 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting Linear Recurrent Models: How Different Gating Strategies Drive Selectivity and Generalization
Jan 18, 2026Linear recurrent neural networks have emerged as efficient alternatives to the original Transformer's softmax attention mechanism, thanks to their highly parallelizable training and constant memory and computation requirements at inference. Iterative refinements of these models have introduced an increasing number of architectural mechanisms, leading to increased complexity and computational costs. Nevertheless, systematic direct comparisons among these models remain limited. Existing benchmark tasks are either too simplistic to reveal substantial differences or excessively resource-intensive for experimentation. In this work, we propose a refined taxonomy of linear recurrent models and introduce SelectivBench, a set of lightweight and customizable synthetic benchmark tasks for systematically evaluating sequence models. SelectivBench specifically evaluates selectivity in sequence models at small to medium scale, such as the capacity to focus on relevant inputs while ignoring context-based distractors. It employs rule-based grammars to generate sequences with adjustable complexity, incorporating irregular gaps that intentionally violate transition rules. Evaluations of linear recurrent models on SelectivBench reveal performance patterns consistent with results from large-scale language tasks. Our analysis clarifies the roles of essential architectural features: gating and rapid forgetting mechanisms facilitate recall, in-state channel mixing is unnecessary for selectivity, but critical for generalization, and softmax attention remains dominant due to its memory capacity scaling with sequence length. Our benchmark enables targeted, efficient exploration of linear recurrent models and provides a controlled setting for studying behaviors observed in large-scale evaluations. Code is available at https://github.com/symseqbench/selectivbench
SymSeqBench: a unified framework for the generation and analysis of rule-based symbolic sequences and datasets
Dec 31, 2025Sequential structure is a key feature of multiple domains of natural cognition and behavior, such as language, movement and decision-making. Likewise, it is also a central property of tasks to which we would like to apply artificial intelligence. It is therefore of great importance to develop frameworks that allow us to evaluate sequence learning and processing in a domain agnostic fashion, whilst simultaneously providing a link to formal theories of computation and computability. To address this need, we introduce two complementary software tools: SymSeq, designed to rigorously generate and analyze structured symbolic sequences, and SeqBench, a comprehensive benchmark suite of rule-based sequence processing tasks to evaluate the performance of artificial learning systems in cognitively relevant domains. In combination, SymSeqBench offers versatility in investigating sequential structure across diverse knowledge domains, including experimental psycholinguistics, cognitive psychology, behavioral analysis, neuromorphic computing and artificial intelligence. Due to its basis in Formal Language Theory (FLT), SymSeqBench provides researchers in multiple domains with a convenient and practical way to apply the concepts of FLT to conceptualize and standardize their experiments, thus advancing our understanding of cognition and behavior through shared computational frameworks and formalisms. The tool is modular, openly available and accessible to the research community.
QS4D: Quantization-aware training for efficient hardware deployment of structured state-space sequential models
Jul 08, 2025Structured State Space models (SSM) have recently emerged as a new class of deep learning models, particularly well-suited for processing long sequences. Their constant memory footprint, in contrast to the linearly scaling memory demands of Transformers, makes them attractive candidates for deployment on resource-constrained edge-computing devices. While recent works have explored the effect of quantization-aware training (QAT) on SSMs, they typically do not address its implications for specialized edge hardware, for example, analog in-memory computing (AIMC) chips. In this work, we demonstrate that QAT can significantly reduce the complexity of SSMs by up to two orders of magnitude across various performance metrics. We analyze the relation between model size and numerical precision, and show that QAT enhances robustness to analog noise and enables structural pruning. Finally, we integrate these techniques to deploy SSMs on a memristive analog in-memory computing substrate and highlight the resulting benefits in terms of computational efficiency.
NeuroBench: Advancing Neuromorphic Computing through Collaborative, Fair and Representative Benchmarking
Apr 15, 2023



The field of neuromorphic computing holds great promise in terms of advancing computing efficiency and capabilities by following brain-inspired principles. However, the rich diversity of techniques employed in neuromorphic research has resulted in a lack of clear standards for benchmarking, hindering effective evaluation of the advantages and strengths of neuromorphic methods compared to traditional deep-learning-based methods. This paper presents a collaborative effort, bringing together members from academia and the industry, to define benchmarks for neuromorphic computing: NeuroBench. The goals of NeuroBench are to be a collaborative, fair, and representative benchmark suite developed by the community, for the community. In this paper, we discuss the challenges associated with benchmarking neuromorphic solutions, and outline the key features of NeuroBench. We believe that NeuroBench will be a significant step towards defining standards that can unify the goals of neuromorphic computing and drive its technological progress. Please visit neurobench.ai for the latest updates on the benchmark tasks and metrics.
Skip Connections in Spiking Neural Networks: An Analysis of Their Effect on Network Training
Mar 23, 2023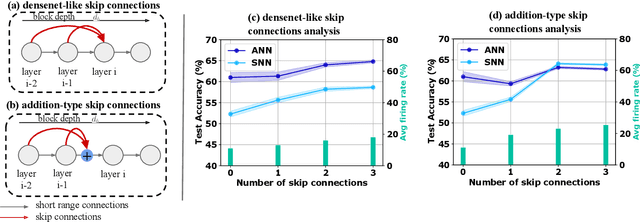

