 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCombining Neural Architecture Search and Automatic Code Optimization: A Survey
Aug 07, 2024Deep Learning models have experienced exponential growth in complexity and resource demands in recent years. Accelerating these models for efficient execution on resource-constrained devices has become more crucial than ever. Two notable techniques employed to achieve this goal are Hardware-aware Neural Architecture Search (HW-NAS) and Automatic Code Optimization (ACO). HW-NAS automatically designs accurate yet hardware-friendly neural networks, while ACO involves searching for the best compiler optimizations to apply on neural networks for efficient mapping and inference on the target hardware. This survey explores recent works that combine these two techniques within a single framework. We present the fundamental principles of both domains and demonstrate their sub-optimality when performed independently. We then investigate their integration into a joint optimization process that we call Hardware Aware-Neural Architecture and Compiler Optimizations co-Search (NACOS).
SONATA: Self-adaptive Evolutionary Framework for Hardware-aware Neural Architecture Search
Feb 20, 2024



Recent advancements in Artificial Intelligence (AI), driven by Neural Networks (NN), demand innovative neural architecture designs, particularly within the constrained environments of Internet of Things (IoT) systems, to balance performance and efficiency. HW-aware Neural Architecture Search (HW-aware NAS) emerges as an attractive strategy to automate the design of NN using multi-objective optimization approaches, such as evolutionary algorithms. However, the intricate relationship between NN design parameters and HW-aware NAS optimization objectives remains an underexplored research area, overlooking opportunities to effectively leverage this knowledge to guide the search process accordingly. Furthermore, the large amount of evaluation data produced during the search holds untapped potential for refining the optimization strategy and improving the approximation of the Pareto front. Addressing these issues, we propose SONATA, a self-adaptive evolutionary algorithm for HW-aware NAS. Our method leverages adaptive evolutionary operators guided by the learned importance of NN design parameters. Specifically, through tree-based surrogate models and a Reinforcement Learning agent, we aspire to gather knowledge on 'How' and 'When' to evolve NN architectures. Comprehensive evaluations across various NAS search spaces and hardware devices on the ImageNet-1k dataset have shown the merit of SONATA with up to 0.25% improvement in accuracy and up to 2.42x gains in latency and energy. Our SONATA has seen up to sim$93.6% Pareto dominance over the native NSGA-II, further stipulating the importance of self-adaptive evolution operators in HW-aware NAS.
FLASH-RL: Federated Learning Addressing System and Static Heterogeneity using Reinforcement Learning
Nov 12, 2023



Federated Learning (FL) has emerged as a promising Machine Learning paradigm, enabling multiple users to collaboratively train a shared model while preserving their local data. To minimize computing and communication costs associated with parameter transfer, it is common practice in FL to select a subset of clients in each training round. This selection must consider both system and static heterogeneity. Therefore, we propose FLASH-RL, a framework that utilizes Double Deep QLearning (DDQL) to address both system and static heterogeneity in FL. FLASH-RL introduces a new reputation-based utility function to evaluate client contributions based on their current and past performances. Additionally, an adapted DDQL algorithm is proposed to expedite the learning process. Experimental results on MNIST and CIFAR-10 datasets have shown FLASH-RL's effectiveness in achieving a balanced trade-off between model performance and end-to-end latency against existing solutions. Indeed, FLASH-RL reduces latency by up to 24.83% compared to FedAVG and 24.67% compared to FAVOR. It also reduces the training rounds by up to 60.44% compared to FedAVG and +76% compared to FAVOR. In fall detection using the MobiAct dataset, FLASH-RL outperforms FedAVG by up to 2.82% in model's performance and reduces latency by up to 34.75%. Additionally, FLASH-RL achieves the target performance faster, with up to a 45.32% reduction in training rounds compared to FedAVG.
