 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperdimensional Uncertainty Quantification for Multimodal Uncertainty Fusion in Autonomous Vehicles Perception
Mar 25, 2025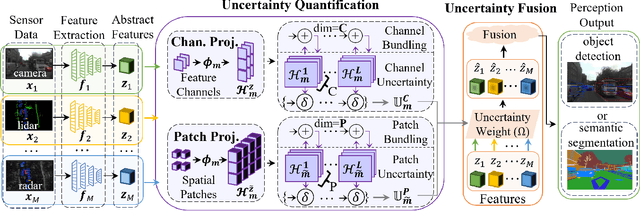
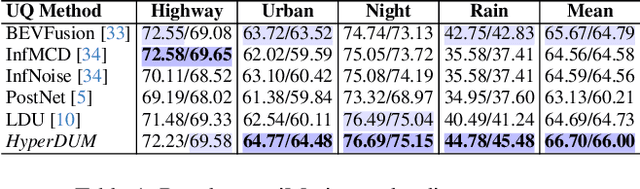
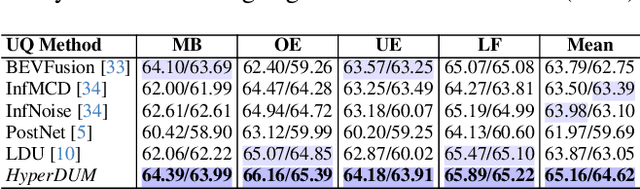

Uncertainty Quantification (UQ) is crucial for ensuring the reliability of machine learning models deployed in real-world autonomous systems. However, existing approaches typically quantify task-level output prediction uncertainty without considering epistemic uncertainty at the multimodal feature fusion level, leading to sub-optimal outcomes. Additionally, popular uncertainty quantification methods, e.g., Bayesian approximations, remain challenging to deploy in practice due to high computational costs in training and inference. In this paper, we propose HyperDUM, a novel deterministic uncertainty method (DUM) that efficiently quantifies feature-level epistemic uncertainty by leveraging hyperdimensional computing. Our method captures the channel and spatial uncertainties through channel and patch -wise projection and bundling techniques respectively. Multimodal sensor features are then adaptively weighted to mitigate uncertainty propagation and improve feature fusion. Our evaluations show that HyperDUM on average outperforms the state-of-the-art (SOTA) algorithms by up to 2.01%/1.27% in 3D Object Detection and up to 1.29% improvement over baselines in semantic segmentation tasks under various types of uncertainties. Notably, HyperDUM requires 2.36x less Floating Point Operations and up to 38.30x less parameters than SOTA methods, providing an efficient solution for real-world autonomous systems.
Performance Implications of Multi-Chiplet Neural Processing Units on Autonomous Driving Perception
Nov 24, 2024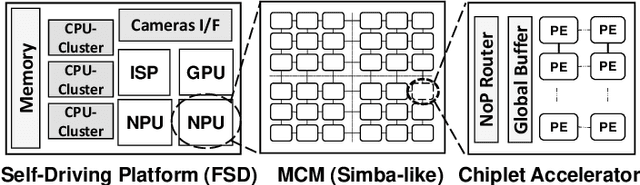
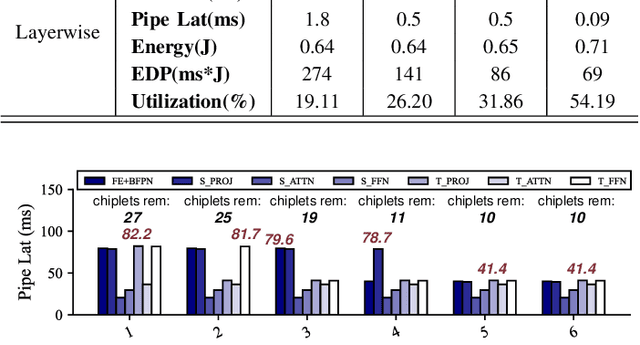
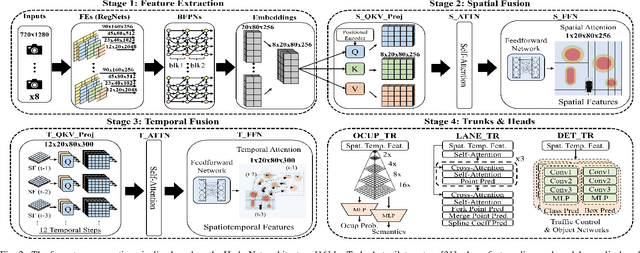
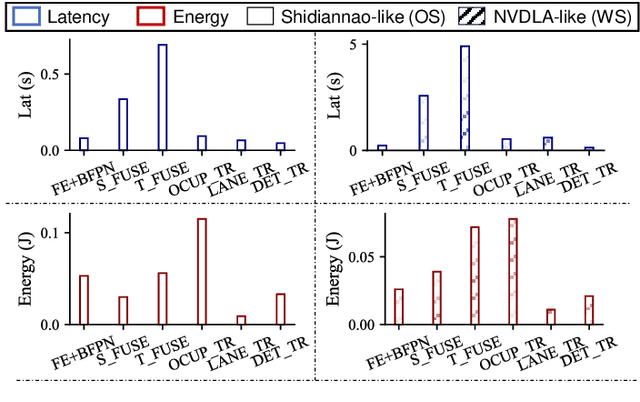
We study the application of emerging chiplet-based Neural Processing Units to accelerate vehicular AI perception workloads in constrained automotive settings. The motivation stems from how chiplets technology is becoming integral to emerging vehicular architectures, providing a cost-effective trade-off between performance, modularity, and customization; and