 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuiding What Not to Generate: Automated Negative Prompting for Text-Image Alignment
Dec 11, 2025Despite substantial progress in text-to-image generation, achieving precise text-image alignment remains challenging, particularly for prompts with rich compositional structure or imaginative elements. To address this, we introduce Negative Prompting for Image Correction (NPC), an automated pipeline that improves alignment by identifying and applying negative prompts that suppress unintended content. We begin by analyzing cross-attention patterns to explain why both targeted negatives-those directly tied to the prompt's alignment error-and untargeted negatives-tokens unrelated to the prompt but present in the generated image-can enhance alignment. To discover useful negatives, NPC generates candidate prompts using a verifier-captioner-proposer framework and ranks them with a salient text-space score, enabling effective selection without requiring additional image synthesis. On GenEval++ and Imagine-Bench, NPC outperforms strong baselines, achieving 0.571 vs. 0.371 on GenEval++ and the best overall performance on Imagine-Bench. By guiding what not to generate, NPC provides a principled, fully automated route to stronger text-image alignment in diffusion models. Code is released at https://github.com/wiarae/NPC.
DefectFill: Realistic Defect Generation with Inpainting Diffusion Model for Visual Inspection
Mar 18, 2025Developing effective visual inspection models remains challenging due to the scarcity of defect data. While image generation models have been used to synthesize defect images, producing highly realistic defects remains difficult. We propose DefectFill, a novel method for realistic defect generation that requires only a few reference defect images. It leverages a fine-tuned inpainting diffusion model, optimized with our custom loss functions incorporating defect, object, and attention terms. It enables precise capture of detailed, localized defect features and their seamless integration into defect-free objects. Additionally, our Low-Fidelity Selection method further enhances the defect sample quality. Experiments show that DefectFill generates high-quality defect images, enabling visual inspection models to achieve state-of-the-art performance on the MVTec AD dataset.
Visual Attention Never Fades: Selective Progressive Attention ReCalibration for Detailed Image Captioning in Multimodal Large Language Models
Feb 03, 2025Detailed image captioning is essential for tasks like data generation and aiding visually impaired individuals. High-quality captions require a balance between precision and recall, which remains challenging for current multimodal large language models (MLLMs). In this work, we hypothesize that this limitation stems from weakening and increasingly noisy visual attention as responses lengthen. To address this issue, we propose SPARC (Selective Progressive Attention ReCalibration), a training-free method that enhances the contribution of visual tokens during decoding. SPARC is founded on three key observations: (1) increasing the influence of all visual tokens reduces recall; thus, SPARC selectively amplifies visual tokens; (2) as captions lengthen, visual attention becomes noisier, so SPARC identifies critical visual tokens by leveraging attention differences across time steps; (3) as visual attention gradually weakens, SPARC reinforces it to preserve its influence. Our experiments, incorporating both automated and human evaluations, demonstrate that existing methods improve the precision of MLLMs at the cost of recall. In contrast, our proposed method enhances both precision and recall with minimal computational overhead.
Superpixel Tokenization for Vision Transformers: Preserving Semantic Integrity in Visual Tokens
Dec 06, 2024



Transformers, a groundbreaking architecture proposed for Natural Language Processing (NLP), have also achieved remarkable success in Computer Vision. A cornerstone of their success lies in the attention mechanism, which models relationships among tokens. While the tokenization process in NLP inherently ensures that a single token does not contain multiple semantics, the tokenization of Vision Transformer (ViT) utilizes tokens from uniformly partitioned square image patches, which may result in an arbitrary mixing of visual concepts in a token. In this work, we propose to substitute the grid-based tokenization in ViT with superpixel tokenization, which employs superpixels to generate a token that encapsulates a sole visual concept. Unfortunately, the diverse shapes, sizes, and locations of superpixels make integrating superpixels into ViT tokenization rather challenging. Our tokenization pipeline, comprised of pre-aggregate extraction and superpixel-aware aggregation, overcomes the challenges that arise in superpixel tokenization. Extensive experiments demonstrate that our approach, which exhibits strong compatibility with existing frameworks, enhances the accuracy and robustness of ViT on various downstream tasks.