Harmonic-NAS: Hardware-Aware Multimodal Neural Architecture Search on Resource-constrained Devices
Sep 28, 2023
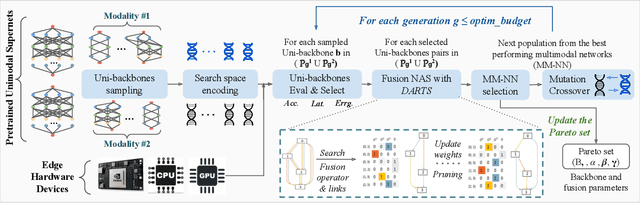
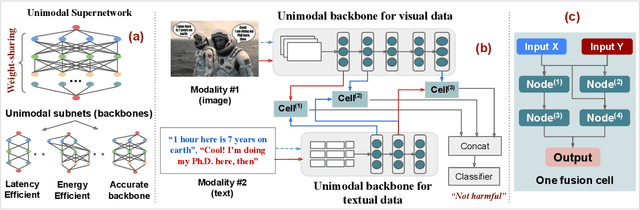

The recent surge of interest surrounding Multimodal Neural Networks (MM-NN) is attributed to their ability to effectively process and integrate multiscale information from diverse data sources. MM-NNs extract and fuse features from multiple modalities using adequate unimodal backbones and specific fusion networks. Although this helps strengthen the multimodal information representation, designing such networks is labor-intensive. It requires tuning the architectural parameters of the unimodal backbones, choosing the fusing point, and selecting the operations for fusion. Furthermore, multimodality AI is emerging as a cutting-edge option in Internet of Things (IoT) systems where inference latency and energy consumption are critical metrics in addition to accuracy. In this paper, we propose Harmonic-NAS, a framework for the joint optimization of unimodal backbones and multimodal fusion networks with hardware awareness on resource-constrained devices. Harmonic-NAS involves a two-tier optimization approach for the unimodal backbone architectures and fusion strategy and operators. By incorporating the hardware dimension into the optimization, evaluation results on various devices and multimodal datasets have demonstrated the superiority of Harmonic-NAS over state-of-the-art approaches achieving up to 10.9% accuracy improvement, 1.91x latency reduction, and 2.14x energy efficiency gain.
Grassroots Operator Search for Model Edge Adaptation
Sep 20, 2023



Hardware-aware Neural Architecture Search (HW-NAS) is increasingly being used to design efficient deep learning architectures. An efficient and flexible search space is crucial to the success of HW-NAS. Current approaches focus on designing a macro-architecture and searching for the architecture's hyperparameters based on a set of possible values. This approach is biased by the expertise of deep learning (DL) engineers and standard modeling approaches. In this paper, we present a Grassroots Operator Search (GOS) methodology. Our HW-NAS adapts a given model for edge devices by searching for efficient operator replacement. We express each operator as a set of mathematical instructions that capture its behavior. The mathematical instructions are then used as the basis for searching and selecting efficient replacement operators that maintain the accuracy of the original model while reducing computational complexity. Our approach is grassroots since it relies on the mathematical foundations to construct new and efficient operators for DL architectures. We demonstrate