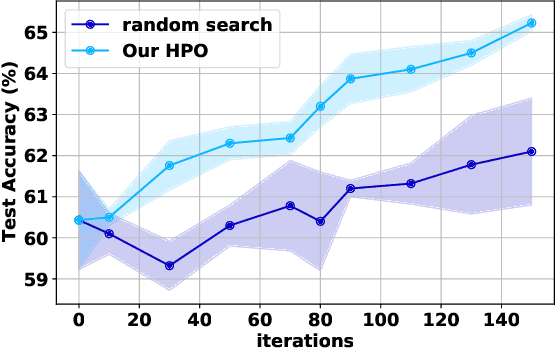
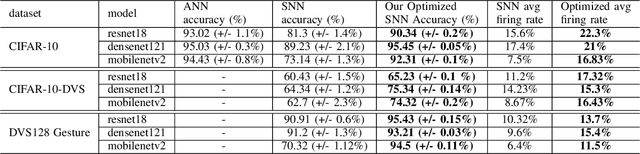
Spiking neural networks (SNNs) have gained attention as a promising alternative to traditional artificial neural networks (ANNs) due to their potential for energy efficiency and their ability to model spiking behavior in biological systems. However, the training of SNNs is still a challenging problem, and new techniques are needed to improve their performance. In this paper, we study the impact of skip connections on SNNs and propose a hyperparameter optimization technique that adapts models from ANN to SNN. We demonstrate that optimizing the position, type, and number of skip connections can significantly improve the accuracy and efficiency of SNNs by enabling faster convergence and increasing information flow through the network. Our results show an average +8% accuracy increase on CIFAR-10-DVS and DVS128 Gesture datasets adaptation of multiple state-of-the-art models.
Sequence learning in a spiking neuronal network with memristive synapses
Nov 29, 2022Brain-inspired computing proposes a set of algorithmic principles that hold promise for advancing artificial intelligence. They endow systems with self learning capabilities, efficient energy usage, and high storage capacity. A core concept that lies at the heart of brain computation is sequence learning and prediction. This form of computation is essential for almost all our daily tasks such as movement generation, perception, and language. Understanding how the brain performs such a computation is not only important to advance neuroscience but also to pave the way to new technological brain-inspired applications. A previously developed spiking neural network implementation of sequence prediction and recall learns complex, high-order sequences in an unsupervised manner by local, biologically inspired plasticity rules. An emerging type of hardware that holds promise for efficiently running this type of algorithm is neuromorphic hardware. It emulates the way the brain processes information and maps neurons and synapses directly into a physical substrate. Memristive devices have been identified as potential synaptic elements in neuromorphic hardware. In particular, redox-induced resistive random access memories (ReRAM) devices stand out at many aspects. They permit scalability, are energy efficient and fast, and can implement biological plasticity rules. In this work, we study the feasibility of using ReRAM devices as a replacement of the biological synapses in the sequence learning model. We implement and simulate the model including the ReRAM plasticity using the neural simulator NEST. We investigate the effect of different device properties on the performance characteristics of the sequence learning model, and demonstrate resilience with respect to different on-off ratios, conductance resolutions, device variability, and synaptic failure.
On transfer learning using a MAC model variant
Nov 16, 2018

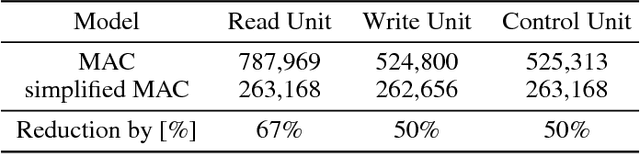

We introduce a variant of the MAC model (Hudson and Manning, ICLR 2018) with a simplified set of equations that achieves comparable accuracy, while training faster. We evaluate both models on CLEVR and CoGenT, and show that, transfer learning with fine-tuning results in a 15 point increase in accuracy, matching the state of the art. Finally, in contrast, we demonstrate that improper fine-tuning can actually reduce a model's accuracy as well.
Learning to Remember, Forget and Ignore using Attention Control in Memory
Sep 28, 2018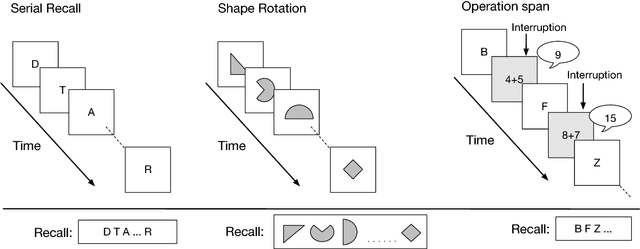


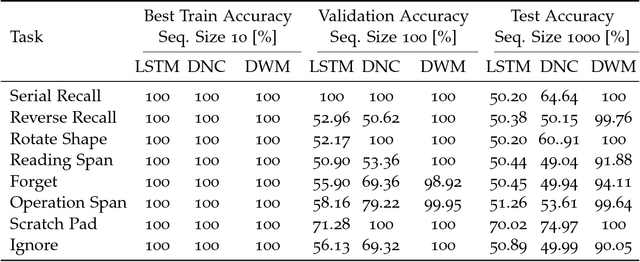
Typical neural networks with external memory do not effectively separate capacity for episodic and working memory as is required for reasoning in humans. Applying knowledge gained from psychological studies, we designed a new model called Differentiable Working Memory (DWM) in order to specifically emulate human working memory. As it shows the same functional characteristics as working memory, it robustly learns psychology inspired tasks and converges faster than comparable state-of-the-art models. Moreover, the DWM model successfully generalizes to sequences two orders of magnitude longer than the ones used in training. Our in-depth analysis shows that the behavior of DWM is interpretable and that it learns to have fine control over memory, allowing it to retain, ignore or forget information based on its relevance.