 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMap-and-Conquer: Energy-Efficient Mapping of Dynamic Neural Nets onto Heterogeneous MPSoCs
Paper and Code
Feb 24, 2023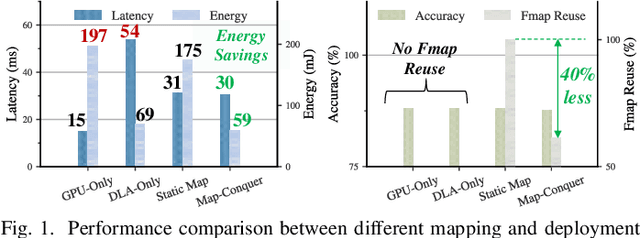
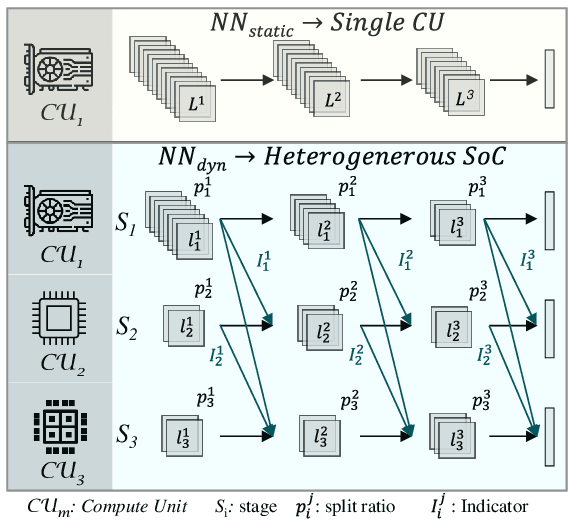

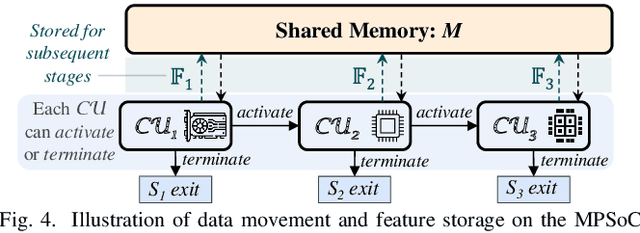
Heterogeneous MPSoCs comprise diverse processing units of varying compute capabilities. To date, the mapping strategies of neural networks (NNs) onto such systems are yet to exploit the full potential of processing parallelism, made possible through both the intrinsic NNs' structure and underlying hardware composition. In this paper, we propose a novel framework to effectively map NNs onto heterogeneous MPSoCs in a manner that enables them to leverage the underlying processing concurrency. Specifically, our approach identifies an optimal partitioning scheme of the NN along its `width' dimension, which facilitates deployment of concurrent NN blocks onto different hardware computing units. Additionally, our approach contributes a novel scheme to deploy partitioned NNs onto the MPSoC as dynamic multi-exit networks for additional performance gains. Our experiments on a standard MPSoC platform have yielded dynamic mapping configurations that are 2.1x more energy-efficient than the GPU-only mapping while incurring 1.7x less latency than DLA-only mapping.