on various DL models, that our method consistently outperforms the original models on two edge devices, namely Redmi Note 7S and Raspberry Pi3, with a minimum of 2.2x speedup while maintaining high accuracy. Additionally, we showcase a use case of our GOS approach in pulse rate estimation on wristband devices, where we achieve state-of-the-art performance, while maintaining reduced computational complexity, demonstrating the effectiveness of our approach in practical applications.
MaGNAS: A Mapping-Aware Graph Neural Architecture Search Framework for Heterogeneous MPSoC Deployment
Jul 16, 2023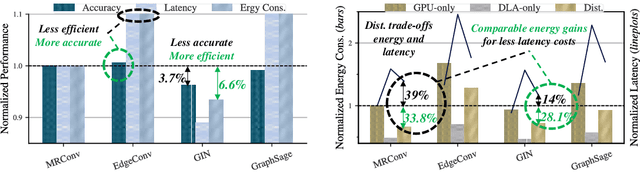
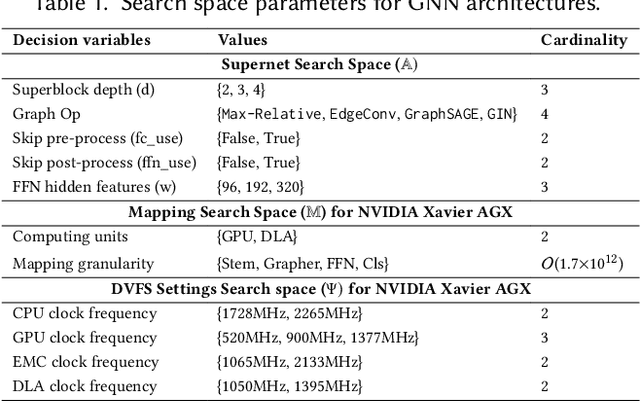
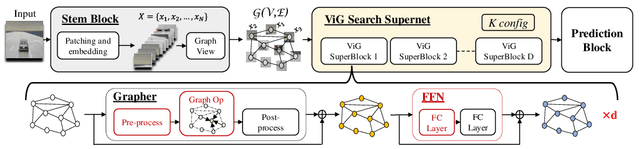
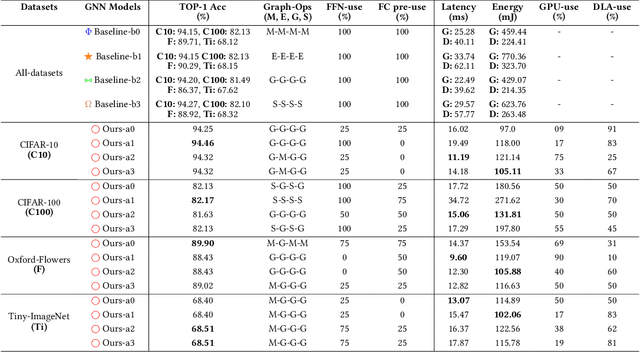
Graph Neural Networks (GNNs) are becoming increasingly popular for vision-based applications due to their intrinsic capacity in modeling structural and contextual relations between various parts of an image frame. On another front, the rising popularity of deep vision-based applications at the edge has been facilitated by the recent advancements in heterogeneous multi-processor Systems on Chips (MPSoCs) that enable inference under real-time, stringent execution requirements. By extension, GNNs employed for vision-based applications must adhere to the same execution requirements. Yet contrary to typical deep neural networks, the irregular flow of graph learning operations poses a challenge to running GNNs on such heterogeneous MPSoC platforms. In this paper, we propose a novel unified design-mapping approach for efficient processing of vision GNN workloads on heterogeneous MPSoC platforms. Particularly, we develop MaGNAS, a mapping-aware Graph Neural Architecture Search framework. MaGNAS proposes a GNN architectural design space coupled with prospective mapping options on a heterogeneous SoC to identify model architectures that maximize on-device resource efficiency. To achieve this, MaGNAS employs a two-tier evolutionary search to identify optimal GNNs and mapping pairings that yield the best performance trade-offs. Through designing a supernet derived from the recent Vision GNN (ViG) architecture, we conducted experiments on four (04) state-of-the-art vision datasets using both (i) a real hardware SoC platform (NVIDIA Xavier AGX) and (ii) a performance/cost model simulator for DNN accelerators. Our experimental results demonstrate that MaGNAS is able to provide 1.57x latency speedup and is 3.38x more energy-efficient for several vision datasets executed on the Xavier MPSoC vs. the GPU-only deployment while sustaining an average 0.11% accuracy reduction from the baseline.
Treasure What You Have: Exploiting Similarity in Deep Neural Networks for Efficient Video Processing
