 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFeedback Adaptation for Retrieval-Augmented Generation
Apr 08, 2026Retrieval-Augmented Generation (RAG) systems are typically evaluated under static assumptions, despite being frequently corrected through user or expert feedback in deployment. Existing evaluation protocols focus on overall accuracy and fail to capture how systems adapt after feedback is introduced. We introduce feedback adaptation as a problem setting for RAG systems, which asks how effectively and how quickly corrective feedback propagates to future queries. To make this behavior measurable, we propose two evaluation axes: correction lag, which captures the delay between feedback provision and behavioral change, and post-feedback performance, which measures reliability on semantically related queries after feedback. Using these metrics, we show that training-based approaches exhibit a trade-off between delayed correction and reliable adaptation. We further propose PatchRAG, a minimal inference-time instantiation that incorporates feedback without retraining, demonstrating immediate correction and strong post-feedback generalization under the proposed evaluation. Our results highlight feedback adaptation as a previously overlooked dimension of RAG system behavior in interactive settings.
Chain-of-Rank: Enhancing Large Language Models for Domain-Specific RAG in Edge Device
Feb 21, 2025



Retrieval-augmented generation (RAG) with large language models (LLMs) is especially valuable in specialized domains, where precision is critical. To more specialize the LLMs into a target domain, domain-specific RAG has recently been developed by allowing the LLM to access the target domain early via finetuning. The domain-specific RAG makes more sense in resource-constrained environments like edge devices, as they should perform a specific task (e.g. personalization) reliably using only small-scale LLMs. While the domain-specific RAG is well-aligned with edge devices in this respect, it often relies on widely-used reasoning techniques like chain-of-thought (CoT). The reasoning step is useful to understand the given external knowledge, and yet it is computationally expensive and difficult for small-scale LLMs to learn it. Tackling this, we propose the Chain of Rank (CoR) which shifts the focus from intricate lengthy reasoning to simple ranking of the reliability of input external documents. Then, CoR reduces computational complexity while maintaining high accuracy, making it particularly suited for resource-constrained environments. We attain the state-of-the-art (SOTA) results in benchmarks, and analyze its efficacy.
Unlocking Transfer Learning for Open-World Few-Shot Recognition
Nov 15, 2024Few-Shot Open-Set Recognition (FSOSR) targets a critical real-world challenge, aiming to categorize inputs into known categories, termed closed-set classes, while identifying open-set inputs that fall outside these classes. Although transfer learning where a model is tuned to a given few-shot task has become a prominent paradigm in closed-world, we observe that it fails to expand to open-world. To unlock this challenge, we propose a two-stage method which consists of open-set aware meta-learning with open-set free transfer learning. In the open-set aware meta-learning stage, a model is trained to establish a metric space that serves as a beneficial starting point for the subsequent stage. During the open-set free transfer learning stage, the model is further adapted to a specific target task through transfer learning. Additionally, we introduce a strategy to simulate open-set examples by modifying the training dataset or generating pseudo open-set examples. The proposed method achieves state-of-the-art performance on two widely recognized benchmarks, miniImageNet and tieredImageNet, with only a 1.5\% increase in training effort. Our work demonstrates the effectiveness of transfer learning in FSOSR.