Interpretable Language Modeling via Induction-head Ngram Models
Oct 31, 2024


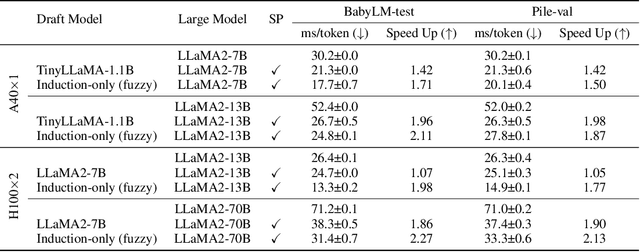
Recent large language models (LLMs) have excelled across a wide range of tasks, but their use in high-stakes and compute-limited settings has intensified the demand for interpretability and efficiency. We address this need by proposing Induction-head ngram models (Induction-Gram), a method that builds an efficient, interpretable LM by bolstering modern ngram models with a hand-engineered "induction head". This induction head uses a custom neural similarity metric to efficiently search the model's input context for potential next-word completions. This process enables Induction-Gram to provide ngram-level grounding for each generated token. Moreover, experiments show that this simple method significantly improves next-word prediction over baseline interpretable models (up to 26%p) and can be used to speed up LLM inference for large models through speculative decoding. We further study Induction-Gram in a natural-language neuroscience setting, where the goal is to predict the next fMRI response in a sequence. It again provides a significant improvement over interpretable models (20% relative increase in the correlation of predicted fMRI responses), potentially enabling deeper scientific investigation of language selectivity in the brain. The code is available at https://github.com/ejkim47/induction-gram.
Semantic Token Reweighting for Interpretable and Controllable Text Embeddings in CLIP
Oct 11, 2024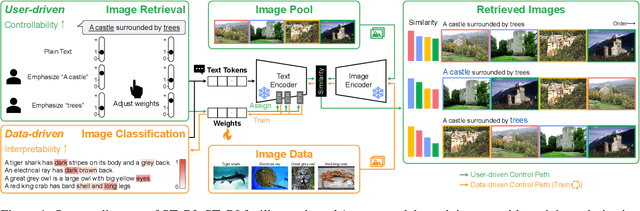
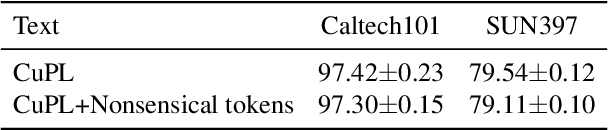

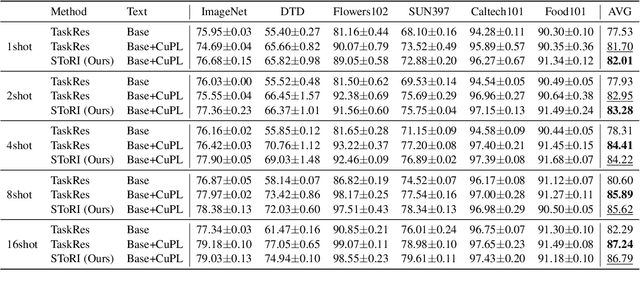
A text encoder within Vision-Language Models (VLMs) like CLIP plays a crucial role in translating textual input into an embedding space shared with images, thereby facilitating the interpretative analysis of vision tasks through natural language. Despite the varying significance of different textual elements within a sentence depending on the context, efforts to account for variation of importance in constructing text embeddings have been lacking. We propose a framework of Semantic Token Reweighting to build Interpretable text embeddings (SToRI), which incorporates controllability as well. SToRI refines the text encoding process in CLIP by differentially weighting semantic elements based on contextual importance, enabling finer control over emphasis responsive to data-driven insights and user preferences. The efficacy of SToRI is demonstrated through comprehensive experiments on few-shot image classification and image retrieval tailored to user preferences.