from perception models being the most computationally demanding workloads in a autonomous driving system. Using the Tesla Autopilot perception pipeline as a case study, we first breakdown its constituent models and profile their performance on different chiplet accelerators. From the insights, we propose a novel scheduling strategy to efficiently deploy perception workloads on multi-chip AI accelerators. Our experiments using a standard DNN performance simulator, MAESTRO, show our approach realizes 82% and 2.8x increase in throughput and processing engines utilization compared to monolithic accelerator designs.
SCAR: Scheduling Multi-Model AI Workloads on Heterogeneous Multi-Chiplet Module Accelerators
May 01, 2024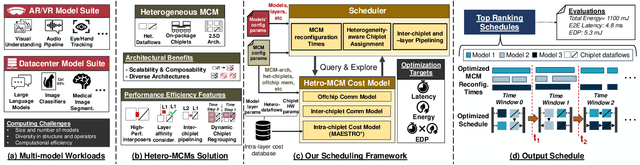
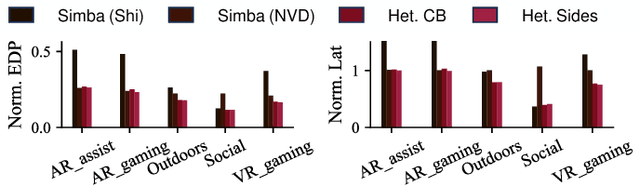

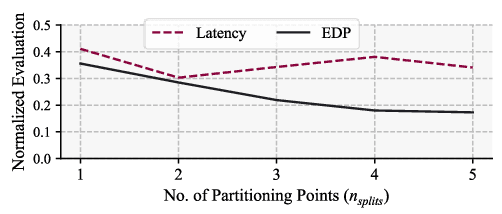
Emerging multi-model workloads with heavy models like recent large language models significantly increased the compute and memory demands on hardware. To address such increasing demands, designing a scalable hardware architecture became a key problem. Among recent solutions, the 2.5D silicon interposer multi-chip module (MCM)-based AI accelerator has been actively explored as a promising scalable solution due to their significant benefits in the low engineering cost and composability. However, previous MCM accelerators are based on homogeneous architectures with fixed dataflow, which encounter major challenges from highly heterogeneous multi-model workloads due to their limited workload adaptivity. Therefore, in this work, we explore the opportunity in the heterogeneous dataflow MCM AI accelerators. We identify the scheduling of multi-model workload on heterogeneous dataflow MCM AI accelerator is an important and challenging problem due to its significance and scale, which reaches O(10^18) scale even for a single model case on 6x6 chiplets. We develop a set of heuristics to navigate the huge scheduling space and codify them into a scheduler with advanced techniques such as inter-chiplet pipelining. Our evaluation on ten multi-model workload scenarios for datacenter multitenancy and AR/VR use-cases has shown the efficacy of our approach, achieving on average 35.3% and 31.4% less energy-delay product (EDP) for the respective applications settings compared to homogeneous baselines.