Semantic Token Reweighting for Interpretable and Controllable Text Embeddings in CLIP
Oct 11, 2024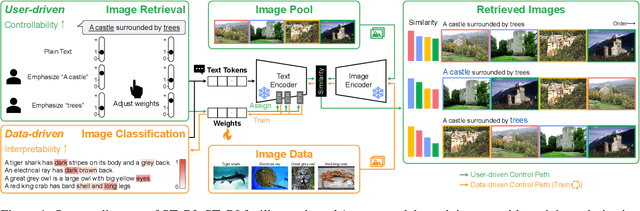
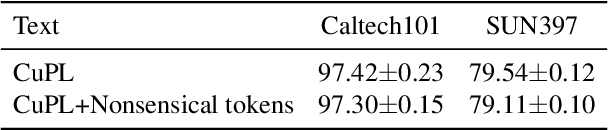

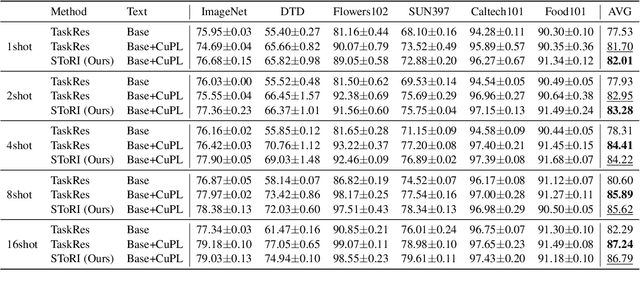
A text encoder within Vision-Language Models (VLMs) like CLIP plays a crucial role in translating textual input into an embedding space shared with images, thereby facilitating the interpretative analysis of vision tasks through natural language. Despite the varying significance of different textual elements within a sentence depending on the context, efforts to account for variation of importance in constructing text embeddings have been lacking. We propose a framework of Semantic Token Reweighting to build Interpretable text embeddings (SToRI), which incorporates controllability as well. SToRI refines the text encoding process in CLIP by differentially weighting semantic elements based on contextual importance, enabling finer control over emphasis responsive to data-driven insights and user preferences. The efficacy of SToRI is demonstrated through comprehensive experiments on few-shot image classification and image retrieval tailored to user preferences.
InfiniPot: Infinite Context Processing on Memory-Constrained LLMs
Oct 02, 2024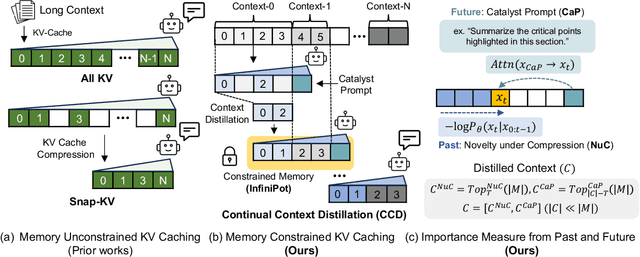
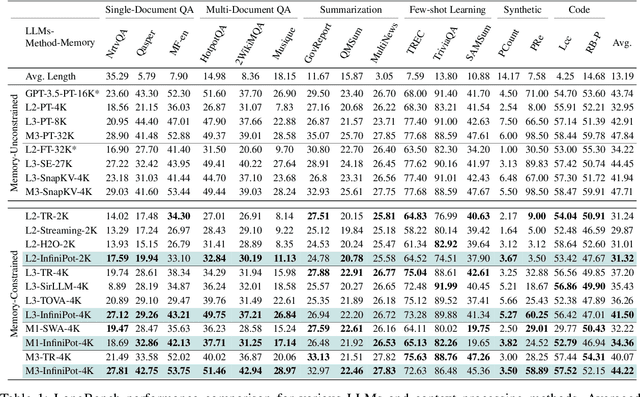
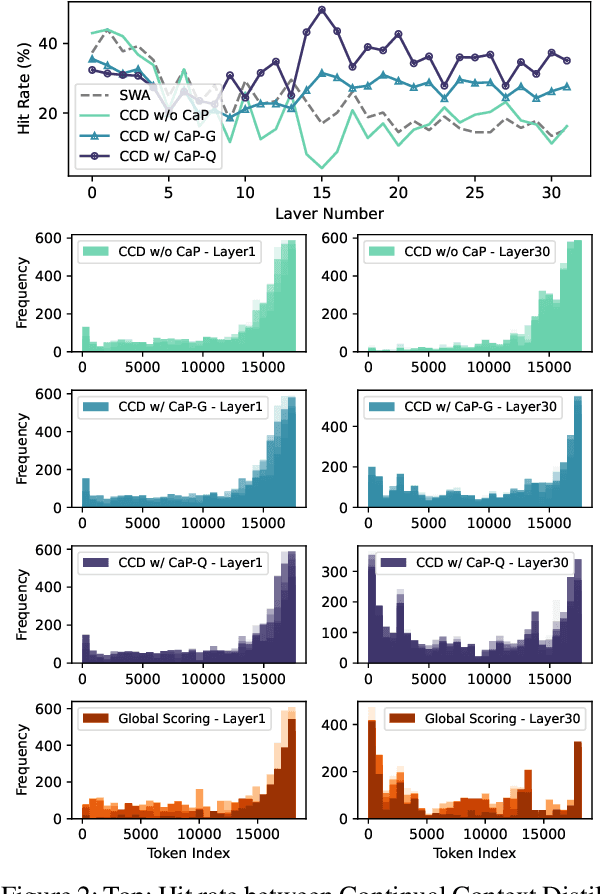
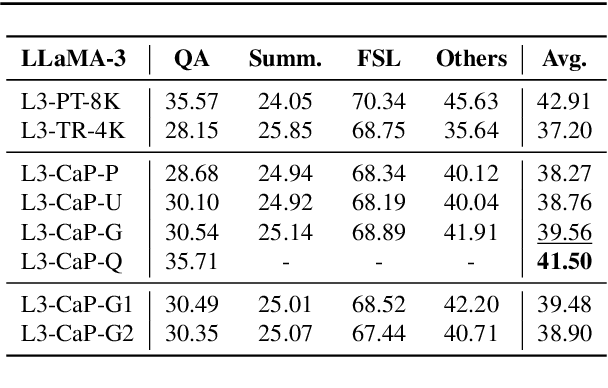
Handling long input contexts remains a significant challenge for Large Language Models (LLMs), particularly in resource-constrained environments such as mobile devices. Our work aims to address this limitation by introducing InfiniPot, a novel KV cache control framework designed to enable pre-trained LLMs to manage extensive sequences within fixed memory constraints efficiently, without requiring additional training. InfiniPot leverages Continual Context Distillation (CCD), an iterative process that compresses and retains