 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparseST: Exploiting Data Sparsity in Spatiotemporal Modeling and Prediction
Nov 18, 2025Spatiotemporal data mining (STDM) has a wide range of applications in various complex physical systems (CPS), i.e., transportation, manufacturing, healthcare, etc. Among all the proposed methods, the Convolutional Long Short-Term Memory (ConvLSTM) has proved to be generalizable and extendable in different applications and has multiple variants achieving state-of-the-art performance in various STDM applications. However, ConvLSTM and its variants are computationally expensive, which makes them inapplicable in edge devices with limited computational resources. With the emerging need for edge computing in CPS, efficient AI is essential to reduce the computational cost while preserving the model performance. Common methods of efficient AI are developed to reduce redundancy in model capacity (i.e., model pruning, compression, etc.). However, spatiotemporal data mining naturally requires extensive model capacity, as the embedded dependencies in spatiotemporal data are complex and hard to capture, which limits the model redundancy. Instead, there is a fairly high level of data and feature redundancy that introduces an unnecessary computational burden, which has been largely overlooked in existing research. Therefore, we developed a novel framework SparseST, that pioneered in exploiting data sparsity to develop an efficient spatiotemporal model. In addition, we explore and approximate the Pareto front between model performance and computational efficiency by designing a multi-objective composite loss function, which provides a practical guide for practitioners to adjust the model according to computational resource constraints and the performance requirements of downstream tasks.
Enhancing Downstream Analysis in Genome Sequencing: Species Classification While Basecalling
Apr 09, 2025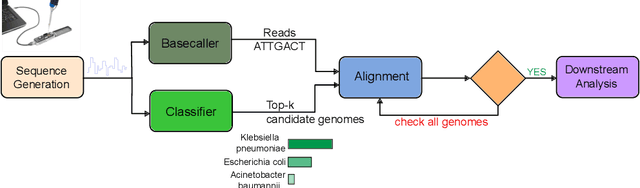

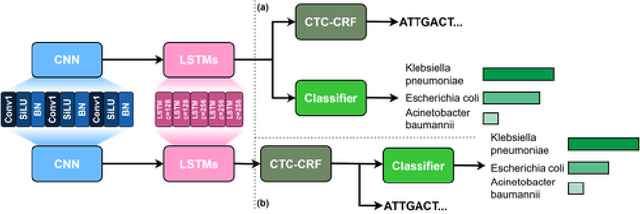
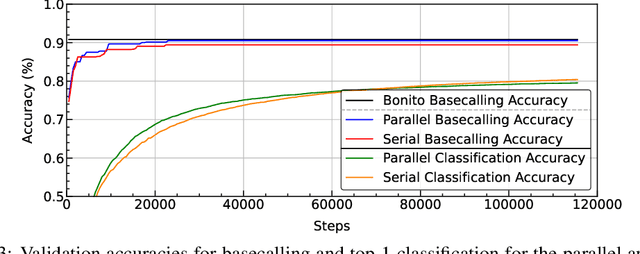
The ability to quickly and accurately identify microbial species in a sample, known as metagenomic profiling, is critical across various fields, from healthcare to environmental science. This paper introduces a novel method to profile signals coming from sequencing devices in parallel with determining their nucleotide sequences, a process known as basecalling, via a multi-objective deep neural network for simultaneous basecalling and multi-class genome classification. We introduce a new loss strategy where losses for basecalling and classification are back-propagated separately, with model weights combined for the shared layers, and a pre-configured ranking strategy allowing top-K species accuracy, giving users flexibility to choose between higher accuracy or higher speed at identifying the species. We achieve state-of-the-art basecalling accuracies, while classification accuracies meet and exceed the results of state-of-the-art binary classifiers, attaining an average of 92.5%/98.9% accuracy at identifying the top-1/3 species among a total of 17 genomes in the Wick bacterial dataset. The work presented here has implications for future studies in metagenomic profiling by accelerating the bottleneck step of matching the DNA sequence to the correct genome.
