 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM4PLC: Harnessing Large Language Models for Verifiable Programming of PLCs in Industrial Control Systems
Jan 08, 2024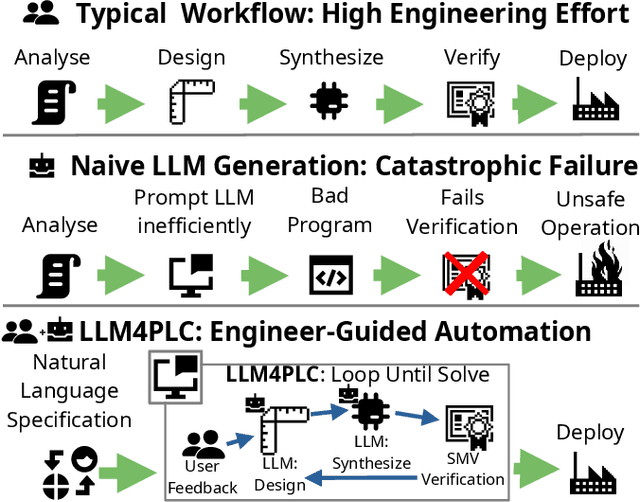
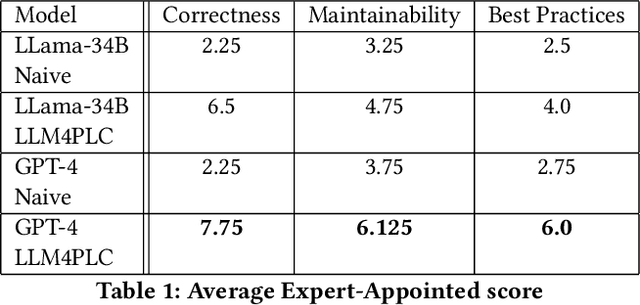
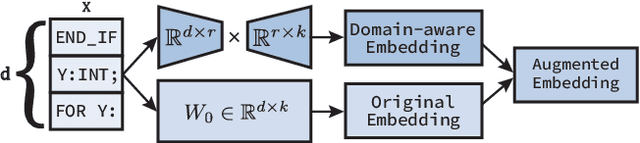
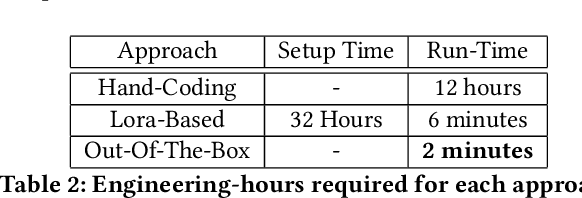
Although Large Language Models (LLMs) have established pre-dominance in automated code generation, they are not devoid of shortcomings. The pertinent issues primarily relate to the absence of execution guarantees for generated code, a lack of explainability, and suboptimal support for essential but niche programming languages. State-of-the-art LLMs such as GPT-4 and LLaMa2 fail to produce valid programs for Industrial Control Systems (ICS) operated by Programmable Logic Controllers (PLCs). We propose LLM4PLC, a user-guided iterative pipeline leveraging user feedback and external verification tools including grammar checkers, compilers and SMV verifiers to guide the LLM's generation. We further enhance the generation potential of LLM by employing Prompt Engineering and model fine-tuning through the creation and usage of LoRAs. We validate this system using a FischerTechnik Manufacturing TestBed (MFTB), illustrating how LLMs can evolve from generating structurally flawed code to producing verifiably correct programs for industrial applications. We run a complete test suite on GPT-3.5, GPT-4, Code Llama-7B, a fine-tuned Code Llama-7B model, Code Llama-34B, and a fine-tuned Code Llama-34B model. The proposed pipeline improved the generation success rate from 47% to 72%, and the Survey-of-Experts code quality from 2.25/10 to 7.75/10. To promote open research, we share the complete experimental setup, the LLM Fine-Tuning Weights, and the video demonstrations of the different programs on our dedicated webpage.
Comparative Analysis of CHATGPT and the evolution of language models
Mar 28, 2023



Interest in Large Language Models (LLMs) has increased drastically since the emergence of ChatGPT and the outstanding positive societal response to the ease with which it performs tasks in Natural Language Processing (NLP). The triumph of ChatGPT, however, is how it seamlessly bridges the divide between language generation and knowledge models. In some cases, it provides anecdotal evidence of a framework for replicating human intuition over a knowledge domain. This paper highlights the prevailing ideas in NLP, including machine translation, machine summarization, question-answering, and language generation, and compares the performance of ChatGPT with the major algorithms in each of these categories using the Spontaneous Quality (SQ) score. A strategy for validating the arguments and results of ChatGPT is presented summarily as an example of safe, large-scale adoption of LLMs.