Unlocking Intrinsic Fairness in Stable Diffusion
Aug 22, 2024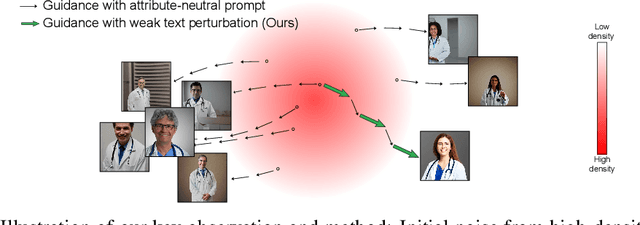



Recent text-to-image models like Stable Diffusion produce photo-realistic images but often show demographic biases. Previous debiasing methods focused on training-based approaches, failing to explore the root causes of bias and overlooking Stable Diffusion's potential for unbiased image generation. In this paper, we demonstrate that Stable Diffusion inherently possesses fairness, which can be unlocked to achieve debiased outputs. Through carefully designed experiments, we identify the excessive bonding between text prompts and the diffusion process as a key source of bias. To address this, we propose a novel approach that perturbs text conditions to unleash Stable Diffusion's intrinsic fairness. Our method effectively mitigates bias without additional tuning, while preserving image-text alignment and image quality.
HandDAGT: A Denoising Adaptive Graph Transformer for 3D Hand Pose Estimation
Jul 30, 2024



The extraction of keypoint positions from input hand frames, known as 3D hand pose estimation, is crucial for various human-computer interaction applications. However, current approaches often struggle with the dynamic nature of self-occlusion of hands and intra-occlusion with interacting objects. To address this challenge, this paper proposes the Denoising Adaptive Graph Transformer, HandDAGT, for hand pose estimation. The proposed HandDAGT leverages a transformer structure to thoroughly explore effective geometric features from input patches. Additionally, it incorporates a novel attention mechanism to adaptively weigh the contribution of kinematic correspondence and local geometric features for the estimation of specific keypoints. This attribute enables the model to adaptively employ kinematic and local information based on the occlusion situation, enhancing its robustness and accuracy. Furthermore, we introduce a novel denoising training strategy aimed at improving the model's robust performance in the face of occlusion challenges. Experimental results show that the proposed model significantly outperforms the existing methods on four challenging hand pose benchmark datasets. Codes and pre-trained models are publicly available at https://github.com/cwc1260/HandDAGT.
Aligning Large Language Models for Enhancing Psychiatric Interviews through Symptom Delineation and Summarization
Mar 26, 2024Recent advancements in Large Language Models (LLMs) have accelerated their usage in various domains. Given the fact that psychiatric interviews are goal-oriented and structured dialogues between the professional interviewer and the interviewee, it is one of the most underexplored areas where LLMs can contribute substantial value. Here, we explore the use of LLMs for enhancing psychiatric interviews, by analyzing counseling data from North Korean defectors with traumatic events and mental health issues. Specifically, we investigate whether LLMs can (1) delineate the part of the conversation that suggests psychiatric symptoms and name the symptoms, and (2) summarize stressors and symptoms, based on the interview dialogue transcript. Here, the transcript data was labeled by mental health experts for training and evaluation of LLMs. Our experimental results show that appropriately prompted LLMs can achieve high performance on both the symptom delineation task and the summarization task. This research contributes to the nascent field of applying LLMs to psychiatric interview and demonstrates their potential effectiveness in aiding mental health practitioners.