Combining Neural Architecture Search and Automatic Code Optimization: A Survey
Aug 07, 2024Deep Learning models have experienced exponential growth in complexity and resource demands in recent years. Accelerating these models for efficient execution on resource-constrained devices has become more crucial than ever. Two notable techniques employed to achieve this goal are Hardware-aware Neural Architecture Search (HW-NAS) and Automatic Code Optimization (ACO). HW-NAS automatically designs accurate yet hardware-friendly neural networks, while ACO involves searching for the best compiler optimizations to apply on neural networks for efficient mapping and inference on the target hardware. This survey explores recent works that combine these two techniques within a single framework. We present the fundamental principles of both domains and demonstrate their sub-optimality when performed independently. We then investigate their integration into a joint optimization process that we call Hardware Aware-Neural Architecture and Compiler Optimizations co-Search (NACOS).
FLASH-RL: Federated Learning Addressing System and Static Heterogeneity using Reinforcement Learning
Nov 12, 2023



Federated Learning (FL) has emerged as a promising Machine Learning paradigm, enabling multiple users to collaboratively train a shared model while preserving their local data. To minimize computing and communication costs associated with parameter transfer, it is common practice in FL to select a subset of clients in each training round. This selection must consider both system and static heterogeneity. Therefore, we propose FLASH-RL, a framework that utilizes Double Deep QLearning (DDQL) to address both system and static heterogeneity in FL. FLASH-RL introduces a new reputation-based utility function to evaluate client contributions based on their current and past performances. Additionally, an adapted DDQL algorithm is proposed to expedite the learning process. Experimental results on MNIST and CIFAR-10 datasets have shown FLASH-RL's effectiveness in achieving a balanced trade-off between model performance and end-to-end latency against existing solutions. Indeed, FLASH-RL reduces latency by up to 24.83% compared to FedAVG and 24.67% compared to FAVOR. It also reduces the training rounds by up to 60.44% compared to FedAVG and +76% compared to FAVOR. In fall detection using the MobiAct dataset, FLASH-RL outperforms FedAVG by up to 2.82% in model's performance and reduces latency by up to 34.75%. Additionally, FLASH-RL achieves the target performance faster, with up to a 45.32% reduction in training rounds compared to FedAVG.
Grassroots Operator Search for Model Edge Adaptation
Sep 20, 2023



Hardware-aware Neural Architecture Search (HW-NAS) is increasingly being used to design efficient deep learning architectures. An efficient and flexible search space is crucial to the success of HW-NAS. Current approaches focus on designing a macro-architecture and searching for the architecture's hyperparameters based on a set of possible values. This approach is biased by the expertise of deep learning (DL) engineers and standard modeling approaches. In this paper, we present a Grassroots Operator Search (GOS) methodology. Our HW-NAS adapts a given model for edge devices by searching for efficient operator replacement. We express each operator as a set of mathematical instructions that capture its behavior. The mathematical instructions are then used as the basis for searching and selecting efficient replacement operators that maintain the accuracy of the original model while reducing computational complexity. Our approach is grassroots since it relies on the mathematical foundations to construct new and efficient operators for DL architectures. We demonstrate on various DL models, that our method consistently outperforms the original models on two edge devices, namely Redmi Note 7S and Raspberry Pi3, with a minimum of 2.2x speedup while maintaining high accuracy. Additionally, we showcase a use case of our GOS approach in pulse rate estimation on wristband devices, where we achieve state-of-the-art performance, while maintaining reduced computational complexity, demonstrating the effectiveness of our approach in practical applications.
