 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoBiQuant: Mixture-of-Bits Quantization for Token-Adaptive Elastic LLMs
Feb 21, 2026Changing runtime complexity on cloud and edge devices necessitates elastic large language model (LLM) deployment, where an LLM can be inferred with various quantization precisions based on available computational resources. However, it has been observed that the calibration parameters for quantization are typically linked to specific precisions, which presents challenges during elastic-precision calibration and precision switching at runtime. In this work, we attribute the source of varying calibration parameters to the varying token-level sensitivity caused by a precision-dependent outlier migration phenomenon.Motivated by this observation, we propose \texttt{MoBiQuant}, a novel Mixture-of-Bits quantization framework that adjusts weight precision for elastic LLM inference based on token sensitivity. Specifically, we propose the many-in-one recursive residual quantization that can iteratively reconstruct higher-precision weights and the token-aware router to dynamically select the number of residual bit slices. MoBiQuant enables smooth precision switching while improving generalization for the distribution of token outliers. Experimental results demonstrate that MoBiQuant exhibits strong elasticity, enabling it to match the performance of bit-specific calibrated PTQ on LLaMA3-8B without repeated calibration.
Efficient Multi-bit Quantization Network Training via Weight Bias Correction and Bit-wise Coreset Sampling
Oct 23, 2025Multi-bit quantization networks enable flexible deployment of deep neural networks by supporting multiple precision levels within a single model. However, existing approaches suffer from significant training overhead as full-dataset updates are repeated for each supported bit-width, resulting in a cost that scales linearly with the number of precisions. Additionally, extra fine-tuning stages are often required to support additional or intermediate precision options, further compounding the overall training burden. To address this issue, we propose two techniques that greatly reduce the training overhead without compromising model utility: (i) Weight bias correction enables shared batch normalization and eliminates the need for fine-tuning by neutralizing quantization-induced bias across bit-widths and aligning activation distributions; and (ii) Bit-wise coreset sampling strategy allows each child model to train on a compact, informative subset selected via gradient-based importance scores by exploiting the implicit knowledge transfer phenomenon. Experiments on CIFAR-10/100, TinyImageNet, and ImageNet-1K with both ResNet and ViT architectures demonstrate that our method achieves competitive or superior accuracy while reducing training time up to 7.88x. Our code is released at https://github.com/a2jinhee/EMQNet_jk.
MSQ: Memory-Efficient Bit Sparsification Quantization
Jul 30, 2025As deep neural networks (DNNs) see increased deployment on mobile and edge devices, optimizing model efficiency has become crucial. Mixed-precision quantization is widely favored, as it offers a superior balance between efficiency and accuracy compared to uniform quantization. However, finding the optimal precision for each layer is challenging. Recent studies utilizing bit-level sparsity have shown promise, yet they often introduce substantial training complexity and high GPU memory requirements. In this paper, we propose Memory-Efficient Bit Sparsification Quantization (MSQ), a novel approach that addresses these limitations. MSQ applies a round-clamp quantizer to enable differentiable computation of the least significant bits (LSBs) from model weights. It further employs regularization to induce sparsity in these LSBs, enabling effective precision reduction without explicit bit-level parameter splitting. Additionally, MSQ incorporates Hessian information, allowing the simultaneous pruning of multiple LSBs to further enhance training efficiency. Experimental results show that MSQ achieves up to 8.00x reduction in trainable parameters and up to 86% reduction in training time compared to previous bit-level quantization, while maintaining competitive accuracy and compression rates. This makes it a practical solution for training efficient DNNs on resource-constrained devices.
