 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandMCM: Multi-modal Point Cloud-based Correspondence State Space Model for 3D Hand Pose Estimation
Feb 02, 20263D hand pose estimation that involves accurate estimation of 3D human hand keypoint locations is crucial for many human-computer interaction applications such as augmented reality. However, this task poses significant challenges due to self-occlusion of the hands and occlusions caused by interactions with objects. In this paper, we propose HandMCM to address these challenges. Our HandMCM is a novel method based on the powerful state space model (Mamba). By incorporating modules for local information injection/filtering and correspondence modeling, the proposed correspondence Mamba effectively learns the highly dynamic kinematic topology of keypoints across various occlusion scenarios. Moreover, by integrating multi-modal image features, we enhance the robustness and representational capacity of the input, leading to more accurate hand pose estimation. Empirical evaluations on three benchmark datasets demonstrate that our model significantly outperforms current state-of-the-art methods, particularly in challenging scenarios involving severe occlusions. These results highlight the potential of our approach to advance the accuracy and reliability of 3D hand pose estimation in practical applications.
HandDAGT: A Denoising Adaptive Graph Transformer for 3D Hand Pose Estimation
Jul 30, 2024



The extraction of keypoint positions from input hand frames, known as 3D hand pose estimation, is crucial for various human-computer interaction applications. However, current approaches often struggle with the dynamic nature of self-occlusion of hands and intra-occlusion with interacting objects. To address this challenge, this paper proposes the Denoising Adaptive Graph Transformer, HandDAGT, for hand pose estimation. The proposed HandDAGT leverages a transformer structure to thoroughly explore effective geometric features from input patches. Additionally, it incorporates a novel attention mechanism to adaptively weigh the contribution of kinematic correspondence and local geometric features for the estimation of specific keypoints. This attribute enables the model to adaptively employ kinematic and local information based on the occlusion situation, enhancing its robustness and accuracy. Furthermore, we introduce a novel denoising training strategy aimed at improving the model's robust performance in the face of occlusion challenges. Experimental results show that the proposed model significantly outperforms the existing methods on four challenging hand pose benchmark datasets. Codes and pre-trained models are publicly available at https://github.com/cwc1260/HandDAGT.
HandDiff: 3D Hand Pose Estimation with Diffusion on Image-Point Cloud
Apr 04, 2024


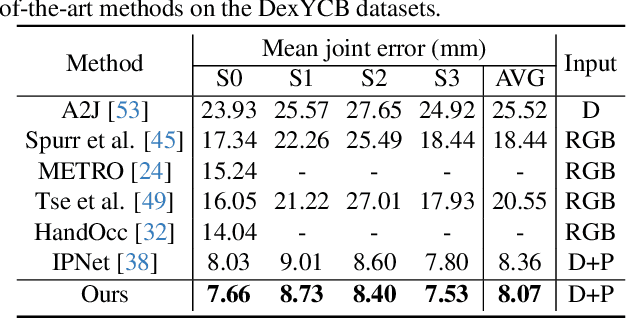
Extracting keypoint locations from input hand frames, known as 3D hand pose estimation, is a critical task in various human-computer interaction applications. Essentially, the 3D hand pose estimation can be regarded as a 3D point subset generative problem conditioned on input frames. Thanks to the recent significant progress on diffusion-based generative models, hand pose estimation can also benefit from the diffusion model to estimate keypoint locations with high quality. However, directly deploying the existing diffusion models to solve hand pose estimation is non-trivial, since they cannot achieve the complex permutation mapping and precise localization. Based on this motivation, this paper proposes HandDiff, a diffusion-based hand pose estimation model that iteratively denoises accurate hand pose conditioned on hand-shaped image-point clouds. In order to recover keypoint permutation and accurate location, we further introduce joint-wise condition and local detail condition. Experimental results demonstrate that the proposed HandDiff significantly outperforms the existing approaches on four challenging hand pose benchmark datasets. Codes and pre-trained models are publicly available at https://github.com/cwc1260/HandDiff.