essential information through novel importance metrics, effectively maintaining critical data even without access to future context. Our comprehensive evaluations indicate that InfiniPot significantly outperforms models trained for long contexts in various NLP tasks, establishing its efficacy and versatility. This work represents a substantial advancement toward making LLMs applicable to a broader range of real-world scenarios.
Feature Diversification and Adaptation for Federated Domain Generalization
Jul 11, 2024



Federated learning, a distributed learning paradigm, utilizes multiple clients to build a robust global model. In real-world applications, local clients often operate within their limited domains, leading to a `domain shift' across clients. Privacy concerns limit each client's learning to its own domain data, which increase the risk of overfitting. Moreover, the process of aggregating models trained on own limited domain can be potentially lead to a significant degradation in the global model performance. To deal with these challenges, we introduce the concept of federated feature diversification. Each client diversifies the own limited domain data by leveraging global feature statistics, i.e., the aggregated average statistics over all participating clients, shared through the global model's parameters. This data diversification helps local models to learn client-invariant representations while preserving privacy. Our resultant global model shows robust performance on unseen test domain data. To enhance performance further, we develop an instance-adaptive inference approach tailored for test domain data. Our proposed instance feature adapter dynamically adjusts feature statistics to align with the test input, thereby reducing the domain gap between the test and training domains. We show that our method achieves state-of-the-art performance on several domain generalization benchmarks within a federated learning setting.