AnalogNAS: A Neural Network Design Framework for Accurate Inference with Analog In-Memory Computing
May 17, 2023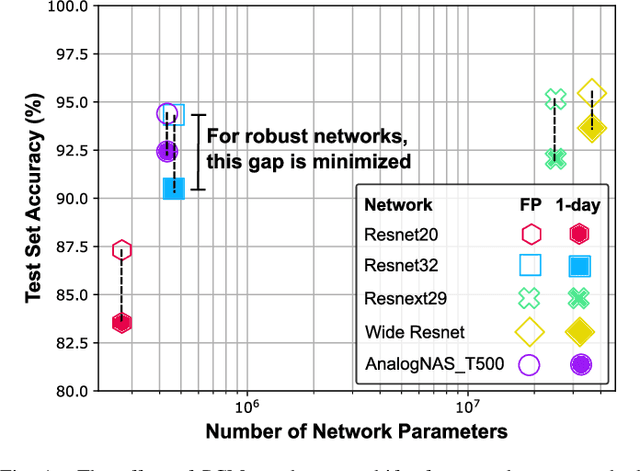
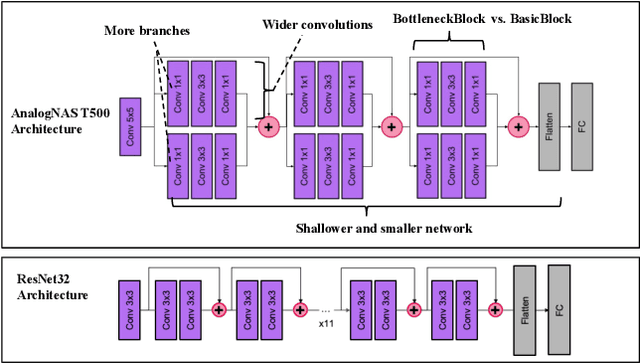
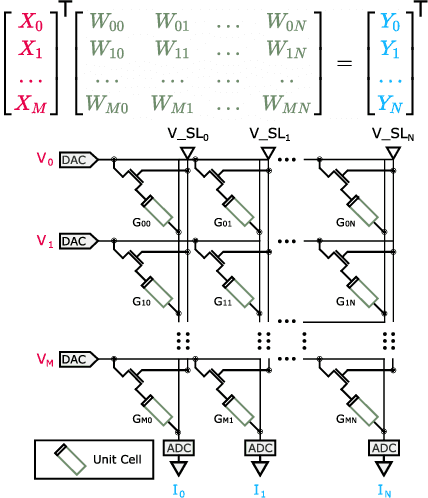
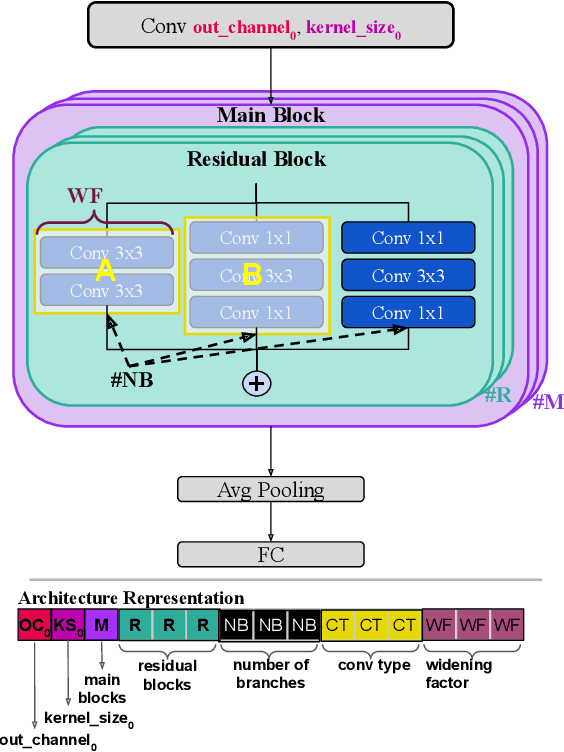
The advancement of Deep Learning (DL) is driven by efficient Deep Neural Network (DNN) design and new hardware accelerators. Current DNN design is primarily tailored for general-purpose use and deployment on commercially viable platforms. Inference at the edge requires low latency, compact and power-efficient models, and must be cost-effective. Digital processors based on typical von Neumann architectures are not conducive to edge AI given the large amounts of required data movement in and out of memory. Conversely, analog/mixed signal in-memory computing hardware accelerators can easily transcend the memory wall of von Neuman architectures when accelerating inference workloads. They offer increased area and power efficiency, which are paramount in edge resource-constrained environments. In this paper, we propose AnalogNAS, a framework for automated DNN design targeting deployment on analog In-Memory Computing (IMC) inference accelerators. We conduct extensive hardware simulations to demonstrate the performance of AnalogNAS on State-Of-The-Art (SOTA) models in terms of accuracy and deployment efficiency on various Tiny Machine Learning (TinyML) tasks. We also present experimental results that show AnalogNAS models achieving higher accuracy than SOTA models when implemented on a 64-core IMC chip based on Phase Change Memory (PCM). The AnalogNAS search code is released: https://github.com/IBM/analog-nas
Treasure What You Have: Exploiting Similarity in Deep Neural Networks for Efficient Video Processing
May 10, 2023



Deep learning has enabled various Internet of Things (IoT) applications. Still, designing models with high accuracy and computational efficiency remains a significant challenge, especially in real-time video processing applications. Such applications exhibit high inter- and intra-frame redundancy, allowing further improvement. This paper proposes a similarity-aware training methodology that exploits data redundancy in video frames for efficient processing. Our approach introduces a per-layer regularization that enhances computation reuse by increasing the similarity of weights during training. We validate our methodology on two critical real-time applications, lane detection and scene parsing. We observe an average compression ratio of approximately 50% and a speedup of \sim 1.5x for different models while maintaining the same accuracy.