Do Not Mimic My Voice: Speaker Identity Unlearning for Zero-Shot Text-to-Speech
Jul 27, 2025The rapid advancement of Zero-Shot Text-to-Speech (ZS-TTS) technology has enabled high-fidelity voice synthesis from minimal audio cues, raising significant privacy and ethical concerns. Despite the threats to voice privacy, research to selectively remove the knowledge to replicate unwanted individual voices from pre-trained model parameters has not been explored. In this paper, we address the new challenge of speaker identity unlearning for ZS-TTS systems. To meet this goal, we propose the first machine unlearning frameworks for ZS-TTS, especially Teacher-Guided Unlearning (TGU), designed to ensure the model forgets designated speaker identities while retaining its ability to generate accurate speech for other speakers. Our proposed methods incorporate randomness to prevent consistent replication of forget speakers' voices, assuring unlearned identities remain untraceable. Additionally, we propose a new evaluation metric, speaker-Zero Retrain Forgetting (spk-ZRF). This assesses the model's ability to disregard prompts associated with forgotten speakers, effectively neutralizing its knowledge of these voices. The experiments conducted on the state-of-the-art model demonstrate that TGU prevents the model from replicating forget speakers' voices while maintaining high quality for other speakers. The demo is available at https://speechunlearn.github.io/
TruncQuant: Truncation-Ready Quantization for DNNs with Flexible Weight Bit Precision
Jun 13, 2025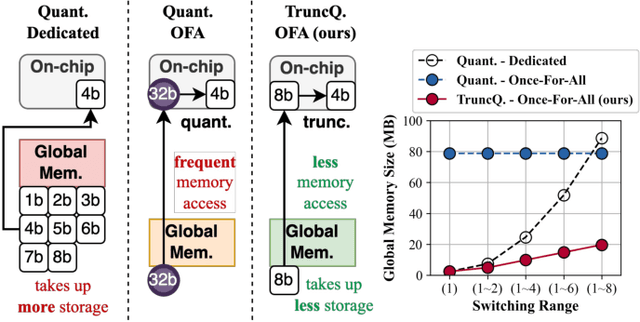
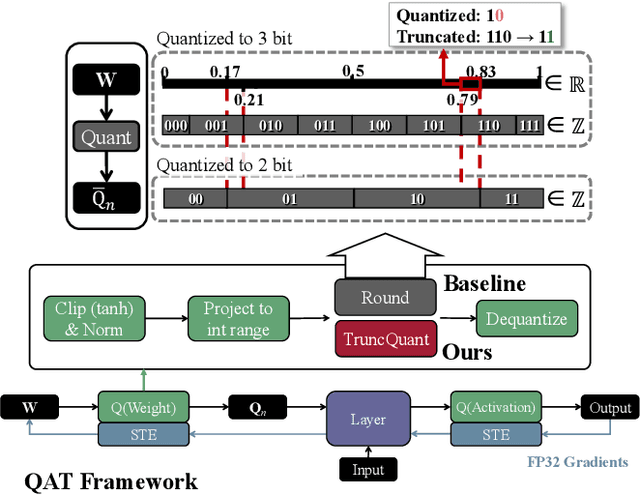
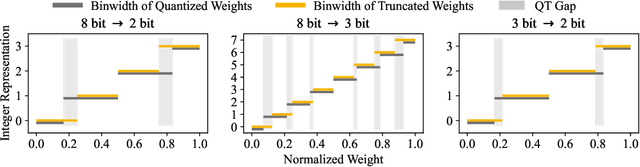
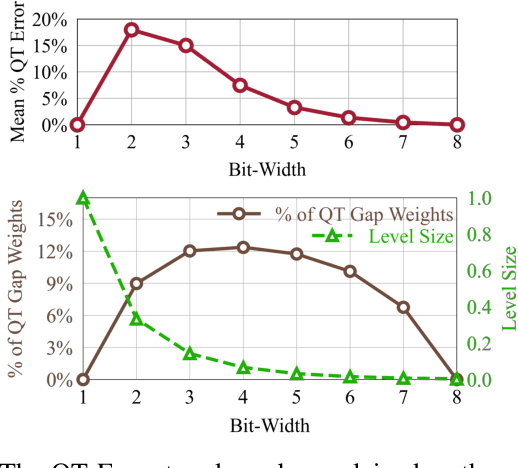
The deployment of deep neural networks on edge devices is a challenging task due to the increasing complexity of state-of-the-art models, requiring efforts to reduce model size and inference latency. Recent studies explore models operating at diverse quantization settings to find the optimal point that balances computational efficiency and accuracy. Truncation, an effective approach for achieving lower bit precision mapping, enables a single model to adapt to various hardware platforms with little to no cost. However, formulating a training scheme for deep neural networks to withstand the associated errors introduced by truncation remains a challenge, as the current quantization-aware training schemes are not designed for the truncation process. We propose TruncQuant, a novel truncation-ready training scheme allowing flexible bit precision through bit-shifting in runtime. We achieve this by aligning TruncQuant with the output of the truncation process, demonstrating strong robustness across bit-width settings, and offering an easily implementable training scheme within existing quantization-aware frameworks. Our code is released at https://github.com/a2jinhee/TruncQuant.
