 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Straight, Stop Smart: Structured Reasoning for Efficient Multi-Hop RAG
Oct 22, 2025Multi-hop retrieval-augmented generation (RAG) is a promising strategy for complex reasoning, yet existing iterative prompting approaches remain inefficient. They often regenerate predictable token sequences at every step and rely on stochastic stopping, leading to excessive token usage and unstable termination. We propose TSSS (Think Straight, Stop Smart), a structured multi-hop RAG framework designed for efficiency. TSSS introduces (i) a template-based reasoning that caches recurring prefixes and anchors sub-queries to the main question, reducing token generation cost while promoting stable reasoning, and (ii) a retriever-based terminator, which deterministically halts reasoning once additional sub-queries collapse into repetition. This separation of structured reasoning and termination control enables both faster inference and more reliable answers. On HotpotQA, 2WikiMultiHop, and MuSiQue, TSSS achieves state-of-the-art accuracy and competitive efficiency among RAG-CoT approaches, highlighting its effectiveness in efficiency-constrained scenarios such as on-device inference.
Chain-of-Rank: Enhancing Large Language Models for Domain-Specific RAG in Edge Device
Feb 21, 2025



Retrieval-augmented generation (RAG) with large language models (LLMs) is especially valuable in specialized domains, where precision is critical. To more specialize the LLMs into a target domain, domain-specific RAG has recently been developed by allowing the LLM to access the target domain early via finetuning. The domain-specific RAG makes more sense in resource-constrained environments like edge devices, as they should perform a specific task (e.g. personalization) reliably using only small-scale LLMs. While the domain-specific RAG is well-aligned with edge devices in this respect, it often relies on widely-used reasoning techniques like chain-of-thought (CoT). The reasoning step is useful to understand the given external knowledge, and yet it is computationally expensive and difficult for small-scale LLMs to learn it. Tackling this, we propose the Chain of Rank (CoR) which shifts the focus from intricate lengthy reasoning to simple ranking of the reliability of input external documents. Then, CoR reduces computational complexity while maintaining high accuracy, making it particularly suited for resource-constrained environments. We attain the state-of-the-art (SOTA) results in benchmarks, and analyze its efficacy.
Feature Diversification and Adaptation for Federated Domain Generalization
Jul 11, 2024



Federated learning, a distributed learning paradigm, utilizes multiple clients to build a robust global model. In real-world applications, local clients often operate within their limited domains, leading to a `domain shift' across clients. Privacy concerns limit each client's learning to its own domain data, which increase the risk of overfitting. Moreover, the process of aggregating models trained on own limited domain can be potentially lead to a significant degradation in the global model performance. To deal with these challenges, we introduce the concept of federated feature diversification. Each client diversifies the own limited domain data by leveraging global feature statistics, i.e., the aggregated average statistics over all participating clients, shared through the global model's parameters. This data diversification helps local models to learn client-invariant representations while preserving privacy. Our resultant global model shows robust performance on unseen test domain data. To enhance performance further, we develop an instance-adaptive inference approach tailored for test domain data. Our proposed instance feature adapter dynamically adjusts feature statistics to align with the test input, thereby reducing the domain gap between the test and training domains. We show that our method achieves state-of-the-art performance on several domain generalization benchmarks within a federated learning setting.
