 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA 32-Channel 3.53-μW Per Channel Brain-Machine Interface SoC Featuring Dual-Threshold Delta-modulation, In-Memory Spike Detection and Bi-SNN Based Motor Decoding
Jun 01, 2026With the scaling of sensor channel counts, systems confront challenges in frontend data sensing and on-implant data processing. This work presents a 32-channel fully event-based iBMI SoC in 65nm CMOS for an efficient neuromorphic signal processing pipeline. The SoC integrates a 32-channel dual-threshold delta modulation (DTDM) frontend array that provides up to 26x data compression at the frontend, an in-memory computing (IMC) spike detector (SPD) for efficient in-pixel spike detection, and a bipolar LIF-based spiking neural network (Bi-SNN) decoder for on-chip motor intention decoding (MID). Consuming only 3.53 μW per channel and achieving ~0.62 decoding R2 with a compact 0.034 mm2 per-channel area, the chip enables high-efficiency signal recording, processing, and decoding for implantable devices.
SNNF: An SNN-based Near-Sensor Noise Filter for Dynamic Vision Sensors
May 03, 2026Dynamic Vision Sensors (DVS) exhibit exceptional dynamic range and low power consumption, making them ideal for edge applications in the Internet of Video Things (IoVT). However, their output is often degraded by spurious Background Activity (BA) noise, leading to unnecessary computational overhead. This paper proposes SNNF, a near-sensor BA noise filter that integrates a compact Event-Based Binary Image (EBBI) representation, a parallel memory architecture, and a single-layer Spiking Neural Network (SNN) classifier. Trained on representative DVS data, the SNN distinguishes signal events from noise with an AUC of 0.89 on standard datasets. The binary-array-based EBBI eliminates timestamp dependency, significantly reducing memory footprint. Moreover, the SNN's spike-based computation replaces power-hungry multipliers with simple accumulation logic and minimizes inter-neuron data width, resulting in an extremely hardware-efficient design. FPGA implementation results show that SNNF reduces memory and logic resources to approximately 11% and 40%, respectively of state-of-the-art filters, while achieving a throughput of 29 Mega events per second (Meps). In a 65 nm CMOS ASIC implementation, SNNF achieves 44.4 Meps with an area and power consumption of only ~13% and <5% of the corresponding ANN-based designs. These results demonstrate that SNNF provides an excellent balance between filtering accuracy and hardware efficiency, making it highly suitable for resource-constrained, near-sensor deployment.
SRAM-Based Compute-in-Memory Accelerator for Linear-decay Spiking Neural Networks
Mar 13, 2026Spiking Neural Networks (SNNs) have emerged as a biologically inspired alternative to conventional deep networks, offering event-driven and energy-efficient computation. However, their throughput remains constrained by the serial update of neuron membrane states. While many hardware accelerators and Compute-in-Memory (CIM) architectures efficiently parallelize the synaptic operation (W x I) achieving O(1) complexity for matrix-vector multiplication, the subsequent state update step still requires O(N) time to refresh all neuron membrane potentials. This mismatch makes state update the dominant latency and energy bottleneck in SNN inference. To address this challenge, we propose an SRAM-based CIM for SNN with Linear Decay Leaky Integrate-and-Fire (LD-LIF) Neuron that co-optimizes algorithm and hardware. At the algorithmic level, we replace the conventional exponential membrane decay with a linear decay approximation, converting costly multiplications into simple additions while accuracy drops only around 1%. At the architectural level, we introduce an in-memory parallel update scheme that performs in-place decay directly within the SRAM array, eliminating the need for global sequential updates. Evaluated on benchmark SNN workloads, the proposed method achieves a 1.1 x to 16.7 x reduction of SOP energy consumption, while providing 15.9 x to 69 x more energy efficiency, with negligible accuracy loss relative to original decay models. This work highlights that beyond accelerating the (W x I) computation, optimizing state-update dynamics within CIM architectures is essential for scalable, low-power, and real-time neuromorphic processing.
An Event-Driven E-Skin System with Dynamic Binary Scanning and real time SNN Classification
Mar 11, 2026This paper presents a novel hardware system for high-speed, event-sparse sampling-based electronic skin (e-skin)that integrates sensing and neuromorphic computing. The system is built around a 16x16 piezoresistive tactile array with front end and introduces a event-based binary scan search strategy to classify the digits. This event-driven strategy achieves a 12.8x reduction in scan counts, a 38.2x data compression rate and a 28.4x equivalent dynamic range, a 99% data sparsity, drastically reducing the data acquisition overhead. The resulting sparse data stream is processed by a multi-layer convolutional spiking neural network (Conv-SNN) implemented on an FPGA, which requires only 65% of the computation and 15.6% of the weight storage relative to a CNN. Despite these significant efficiency gains, the system maintains a high classification accuracy of 92.11% for real-time handwritten digit recognition. Furthermore, a real neuromorphic tactile dataset using Address Event Representation (AER) is constructed. This work demonstrates a fully integrated, event-driven pipeline from analog sensing to neuromorphic classification, offering an efficient solution for robotic perception and human-computer interaction.