Event-based Neural Spike Detection Using Spiking Neural Networks for Neuromorphic iBMI Systems
May 10, 2025Implantable brain-machine interfaces (iBMIs) are evolving to record from thousands of neurons wirelessly but face challenges in data bandwidth, power consumption, and implant size. We propose a novel Spiking Neural Network Spike Detector (SNN-SPD) that processes event-based neural data generated via delta modulation and pulse count modulation, converting signals into sparse events. By leveraging the temporal dynamics and inherent sparsity of spiking neural networks, our method improves spike detection performance while maintaining low computational overhead suitable for implantable devices. Our experimental results demonstrate that the proposed SNN-SPD achieves an accuracy of 95.72% at high noise levels (standard deviation 0.2), which is about 2% higher than the existing Artificial Neural Network Spike Detector (ANN-SPD). Moreover, SNN-SPD requires only 0.41% of the computation and about 26.62% of the weight parameters compared to ANN-SPD, with zero multiplications. This approach balances efficiency and performance, enabling effective data compression and power savings for next-generation iBMIs.
Column-wise Quantization of Weights and Partial Sums for Accurate and Efficient Compute-In-Memory Accelerators
Feb 11, 2025



Compute-in-memory (CIM) is an efficient method for implementing deep neural networks (DNNs) but suffers from substantial overhead from analog-to-digital converters (ADCs), especially as ADC precision increases. Low-precision ADCs can re- duce this overhead but introduce partial-sum quantization errors degrading accuracy. Additionally, low-bit weight constraints, im- posed by cell limitations and the need for multiple cells for higher- bit weights, present further challenges. While fine-grained partial- sum quantization has been studied to lower ADC resolution effectively, weight granularity, which limits overall partial-sum quantized accuracy, remains underexplored. This work addresses these challenges by aligning weight and partial-sum quantization granularities at the column-wise level. Our method improves accuracy while maintaining dequantization overhead, simplifies training by removing two-stage processes, and ensures robustness to memory cell variations via independent column-wise scale factors. We also propose an open-source CIM-oriented convolution framework to handle fine-grained weights and partial-sums effi- ciently, incorporating a novel tiling method and group convolution. Experimental results on ResNet-20 (CIFAR-10, CIFAR-100) and ResNet-18 (ImageNet) show accuracy improvements of 0.99%, 2.69%, and 1.01%, respectively, compared to the best-performing related works. Additionally, variation analysis reveals the robust- ness of our method against memory cell variations. These findings highlight the effectiveness of our quantization scheme in enhancing accuracy and robustness while maintaining hardware efficiency in CIM-based DNN implementations. Our code is available at https://github.com/jiyoonkm/ColumnQuant.
MEMHD: Memory-Efficient Multi-Centroid Hyperdimensional Computing for Fully-Utilized In-Memory Computing Architectures
Feb 11, 2025



The implementation of Hyperdimensional Computing (HDC) on In-Memory Computing (IMC) architectures faces significant challenges due to the mismatch between highdimensional vectors and IMC array sizes, leading to inefficient memory utilization and increased computation cycles. This paper presents MEMHD, a Memory-Efficient Multi-centroid HDC framework designed to address these challenges. MEMHD introduces a clustering-based initialization method and quantization aware iterative learning for multi-centroid associative memory. Through these approaches and its overall architecture, MEMHD achieves a significant reduction in memory requirements while maintaining or improving classification accuracy. Our approach achieves full utilization of IMC arrays and enables one-shot (or few-shot) associative search. Experimental results demonstrate that MEMHD outperforms state-of-the-art binary HDC models, achieving up to 13.69% higher accuracy with the same memory usage, or 13.25x more memory efficiency at the same accuracy level. Moreover, MEMHD reduces computation cycles by up to 80x and array usage by up to 71x compared to baseline IMC mapping methods when mapped to 128x128 IMC arrays, while significantly improving energy and computation cycle efficiency.