Crayon: Customized On-Device LLM via Instant Adapter Blending and Edge-Server Hybrid Inference
Jun 11, 2024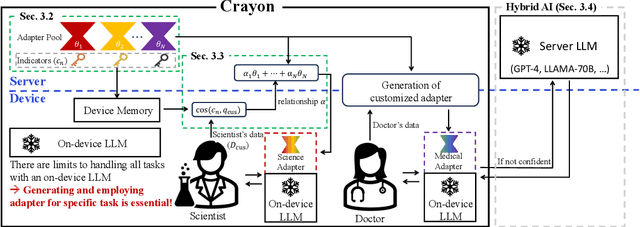
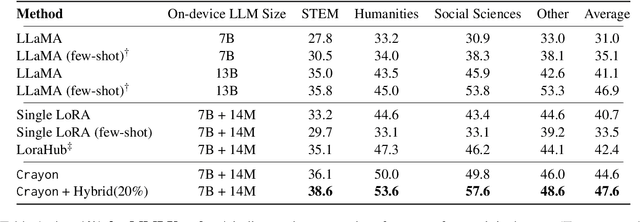
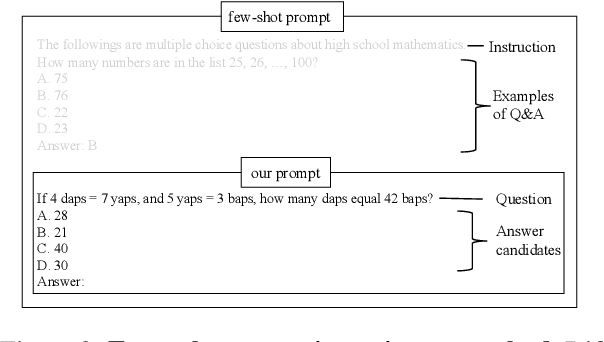
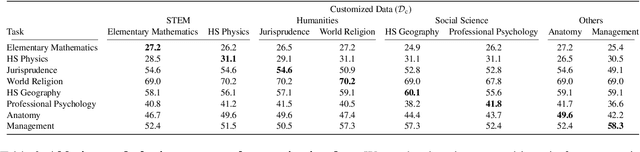
The customization of large language models (LLMs) for user-specified tasks gets important. However, maintaining all the customized LLMs on cloud servers incurs substantial memory and computational overheads, and uploading user data can also lead to privacy concerns. On-device LLMs can offer a promising solution by mitigating these issues. Yet, the performance of on-device LLMs is inherently constrained by the limitations of small-scaled models. To overcome these restrictions, we first propose Crayon, a novel approach for on-device LLM customization. Crayon begins by constructing a pool of diverse base adapters, and then we instantly blend them into a customized adapter without extra training. In addition, we develop a device-server hybrid inference strategy, which deftly allocates more demanding queries or non-customized tasks to a larger, more capable LLM on a server. This ensures optimal performance without sacrificing the benefits of on-device customization. We carefully craft a novel benchmark from multiple question-answer datasets, and show the efficacy of our method in the LLM customization.
Improving Small Footprint Few-shot Keyword Spotting with Supervision on Auxiliary Data
Aug 31, 2023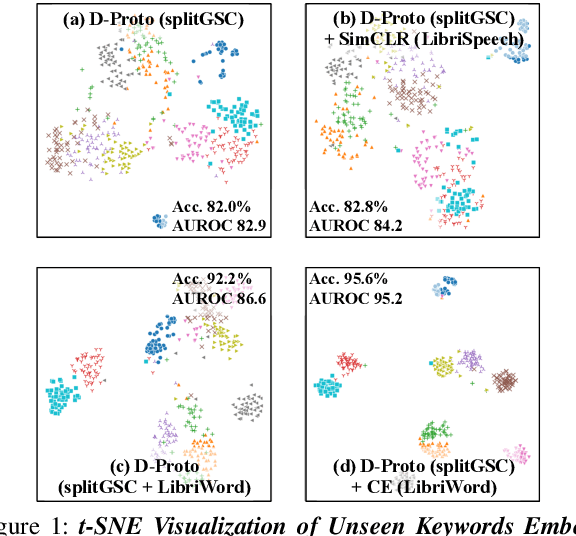
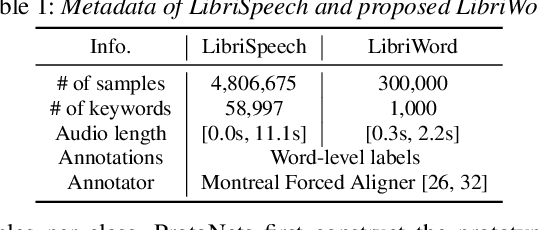
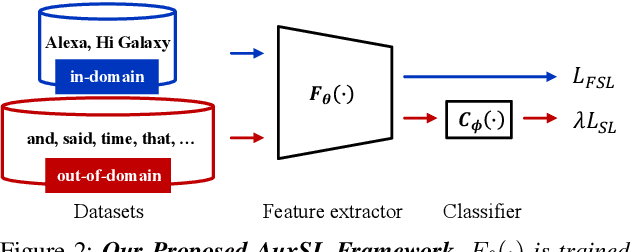
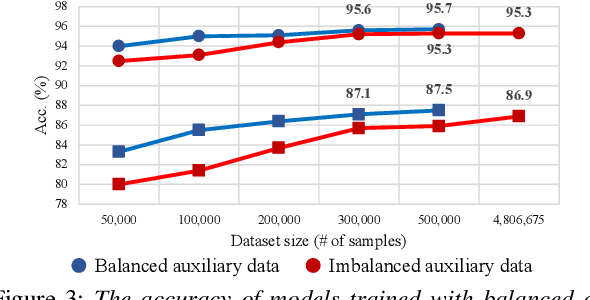
Few-shot keyword spotting (FS-KWS) models usually require large-scale annotated datasets to generalize to unseen target keywords. However, existing KWS datasets are limited in scale and gathering keyword-like labeled data is costly undertaking. To mitigate this issue, we propose a framework that uses easily collectible, unlabeled reading speech data as