Crayon: Customized On-Device LLM via Instant Adapter Blending and Edge-Server Hybrid Inference
Jun 11, 2024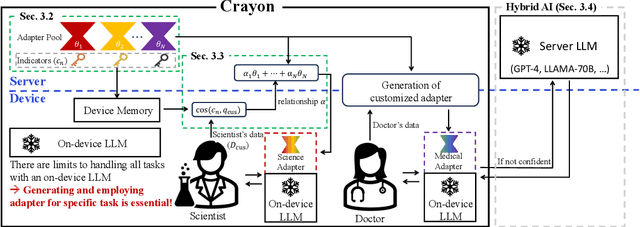
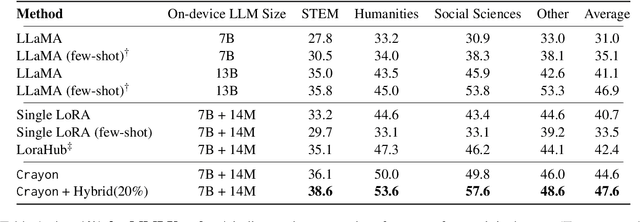
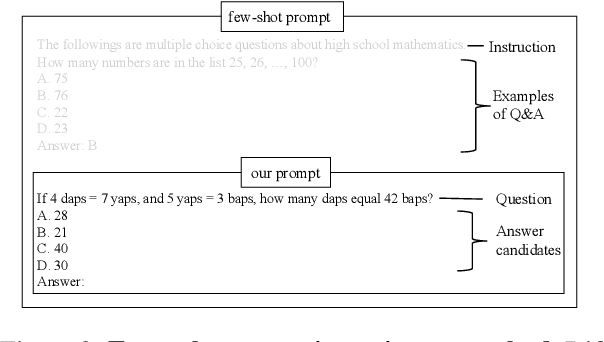
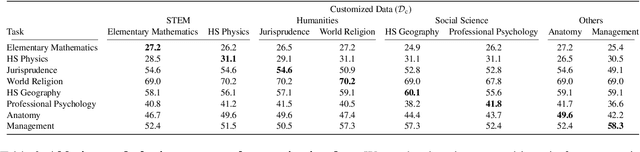
The customization of large language models (LLMs) for user-specified tasks gets important. However, maintaining all the customized LLMs on cloud servers incurs substantial memory and computational overheads, and uploading user data can also lead to privacy concerns. On-device LLMs can offer a promising solution by mitigating these issues. Yet, the performance of on-device LLMs is inherently constrained by the limitations of small-scaled models. To overcome these restrictions, we first propose Crayon, a novel approach for on-device LLM customization. Crayon begins by constructing a pool of diverse base adapters, and then we instantly blend them into a customized adapter without extra training. In addition, we develop a device-server hybrid inference strategy, which deftly allocates more demanding queries or non-customized tasks to a larger, more capable LLM on a server. This ensures optimal performance without sacrificing the benefits of on-device customization. We carefully craft a novel benchmark from multiple question-answer datasets, and show the efficacy of our method in the LLM customization.
Knowledge Distillation from Non-streaming to Streaming ASR Encoder using Auxiliary Non-streaming Layer
Aug 31, 2023Streaming automatic speech recognition (ASR) models are restricted from accessing future context, which results in worse performance compared to the non-streaming models. To improve the performance of streaming ASR, knowledge distillation (KD) from the non-streaming to streaming model has been studied, mainly focusing on aligning the output token probabilities. In this paper, we propose a layer-to-layer KD from the teacher encoder to the student encoder. To ensure that features are extracted using the same context, we insert auxiliary non-streaming branches to the student and perform KD from the non-streaming teacher layer to the non-streaming auxiliary layer. We design a special KD loss that leverages the autoregressive predictive coding (APC) mechanism to encourage the streaming model to predict unseen future contexts. Experimental results show that the proposed method can significantly reduce the word error rate compared to previous token probability distillation methods.