Low-Rank Compression for IMC Arrays
Feb 10, 2025



In this study, we address the challenge of low-rank model compression in the context of in-memory computing (IMC) architectures. Traditional pruning approaches, while effective in model size reduction, necessitate additional peripheral circuitry to manage complex dataflows and mitigate dislocation issues, leading to increased area and energy overheads. To circumvent these drawbacks, we propose leveraging low-rank compression techniques, which, unlike pruning, streamline the dataflow and seamlessly integrate with IMC architectures. However, low-rank compression presents its own set of challenges, namely i) suboptimal IMC array utilization and ii) compromised accuracy. To address these issues, we introduce a novel approach i) employing shift and duplicate kernel (SDK) mapping technique, which exploits idle IMC columns for parallel processing, and ii) group low-rank convolution, which mitigates the information imbalance in the decomposed matrices. Our experimental results demonstrate that our proposed method achieves up to 2.5x speedup or +20.9% accuracy boost over existing pruning techniques.
EPS: Efficient Patch Sampling for Video Overfitting in Deep Super-Resolution Model Training
Nov 25, 2024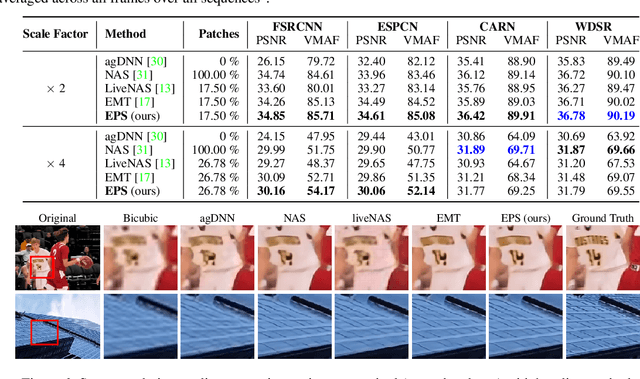
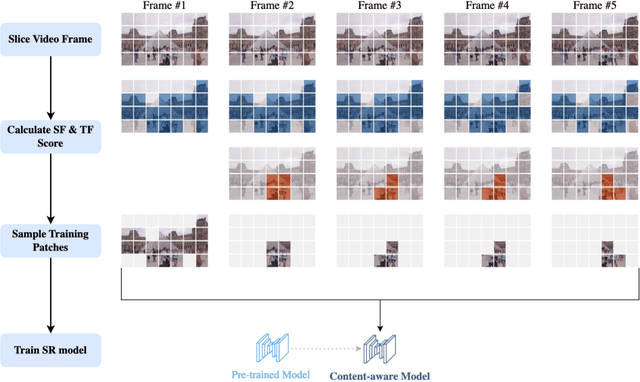

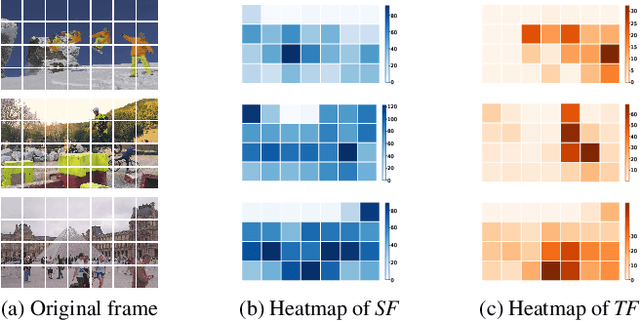
Leveraging the overfitting property of deep neural networks (DNNs) is trending in video delivery systems to enhance quality within bandwidth limits. Existing approaches transmit overfitted super-resolution (SR) model streams for low-resolution (LR) bitstreams, which are used to reconstruct high-resolution (HR) videos at the decoder. Although these approaches show promising results, the huge computational costs of training a large number of video frames limit their practical applications. To overcome this challenge, we propose an efficient patch sampling method named EPS for video SR network overfitting, which identifies the most valuable training patches from video frames. To this end, we first present two low-complexity Discrete Cosine Transform (DCT)-based spatial-temporal features to measure the complexity score of each patch directly. By analyzing the histogram distribution of these features, we then categorize all possible patches into different clusters and select training patches from the cluster with the highest spatial-temporal information. The number of sampled patches is adaptive based on the video content, addressing the trade-off between training complexity and efficiency. Our method reduces the number of patches for the training to 4% to 25%, depending on the resolution and number of clusters, while maintaining high video quality and significantly enhancing training efficiency. Compared to the state-of-the-art patch sampling method, EMT, our approach achieves an 83% decrease in overall run time.