an auxiliary source. Self-supervised learning has been widely adopted for learning representations from unlabeled data; however, it is known to be suitable for large models with enough capacity and is not practical for training a small footprint FS-KWS model. Instead, we automatically annotate and filter the data to construct a keyword-like dataset, LibriWord, enabling supervision on auxiliary data. We then adopt multi-task learning that helps the model to enhance the representation power from out-of-domain auxiliary data. Our method notably improves the performance over competitive methods in the FS-KWS benchmark.
Label Shift Adapter for Test-Time Adaptation under Covariate and Label Shifts
Aug 17, 2023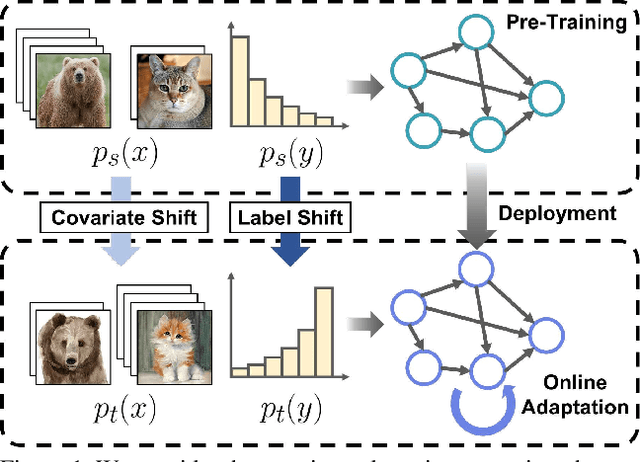
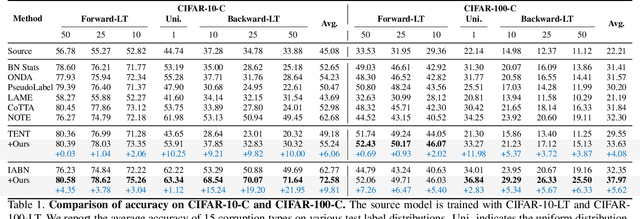
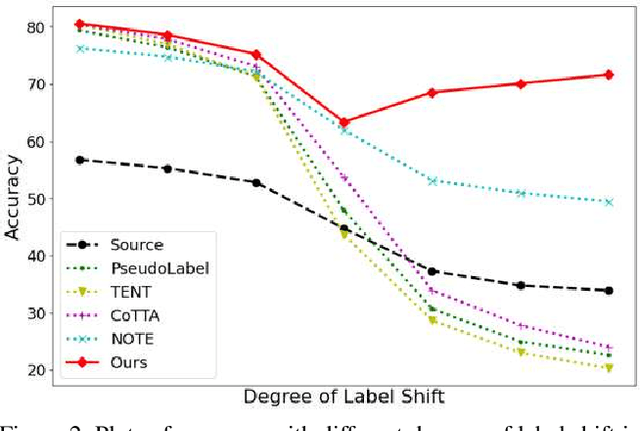
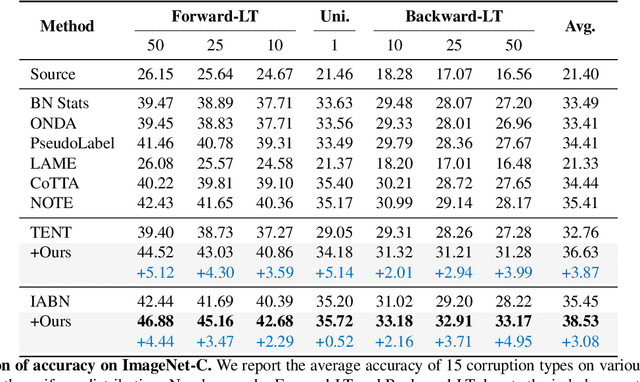
Test-time adaptation (TTA) aims to adapt a pre-trained model to the target domain in a batch-by-batch manner during inference. While label distributions often exhibit imbalances in real-world scenarios, most previous TTA approaches typically assume that both source and target domain datasets have balanced label distribution. Due to the fact that certain classes appear more frequently in certain domains (e.g., buildings in cities, trees in forests), it is natural that the label distribution shifts as the domain changes. However, we discover that the majority of existing TTA methods fail to address the coexistence of covariate and label shifts. To tackle this challenge, we propose a novel label shift adapter that can be incorporated into existing TTA approaches to deal with label shifts during the TTA process effectively. Specifically, we estimate the label distribution of the target domain to feed it into the label shift adapter. Subsequently, the label shift adapter produces optimal parameters for the target label distribution. By predicting only the parameters for a part of the pre-trained source model, our