Improving Small Footprint Few-shot Keyword Spotting with Supervision on Auxiliary Data
Aug 31, 2023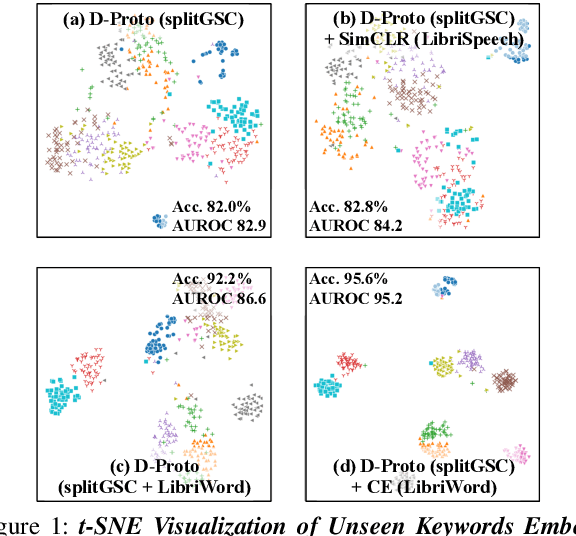
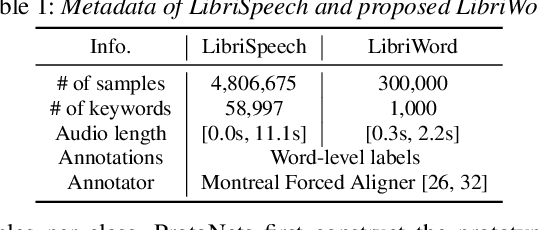
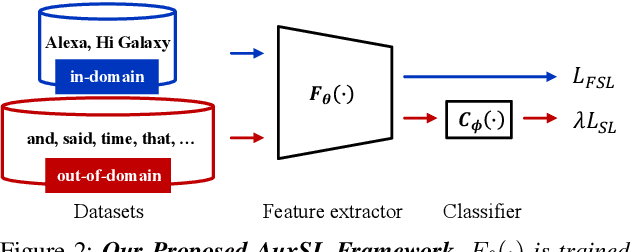
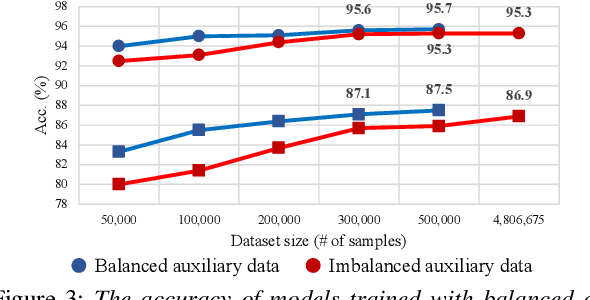
Few-shot keyword spotting (FS-KWS) models usually require large-scale annotated datasets to generalize to unseen target keywords. However, existing KWS datasets are limited in scale and gathering keyword-like labeled data is costly undertaking. To mitigate this issue, we propose a framework that uses easily collectible, unlabeled reading speech data as an auxiliary source. Self-supervised learning has been widely adopted for learning representations from unlabeled data; however, it is known to be suitable for large models with enough capacity and is not practical for training a small footprint FS-KWS model. Instead, we automatically annotate and filter the data to construct a keyword-like dataset, LibriWord, enabling supervision on auxiliary data. We then adopt multi-task learning that helps the model to enhance the representation power from out-of-domain auxiliary data. Our method notably improves the performance over competitive methods in the FS-KWS benchmark.
Scalable Weight Reparametrization for Efficient Transfer Learning
Feb 26, 2023This paper proposes a novel, efficient transfer learning method, called Scalable Weight Reparametrization (SWR) that is efficient and effective for multiple downstream tasks. Efficient transfer learning involves utilizing a pre-trained model trained on a larger dataset and repurposing it for downstream tasks with the aim of maximizing the reuse of the pre-trained model. However, previous works have led to an increase in updated parameters and task-specific modules, resulting in more computations, especially for tiny models. Additionally, there has been no practical consideration for controlling the number of updated parameters. To address these issues, we suggest learning a policy network that can decide where to reparametrize the pre-trained model, while adhering to a given constraint for the number of updated parameters. The policy network is only used during the transfer learning process and not afterward. As a result, our approach attains state-of-the-art performance in a proposed multi-lingual keyword spotting and a standard benchmark, ImageNet-to-Sketch, while requiring zero additional computations and significantly fewer additional parameters.