Improving Visual Prompt Tuning for Self-supervised Vision Transformers
Jun 08, 2023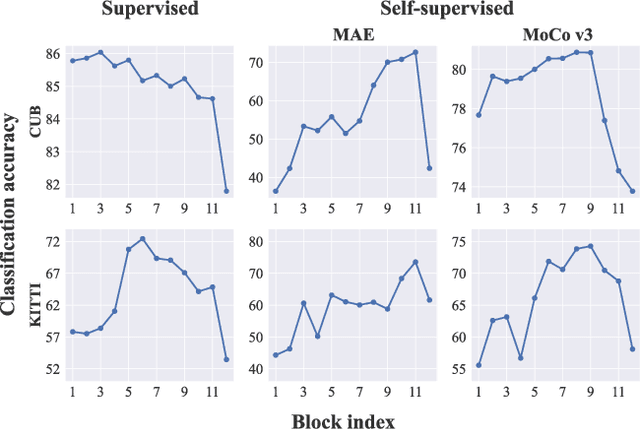
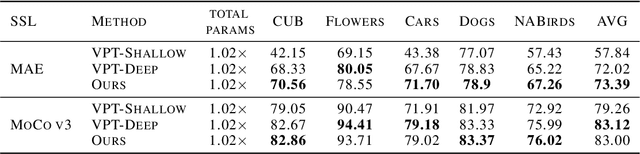
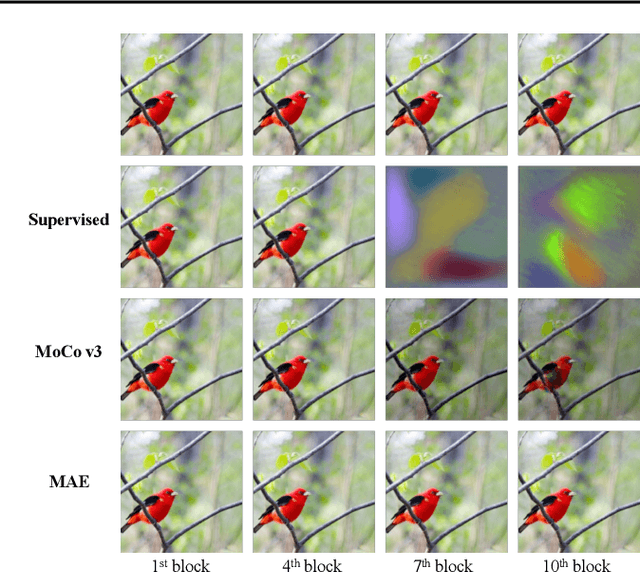
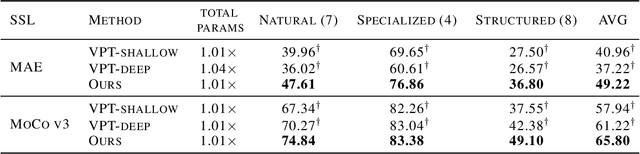
Visual Prompt Tuning (VPT) is an effective tuning method for adapting pretrained Vision Transformers (ViTs) to downstream tasks. It leverages extra learnable tokens, known as prompts, which steer the frozen pretrained ViTs. Although VPT has demonstrated its applicability with supervised vision transformers, it often underperforms with self-supervised ones. Through empirical observations, we deduce that the effectiveness of VPT hinges largely on the ViT blocks with which the prompt tokens interact. Specifically, VPT shows improved performance on image classification tasks for MAE and MoCo v3 when the prompt tokens are inserted into later blocks rather than the first block. These observations suggest that there exists an optimal location of blocks for the insertion of prompt tokens. Unfortunately, identifying the optimal blocks for prompts within each self-supervised ViT for diverse future scenarios is a costly process. To mitigate this problem, we propose a simple yet effective method that learns a gate for each ViT block to adjust its intervention into the prompt tokens. With our method, prompt tokens are selectively influenced by blocks that require steering for task adaptation. Our method outperforms VPT variants in FGVC and VTAB image classification and ADE20K semantic segmentation. The code is available at https://github.com/ryongithub/GatedPromptTuning.