Skip Connections in Spiking Neural Networks: An Analysis of Their Effect on Network Training
Mar 23, 2023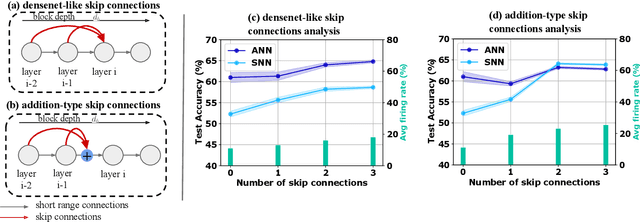

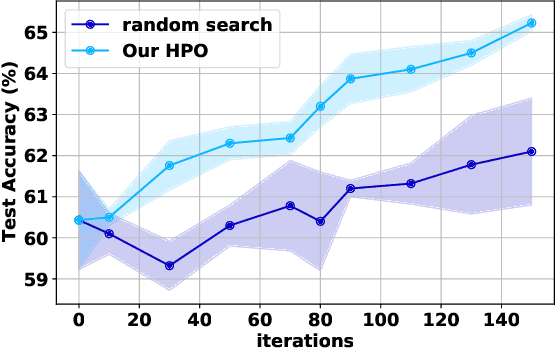
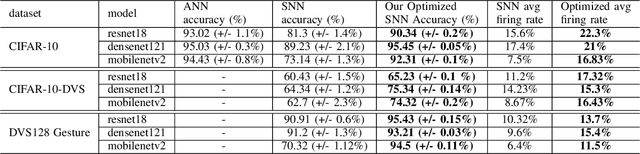
Spiking neural networks (SNNs) have gained attention as a promising alternative to traditional artificial neural networks (ANNs) due to their potential for energy efficiency and their ability to model spiking behavior in biological systems. However, the training of SNNs is still a challenging problem, and new techniques are needed to improve their performance. In this paper, we study the impact of skip connections on SNNs and propose a hyperparameter optimization technique that adapts models from ANN to SNN. We demonstrate that optimizing the position, type, and number of skip connections can significantly improve the accuracy and efficiency of SNNs by enabling faster convergence and increasing information flow through the network. Our results show an average +8% accuracy increase on CIFAR-10-DVS and DVS128 Gesture datasets adaptation of multiple state-of-the-art models.
HyT-NAS: Hybrid Transformers Neural Architecture Search for Edge Devices
Mar 08, 2023



Vision Transformers have enabled recent attention-based Deep Learning (DL) architectures to achieve remarkable results in Computer Vision (CV) tasks. However, due to the extensive computational resources required, these architectures are rarely implemented on resource-constrained platforms. Current research investigates hybrid handcrafted convolution-based and attention-based models for CV tasks such as image classification and object detection. In this paper, we propose HyT-NAS, an efficient Hardware-aware Neural Architecture Search (HW-NAS) including hybrid architectures targeting vision tasks on tiny devices. HyT-NAS improves state-of-the-art HW-NAS by enriching the search space and enhancing the search strategy as well as the performance predictors. Our experiments show that HyT-NAS achieves a similar hypervolume with less than ~5x training evaluations. Our resulting architecture outperforms MLPerf MobileNetV1 by 6.3% accuracy improvement with 3.5x less number of parameters on Visual Wake Words.