DOMINO: Domain-invariant Hyperdimensional Classification for Multi-Sensor Time Series Data
Aug 18, 2023


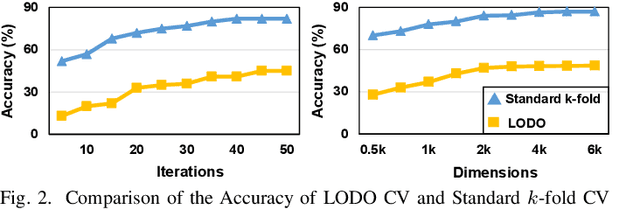
With the rapid evolution of the Internet of Things, many real-world applications utilize heterogeneously connected sensors to capture time-series information. Edge-based machine learning (ML) methodologies are often employed to analyze locally collected data. However, a fundamental issue across data-driven ML approaches is distribution shift. It occurs when a model is deployed on a data distribution different from what it was trained on, and can substantially degrade model performance. Additionally, increasingly sophisticated deep neural networks (DNNs) have been proposed to capture spatial and temporal dependencies in multi-sensor time series data, requiring intensive computational resources beyond the capacity of today's edge devices. While brain-inspired hyperdimensional computing (HDC) has been introduced as a lightweight solution for edge-based learning, existing HDCs are also vulnerable to the distribution shift challenge. In this paper, we propose DOMINO, a novel HDC learning framework addressing the distribution shift problem in noisy multi-sensor time-series data. DOMINO leverages efficient and parallel matrix operations on high-dimensional space to dynamically identify and filter out domain-variant dimensions. Our evaluation on a wide range of multi-sensor time series classification tasks shows that DOMINO achieves on average 2.04% higher accuracy than state-of-the-art (SOTA) DNN-based domain generalization techniques, and delivers 16.34x faster training and 2.89x faster inference. More importantly, DOMINO performs notably better when learning from partially labeled and highly imbalanced data, providing 10.93x higher robustness against hardware noises than SOTA DNNs.
Romanus: Robust Task Offloading in Modular Multi-Sensor Autonomous Driving Systems
Jul 18, 2022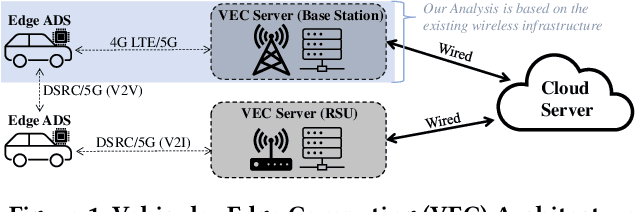
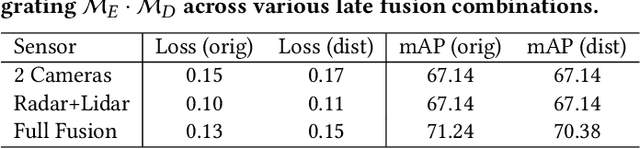

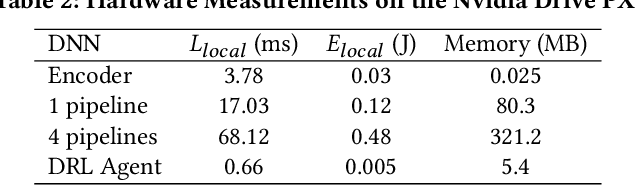
Due to the high performance and safety requirements of self-driving applications, the complexity of modern autonomous driving systems (ADS) has been growing, instigating the need for more sophisticated hardware which could add to the energy footprint of the ADS platform. Addressing this, edge computing is poised to encompass self-driving applications, enabling the compute-intensive autonomy-related tasks to be offloaded for processing at compute-capable edge servers. Nonetheless, the intricate hardware architecture of ADS platforms, in addition to the stringent robustness demands, set forth complications for task offloading which are unique to autonomous driving. Hence, we present $ROMANUS$, a methodology for robust and efficient task offloading for modular ADS platforms with multi-sensor processing pipelines. Our methodology entails two phases: (i) the introduction of efficient offloading points along the execution path of the involved deep learning models, and (ii) the implementation of a runtime solution based on Deep Reinforcement Learning to adapt the operating mode according to variations in the perceived road scene complexity, network connectivity, and server load. Experiments on the object detection use case demonstrated that our approach is 14.99% more energy-efficient than pure local execution while achieving a 77.06% reduction in risky behavior from a robust-agnostic offloading baseline.