STEMNIST: Spiking Tactile Extended MNIST Neuromorphic Dataset
Jan 04, 2026Tactile sensing is essential for robotic manipulation, prosthetics and assistive technologies, yet neuromorphic tactile datasets remain limited compared to their visual counterparts. We introduce STEMNIST, a large-scale neuromorphic tactile dataset extending ST-MNIST from 10 digits to 35 alphanumeric classes (uppercase letters A--Z and digits 1--9), providing a challenging benchmark for event-based haptic recognition. The dataset comprises 7,700 samples collected from 34 participants using a custom \(16\times 16\) tactile sensor array operating at 120 Hz, encoded as 1,005,592 spike events through adaptive temporal differentiation. Following EMNIST's visual character recognition protocol, STEMNIST addresses the critical gap between simplified digit classification and real-world tactile interaction scenarios requiring alphanumeric discrimination. Baseline experiments using conventional CNNs (90.91% test accuracy) and spiking neural networks (89.16%) establish performance benchmarks. The dataset's event-based format, unrestricted spatial variability and rich temporal structure makes it suitable for testing neuromorphic hardware and bio-inspired learning algorithms. STEMNIST enables reproducible evaluation of tactile recognition systems and provides a foundation for advancing energy-efficient neuromorphic perception in robotics, biomedical engineering and human-machine interfaces. The dataset, documentation and codes are publicly available to accelerate research in neuromorphic tactile computing.
1024-Channel 0.8V 23.9-nW/Channel Event-based Compute In-memory Neural Spike Detector
Dec 09, 2025



The increasing data rate has become a major issue confronting next-generation intracortical brain-machine interfaces (iBMIs). The scaling number of recording sites requires complex analog wiring and lead to huge digitization power consumption. Compressive event-based neural frontends have been used in high-density neural implants to support the simultaneous recording of more channels. Event-based frontends (EBF) convert recorded signals into asynchronous digital events via delta modulation and can inherently achieve considerable compression. But EBFs are prone to false events that do not correspond to neural spikes. Spike detection (SPD) is a key process in the iBMI pipeline to detect neural spikes and further reduce the data rate. However, conventional digital SPD suffers from the increasing buffer size and frequent memory access power, and conventional spike emphasizers are not compatible with EBFs. In this work we introduced an event-based spike detection (Ev-SPD) algorithm for scalable compressive EBFs. To implement the algorithm effectively, we proposed a novel low-power 10-T eDRAM-SRAM hybrid random-access memory in-memory computing bitcell for event processing. We fabricated the proposed 1024-channel IMC SPD macro in a 65nm process and tested the macro with both synthetic dataset and Neuropixel recordings. The proposed macro achieved a high spike detection accuracy of 96.06% on a synthetic dataset and 95.08% similarity and 0.05 firing pattern MAE on Neuropixel recordings. Our event-based IMC SPD macro achieved a high per channel spike detection energy efficiency of 23.9 nW per channel and an area efficiency of 375 um^2 per channel. Our work presented a SPD scheme compatible with compressive EBFs for high-density iBMIs, achieving ultra-low power consumption with an IMC architecture while maintaining considerable accuracy.
Event-based Neural Spike Detection Using Spiking Neural Networks for Neuromorphic iBMI Systems
May 10, 2025Implantable brain-machine interfaces (iBMIs) are evolving to record from thousands of neurons wirelessly but face challenges in data bandwidth, power consumption, and implant size. We propose a novel Spiking Neural Network Spike Detector (SNN-SPD) that processes event-based neural data generated via delta modulation and pulse count modulation, converting signals into sparse events. By leveraging the temporal dynamics and inherent sparsity of spiking neural networks, our method improves spike detection performance while maintaining low computational overhead suitable for implantable devices. Our experimental results demonstrate that the proposed SNN-SPD achieves an accuracy of 95.72% at high noise levels (standard deviation 0.2), which is about 2% higher than the existing Artificial Neural Network Spike Detector (ANN-SPD). Moreover, SNN-SPD requires only 0.41% of the computation and about 26.62% of the weight parameters compared to ANN-SPD, with zero multiplications. This approach balances efficiency and performance, enabling effective data compression and power savings for next-generation iBMIs.