A Comprehensive Survey on Hardware-Aware Neural Architecture Search
Jan 22, 2021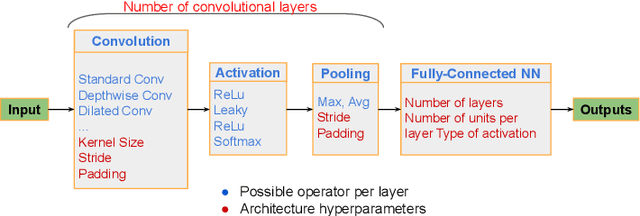
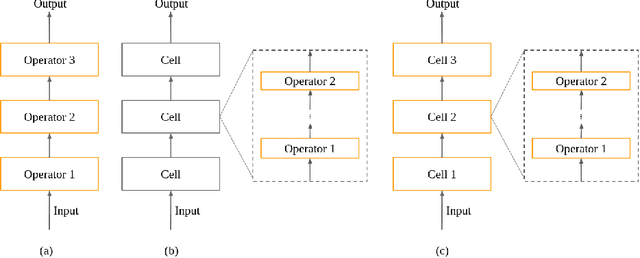
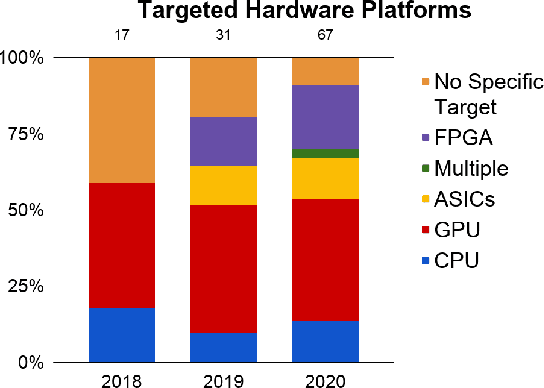
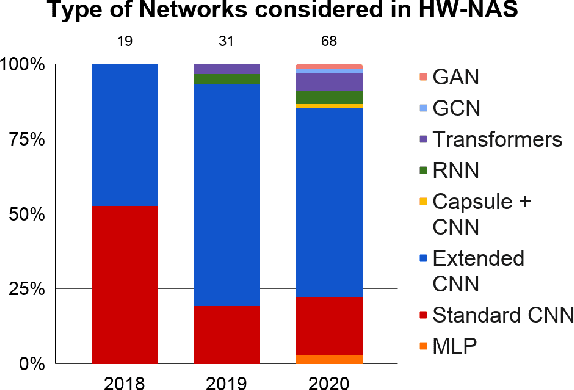
Neural Architecture Search (NAS) methods have been growing in popularity. These techniques have been fundamental to automate and speed up the time consuming and error-prone process of synthesizing novel Deep Learning (DL) architectures. NAS has been extensively studied in the past few years. Arguably their most significant impact has been in image classification and object detection tasks where the state of the art results have been obtained. Despite the significant success achieved to date, applying NAS to real-world problems still poses significant challenges and is not widely practical. In general, the synthesized Convolution Neural Network (CNN) architectures are too complex to be deployed in resource-limited platforms, such as IoT, mobile, and embedded systems. One solution growing in popularity is to use multi-objective optimization algorithms in the NAS search strategy by taking into account execution latency, energy consumption, memory footprint, etc. This kind of NAS, called hardware-aware NAS (HW-NAS), makes searching the most efficient architecture more complicated and opens several questions. In this survey, we provide a detailed review of existing HW-NAS research and categorize them according to four key dimensions: the search space, the search strategy, the acceleration technique, and the hardware cost estimation strategies. We further discuss the challenges and limitations of existing approaches and potential future directions. This is the first survey paper focusing on hardware-aware NAS. We hope it serves as a valuable reference for the various techniques and algorithms discussed and paves the road for future research towards hardware-aware NAS.