May 10, 2023



Deep learning has enabled various Internet of Things (IoT) applications. Still, designing models with high accuracy and computational efficiency remains a significant challenge, especially in real-time video processing applications. Such applications exhibit high inter- and intra-frame redundancy, allowing further improvement. This paper proposes a similarity-aware training methodology that exploits data redundancy in video frames for efficient processing. Our approach introduces a per-layer regularization that enhances computation reuse by increasing the similarity of weights during training. We validate our methodology on two critical real-time applications, lane detection and scene parsing. We observe an average compression ratio of approximately 50% and a speedup of \sim 1.5x for different models while maintaining the same accuracy.
Map-and-Conquer: Energy-Efficient Mapping of Dynamic Neural Nets onto Heterogeneous MPSoCs
Feb 24, 2023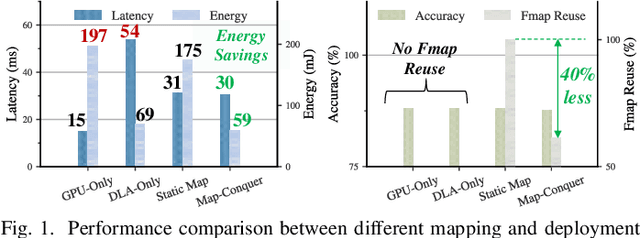
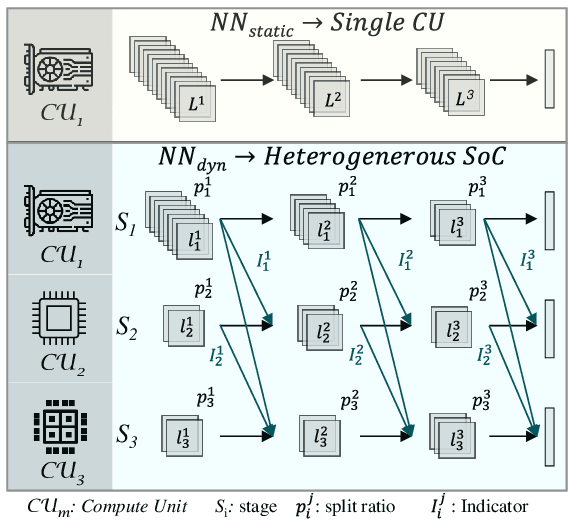

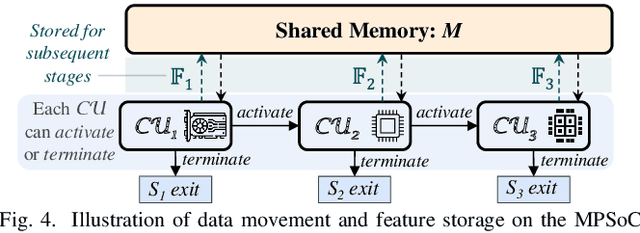
Heterogeneous MPSoCs comprise diverse processing units of varying compute capabilities. To date, the mapping strategies of neural networks (NNs) onto such systems are yet to exploit the full potential of processing parallelism, made possible through both the intrinsic NNs' structure and underlying hardware composition. In this paper, we propose a novel framework to effectively map NNs onto heterogeneous MPSoCs in a manner that enables them to leverage the underlying processing concurrency. Specifically, our approach identifies an optimal partitioning scheme of the NN along its `width' dimension, which facilitates deployment of concurrent NN blocks onto different hardware computing units. Additionally, our approach contributes a novel scheme to deploy partitioned NNs onto the MPSoC as dynamic multi-exit networks for additional performance gains. Our experiments on a standard MPSoC platform have yielded dynamic mapping configurations that are 2.1x more energy-efficient than the GPU-only mapping while incurring 1.7x less latency than DLA-only mapping.
HADAS: Hardware-Aware Dynamic Neural Architecture Search for Edge Performance Scaling
Dec 06, 2022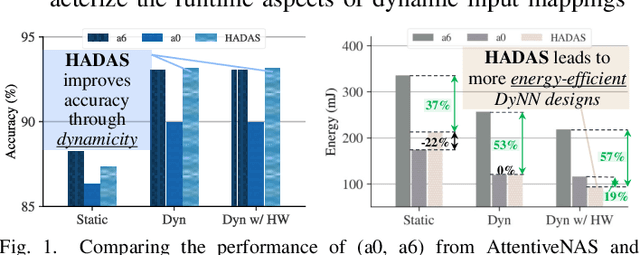
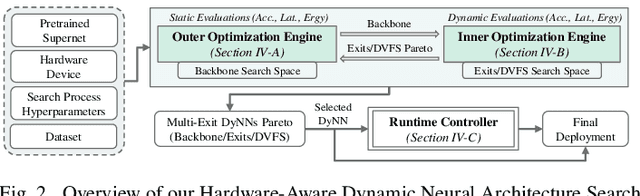
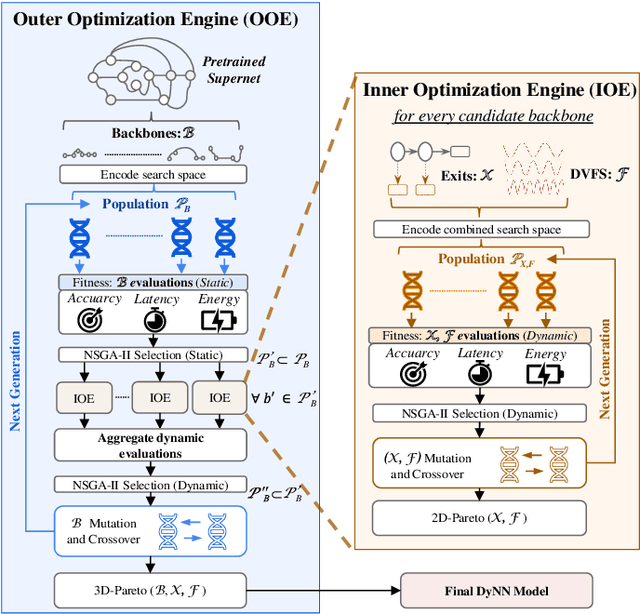
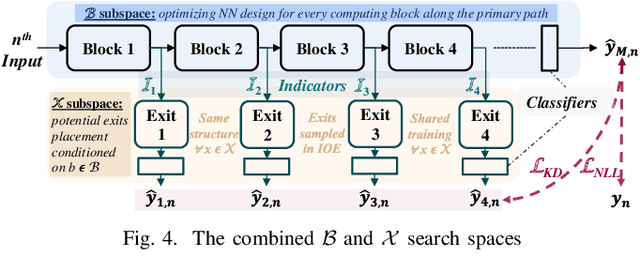
