 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTreasure What You Have: Exploiting Similarity in Deep Neural Networks for Efficient Video Processing
May 10, 2023



Deep learning has enabled various Internet of Things (IoT) applications. Still, designing models with high accuracy and computational efficiency remains a significant challenge, especially in real-time video processing applications. Such applications exhibit high inter- and intra-frame redundancy, allowing further improvement. This paper proposes a similarity-aware training methodology that exploits data redundancy in video frames for efficient processing. Our approach introduces a per-layer regularization that enhances computation reuse by increasing the similarity of weights during training. We validate our methodology on two critical real-time applications, lane detection and scene parsing. We observe an average compression ratio of approximately 50% and a speedup of \sim 1.5x for different models while maintaining the same accuracy.
GateKeeper-GPU: Fast and Accurate Pre-Alignment Filtering in Short Read Mapping
Mar 31, 2021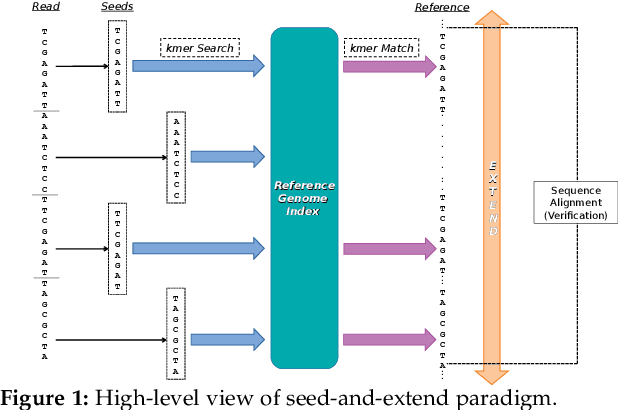
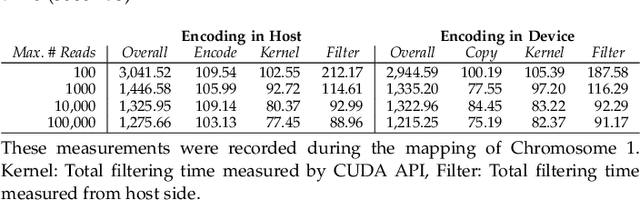

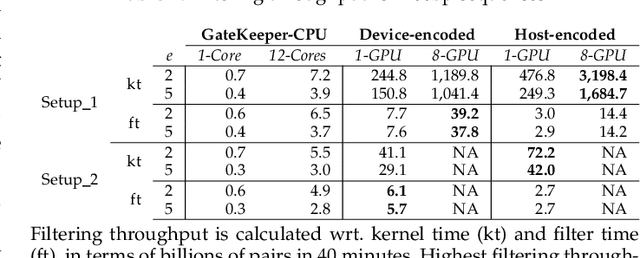
At the last step of short read mapping, the candidate locations of the reads on the reference genome are verified to compute their differences from the corresponding reference segments using sequence alignment algorithms. Calculating the similarities and differences between two sequences is still computationally expensive since approximate string matching techniques traditionally inherit dynamic programming algorithms with quadratic time and space complexity. We introduce GateKeeper-GPU, a fast and accurate pre-alignment filter that efficiently reduces the need for expensive sequence alignment. GateKeeper-GPU provides two main contributions: first, improving the filtering accuracy of GateKeeper(state-of-the-art lightweight pre-alignment filter), second, exploiting the massive parallelism provided by the large number of GPU threads of modern GPUs to examine numerous sequence pairs rapidly and concurrently. GateKeeper-GPU accelerates the sequence alignment by up to 2.9x and provides up to 1.4x speedup to the end-to-end execution time of a comprehensive read mapper (mrFAST). GateKeeper-GPU is available at https://github.com/BilkentCompGen/GateKeeper-GPU