Neural Contextual Bandits Based Dynamic Sensor Selection for Low-Power Body-Area Networks
May 24, 2022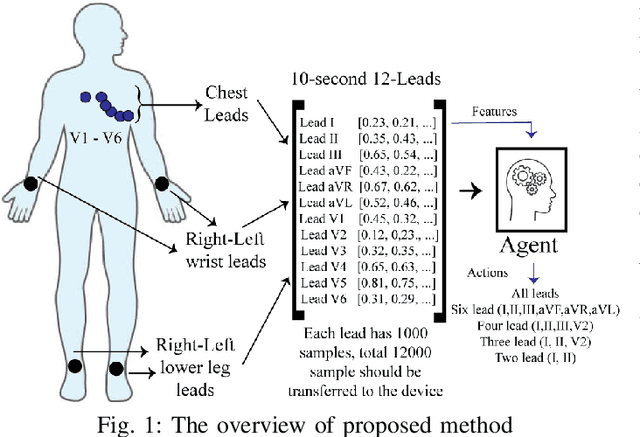
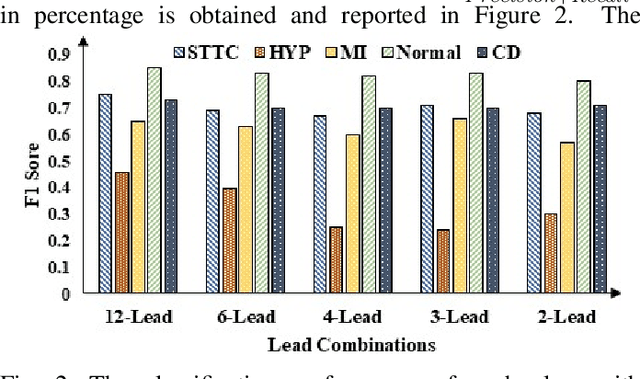
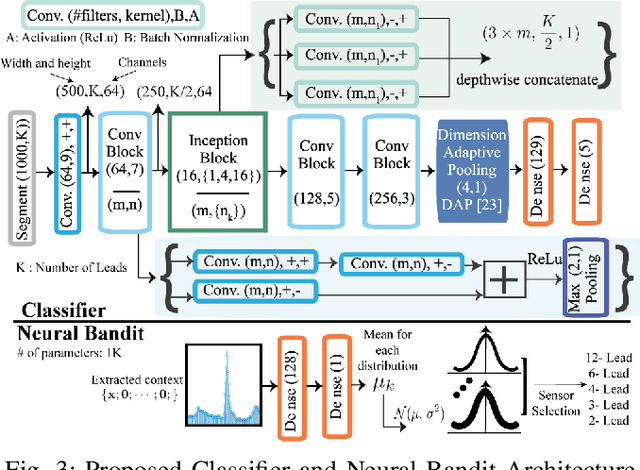
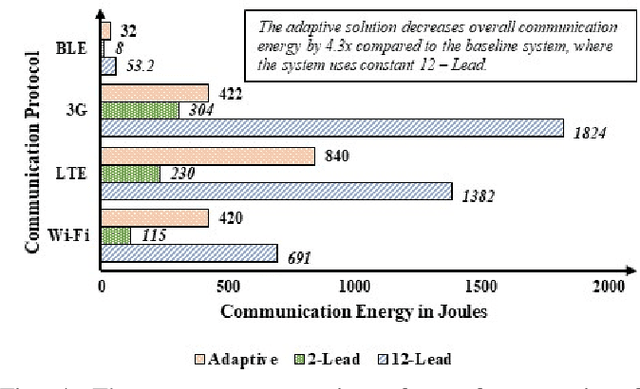
Providing health monitoring devices with machine intelligence is important for enabling automatic mobile healthcare applications. However, this brings additional challenges due to the resource scarcity of these devices. This work introduces a neural contextual bandits based dynamic sensor selection methodology for high-performance and resource-efficient body-area networks to realize next generation mobile health monitoring devices. The methodology utilizes contextual bandits to select the most informative sensor combinations during runtime and ignore redundant data for decreasing transmission and computing power in a body area network (BAN). The proposed method has been validated using one of the most common health monitoring applications: cardiac activity monitoring. Solutions from our proposed method are compared against those from related works in terms of classification performance and energy while considering the communication energy consumption. Our final solutions could reach $78.8\%$ AU-PRC on the PTB-XL ECG dataset for cardiac abnormality detection while decreasing the overall energy consumption and computational energy by $3.7 \times$ and $4.3 \times$, respectively.