Dynamic neural networks (DyNNs) have become viable techniques to enable intelligence on resource-constrained edge devices while maintaining computational efficiency. In many cases, the implementation of DyNNs can be sub-optimal due to its underlying backbone architecture being developed at the design stage independent of both: (i) the dynamic computing features, e.g. early exiting, and (ii) the resource efficiency features of the underlying hardware, e.g., dynamic voltage and frequency scaling (DVFS). Addressing this, we present HADAS, a novel Hardware-Aware Dynamic Neural Architecture Search framework that realizes DyNN architectures whose backbone, early exiting features, and DVFS settings have been jointly optimized to maximize performance and resource efficiency. Our experiments using the CIFAR-100 dataset and a diverse set of edge computing platforms have seen HADAS dynamic models achieve up to 57% energy efficiency gains compared to the conventional dynamic ones while maintaining the desired level of accuracy scores. Our code is available at https://github.com/HalimaBouzidi/HADAS
A Comprehensive Survey on Hardware-Aware Neural Architecture Search
Jan 22, 2021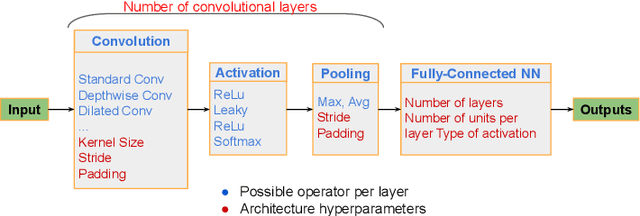
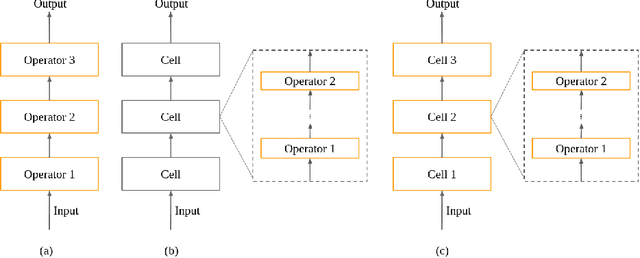
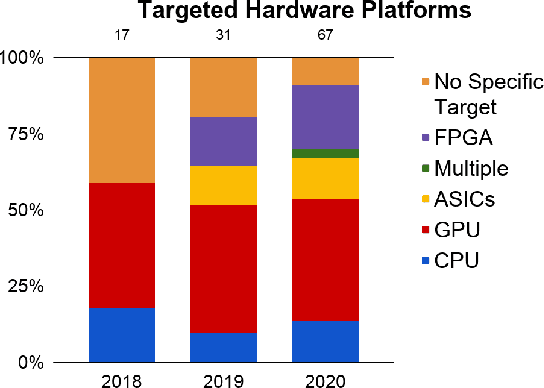
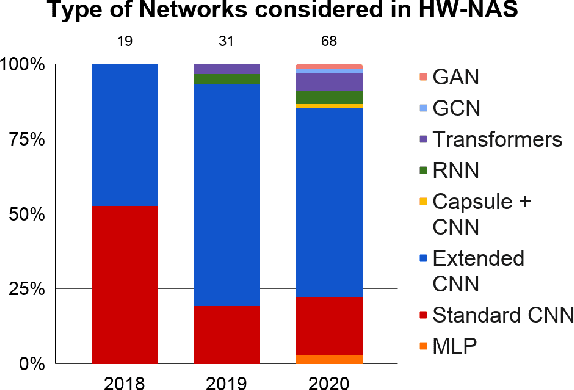
Neural Architecture Search (NAS) methods have been growing in popularity. These techniques have been fundamental to automate and speed up the time consuming and error-prone process of synthesizing novel Deep Learning (DL) architectures. NAS has been extensively studied in the past few years. Arguably their most significant impact has been in image classification and object detection tasks where the state of the art results have been obtained. Despite the significant success achieved to date, applying NAS to real-world problems still poses significant challenges and is not widely practical. In general, the synthesized Convolution Neural Network (CNN) architectures are too complex to be deployed in resource-limited platforms, such as IoT, mobile, and embedded systems. One solution growing in popularity is to use multi-objective optimization algorithms in the NAS search strategy by taking into account execution latency, energy consumption, memory footprint, etc. This kind of NAS, called hardware-aware NAS (HW-NAS), makes searching the most efficient architecture more complicated and opens several questions. In this survey, we provide a detailed review of existing HW-NAS research and categorize them according to four key dimensions: the search space, the search strategy, the acceleration technique, and the hardware cost estimation strategies. We further discuss the challenges and limitations of existing approaches and potential future directions. This is the first survey paper focusing on hardware-aware NAS. We hope it serves as a valuable reference for the various techniques and algorithms discussed and paves the road for future research towards hardware-aware NAS.