Architectural Exploration of Hybrid Neural Decoders for Neuromorphic Implantable BMI
May 09, 2025This work presents an efficient decoding pipeline for neuromorphic implantable brain-machine interfaces (Neu-iBMI), leveraging sparse neural event data from an event-based neural sensing scheme. We introduce a tunable event filter (EvFilter), which also functions as a spike detector (EvFilter-SPD), significantly reducing the number of events processed for decoding by 192X and 554X, respectively. The proposed pipeline achieves high decoding performance, up to R^2=0.73, with ANN- and SNN-based decoders, eliminating the need for signal recovery, spike detection, or sorting, commonly performed in conventional iBMI systems. The SNN-Decoder reduces computations and memory required by 5-23X compared to NN-, and LSTM-Decoders, while the ST-NN-Decoder delivers similar performance to an LSTM-Decoder requiring 2.5X fewer resources. This streamlined approach significantly reduces computational and memory demands, making it ideal for low-power, on-implant, or wearable iBMIs.
SPACE: SPike-Aware Consistency Enhancement for Test-Time Adaptation in Spiking Neural Networks
Apr 03, 2025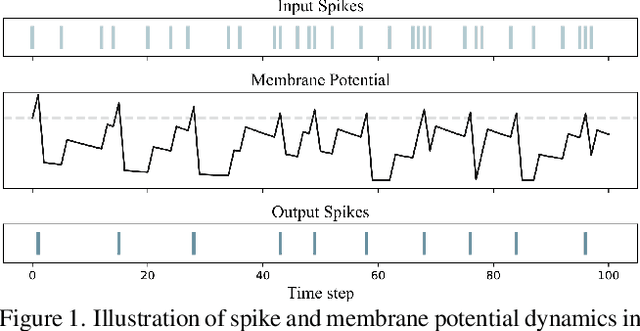

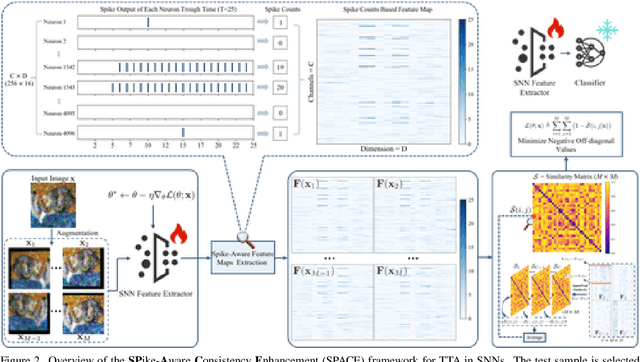

Spiking Neural Networks (SNNs), as a biologically plausible alternative to Artificial Neural Networks (ANNs), have demonstrated advantages in terms of energy efficiency, temporal processing, and biological plausibility. However, SNNs are highly sensitive to distribution shifts, which can significantly degrade their performance in real-world scenarios. Traditional test-time adaptation (TTA) methods designed for ANNs often fail to address the unique computational dynamics of SNNs, such as sparsity and temporal spiking behavior. To address these challenges, we propose $\textbf{SP}$ike-$\textbf{A}$ware $\textbf{C}$onsistency $\textbf{E}$nhancement (SPACE), the first source-free and single-instance TTA method specifically designed for SNNs. SPACE leverages the inherent spike dynamics of SNNs to maximize the consistency of spike-behavior-based local feature maps across augmented versions of a single test sample, enabling robust adaptation without requiring source data. We evaluate SPACE on multiple datasets, including CIFAR-10-C, CIFAR-100-C, Tiny-ImageNet-C and DVS Gesture-C. Furthermore, SPACE demonstrates strong generalization across different model architectures, achieving consistent performance improvements on both VGG9 and ResNet11. Experimental results show that SPACE outperforms state-of-the-art methods, highlighting its effectiveness and robustness in real-world settings.
A Low-Power Spike Detector Using In-Memory Computing for Event-based Neural Frontend
May 14, 2024With the sensor scaling of next-generation Brain-Machine Interface (BMI) systems, the massive A/D conversion and analog multiplexing at the neural frontend poses a challenge in terms of power and data rates for wireless and implantable BMIs. While previous works have reported the neuromorphic compression of neural signal, further compression requires integration of spike detectors on chip. In this work, we propose an efficient HRAM-based spike detector using In-memory computing for compressive event-based neural frontend. Our proposed method involves detecting spikes from event pulses without reconstructing the signal and uses a 10T hybrid in-memory computing bitcell for the accumulation and thresholding operations. We show that our method ensures a spike detection accuracy of 92-99% for neural signal inputs while consuming only 13.8 nW per channel in 65 nm CMOS.