Feature Augmented Hybrid CNN for Stress Recognition Using Wrist-based Photoplethysmography Sensor
Aug 02, 2021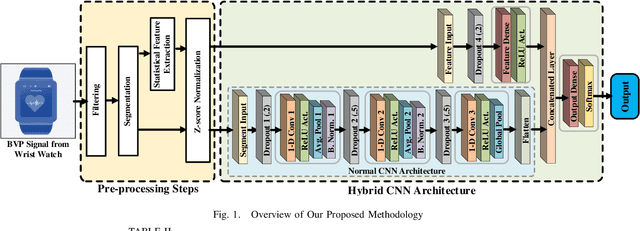
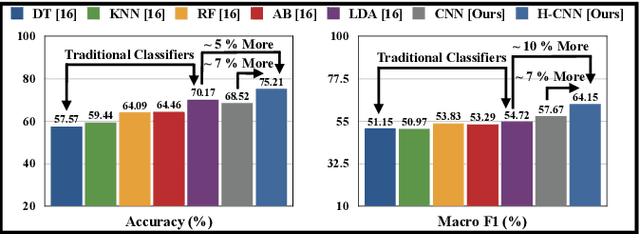
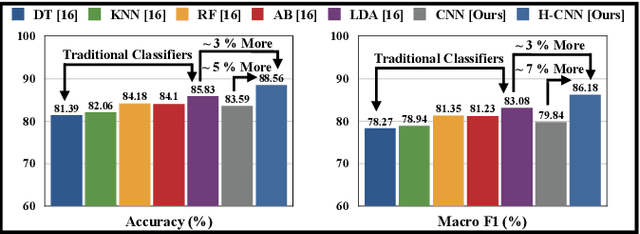
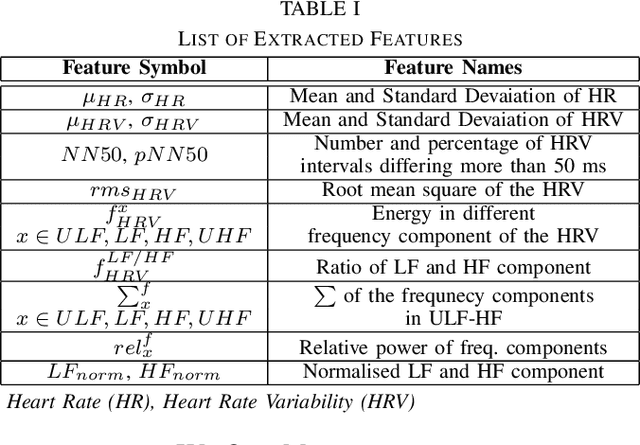
Stress is a physiological state that hampers mental health and has serious consequences to physical health. Moreover, the COVID-19 pandemic has increased stress levels among people across the globe. Therefore, continuous monitoring and detection of stress are necessary. The recent advances in wearable devices have allowed the monitoring of several physiological signals related to stress. Among them, wrist-worn wearable devices like smartwatches are most popular due to their convenient usage. And the photoplethysmography (PPG) sensor is the most prevalent sensor in almost all consumer-grade wrist-worn smartwatches. Therefore, this paper focuses on using a wrist-based PPG sensor that collects Blood Volume Pulse (BVP) signals to detect stress which may be applicable for consumer-grade wristwatches. Moreover, state-of-the-art works have used either classical machine learning algorithms to detect stress using hand-crafted features or have used deep learning algorithms like Convolutional Neural Network (CNN) which automatically extracts features. This paper proposes a novel hybrid CNN (H-CNN) classifier that uses both the hand-crafted features and the automatically extracted features by CNN to detect stress using the BVP signal. Evaluation on the benchmark WESAD dataset shows that, for 3-class classification (Baseline vs. Stress vs. Amusement), our proposed H-CNN outperforms traditional classifiers and normal CNN by 5% and 7% accuracy, and 10% and 7% macro F1 score, respectively. Also for 2-class classification (Stress vs. Non-stress), our proposed H-CNN outperforms traditional classifiers and normal CNN by 3% and ~5% accuracy, and ~3% and ~7% macro F1 score, respectively.