Bi-PointFlowNet: Bidirectional Learning for Point Cloud Based Scene Flow Estimation
Jul 15, 2022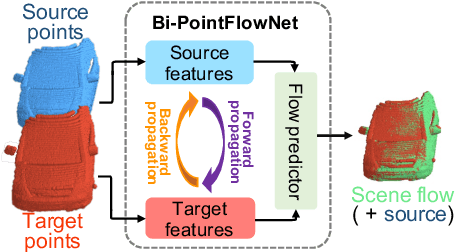
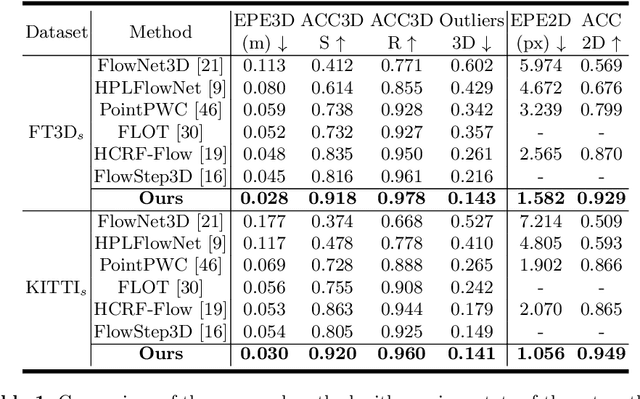
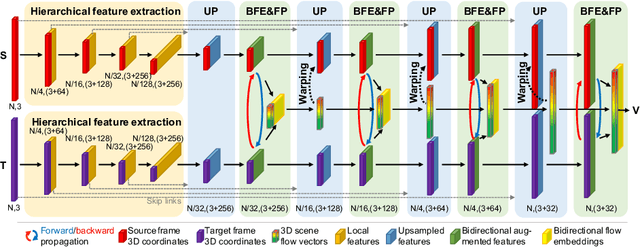
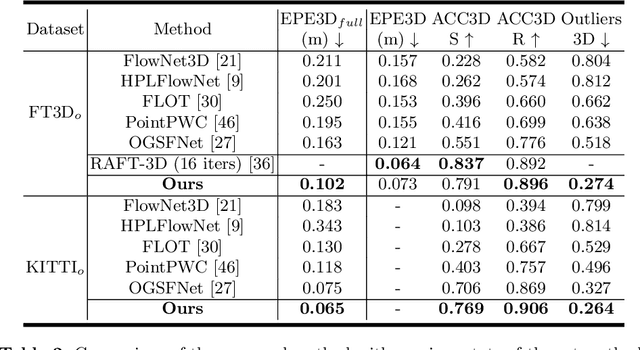
Scene flow estimation, which extracts point-wise motion between scenes, is becoming a crucial task in many computer vision tasks. However, all of the existing estimation methods utilize only the unidirectional features, restricting the accuracy and generality. This paper presents a novel scene flow estimation architecture using bidirectional flow embedding layers. The proposed bidirectional layer learns features along both forward and backward directions, enhancing the estimation performance. In addition, hierarchical feature extraction and warping improve the performance and reduce computational overhead. Experimental results show that the proposed architecture achieved a new state-of-the-art record by outperforming other approaches with large margin in both FlyingThings3D and KITTI benchmarks. Codes are available at https://github.com/cwc1260/BiFlow.
HandFoldingNet: A 3D Hand Pose Estimation Network Using Multiscale-Feature Guided Folding of a 2D Hand Skeleton
Aug 12, 2021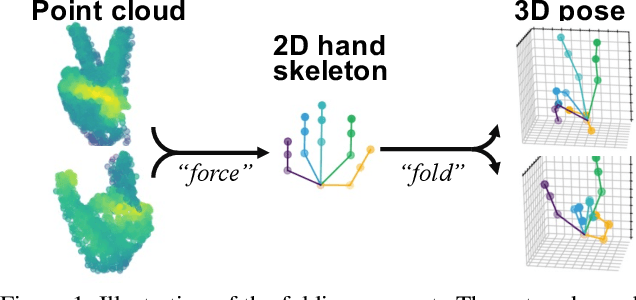
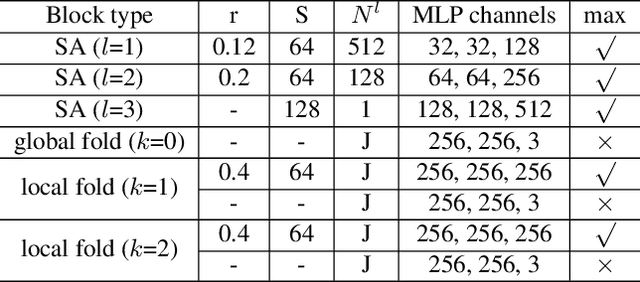
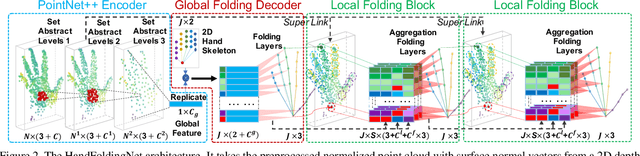
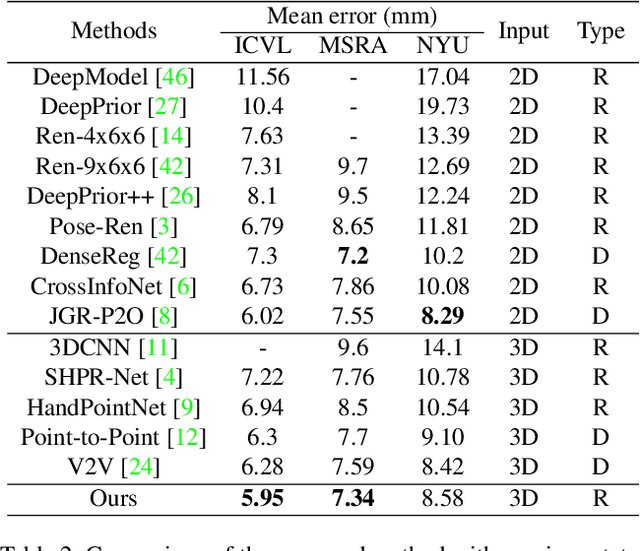
With increasing applications of 3D hand pose estimation in various human-computer interaction applications, convolution neural networks (CNNs) based estimation models have been actively explored. However, the existing models require complex architectures or redundant computational resources to trade with the acceptable accuracy. To tackle this limitation, this paper proposes HandFoldingNet, an accurate and efficient hand pose estimator that regresses the hand joint locations from the normalized 3D hand point cloud input. The proposed model utilizes a folding-based decoder that folds a given 2D hand skeleton into the corresponding joint coordinates. For higher estimation accuracy, folding is guided by multi-scale features, which include both global and joint-wise local features. Experimental results show that the proposed model outperforms the existing methods on three hand pose benchmark datasets with the lowest model parameter requirement. Code is available at https://github.com/cwc1260/HandFold.