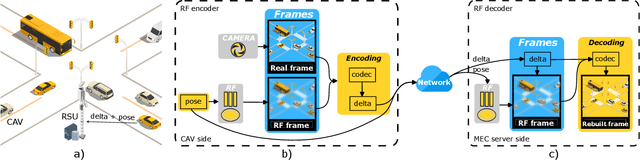

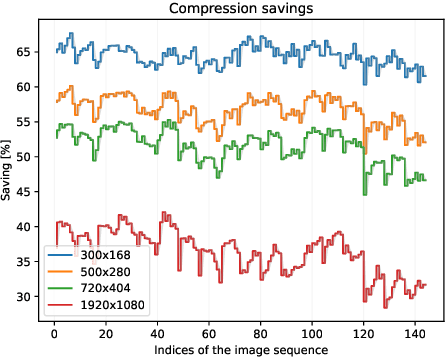
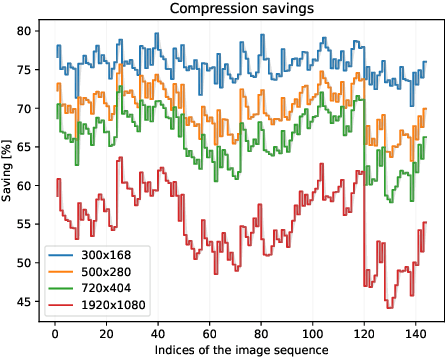
The metaverse is a virtual space that combines physical and digital elements, creating immersive and connected digital worlds. For autonomous mobility, it enables new possibilities with edge computing and digital twins (DTs) that offer virtual prototyping, prediction, and more. DTs can be created with 3D scene reconstruction methods that capture the real world's geometry, appearance, and dynamics. However, sending data for real-time DT updates in the metaverse, such as camera images and videos from connected autonomous vehicles (CAVs) to edge servers, can increase network congestion, costs, and latency, affecting metaverse services. Herein, a new method is proposed based on distributed radiance fields (RFs), multi-access edge computing (MEC) network for video compression and metaverse DT updates. RF-based encoder and decoder are used to create and restore representations of camera images. The method is evaluated on a dataset of camera images from the CARLA simulator. Data savings of up to 80% were achieved for H.264 I-frame - P-frame pairs by using RFs instead of I-frames, while maintaining high peak signal-to-noise ratio (PSNR) and structural similarity index measure (SSIM) qualitative metrics for the reconstructed images. Possible uses and challenges for the metaverse and autonomous mobility are also discussed.
LLM4PLC: Harnessing Large Language Models for Verifiable Programming of PLCs in Industrial Control Systems
Jan 08, 2024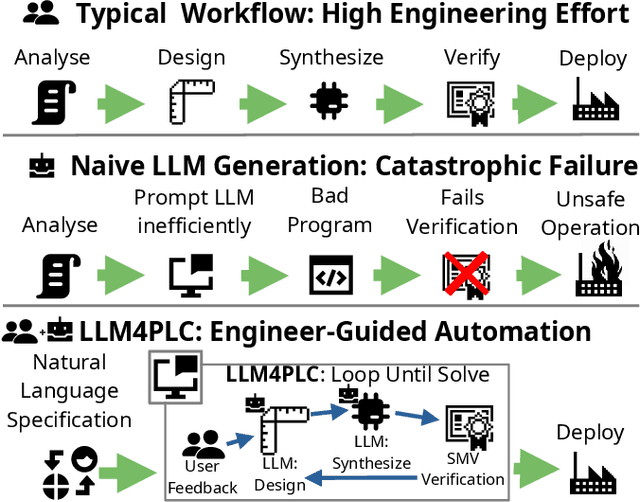
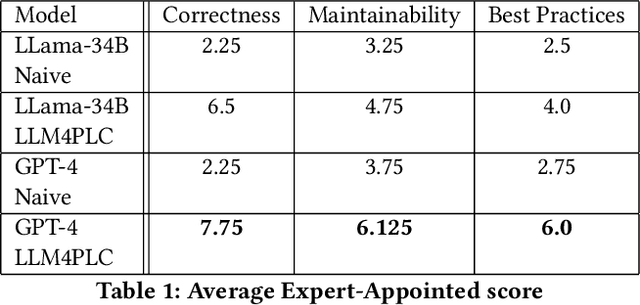
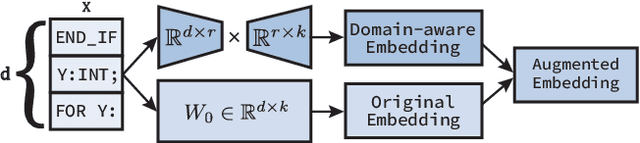
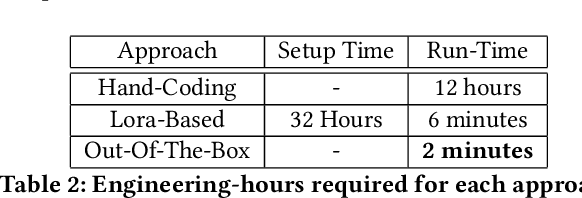
Although Large Language Models (LLMs) have established pre-dominance in automated code generation, they are not devoid of shortcomings. The pertinent issues primarily relate to the absence of execution guarantees for generated code, a lack of explainability, and suboptimal support for essential but niche programming languages. State-of-the-art LLMs such as GPT-4 and LLaMa2 fail to produce valid programs for Industrial Control Systems (ICS) operated by Programmable Logic Controllers (PLCs). We propose LLM4PLC, a user-guided iterative pipeline leveraging user feedback and external verification tools including grammar checkers, compilers and SMV verifiers to guide the LLM's generation. We further enhance the generation potential of LLM by employing Prompt Engineering and model fine-tuning through the creation and usage of LoRAs. We validate this system using a FischerTechnik Manufacturing TestBed (MFTB), illustrating how LLMs can evolve from generating structurally flawed code to producing verifiably correct programs for industrial applications. We run a complete test suite on GPT-3.5, GPT-4, Code Llama-7B, a fine-tuned Code Llama-7B model, Code Llama-34B, and a fine-tuned Code Llama-34B model. The proposed pipeline improved the generation success rate from 47% to 72%, and the Survey-of-Experts code quality from 2.25/10 to 7.75/10. To promote open research, we share the complete experimental setup, the LLM Fine-Tuning Weights, and the video demonstrations of the different programs on our dedicated webpage.