approach is computationally efficient and can be easily applied, regardless of the model architectures. Through extensive experiments, we demonstrate that integrating our strategy with TTA approaches leads to substantial performance improvements under the joint presence of label and covariate shifts.
Progressive Random Convolutions for Single Domain Generalization
Apr 02, 2023Single domain generalization aims to train a generalizable model with only one source domain to perform well on arbitrary unseen target domains. Image augmentation based on Random Convolutions (RandConv), consisting of one convolution layer randomly initialized for each mini-batch, enables the model to learn generalizable visual representations by distorting local textures despite its simple and lightweight structure. However, RandConv has structural limitations in that the generated image easily loses semantics as the kernel size increases, and lacks the inherent diversity of a single convolution operation. To solve the problem, we propose a Progressive Random Convolution (Pro-RandConv) method that recursively stacks random convolution layers with a small kernel size instead of increasing the kernel size. This progressive approach can not only mitigate semantic distortions by reducing the influence of pixels away from the center in the theoretical receptive field, but also create more effective virtual domains by gradually increasing the style diversity. In addition, we develop a basic random convolution layer into a random convolution block including deformable offsets and affine transformation to support texture and contrast diversification, both of which are also randomly initialized. Without complex generators or adversarial learning, we demonstrate that our simple yet effective augmentation strategy outperforms state-of-the-art methods on single domain generalization benchmarks.
Improving Test-Time Adaptation via Shift-agnostic Weight Regularization and Nearest Source Prototypes
Jul 24, 2022
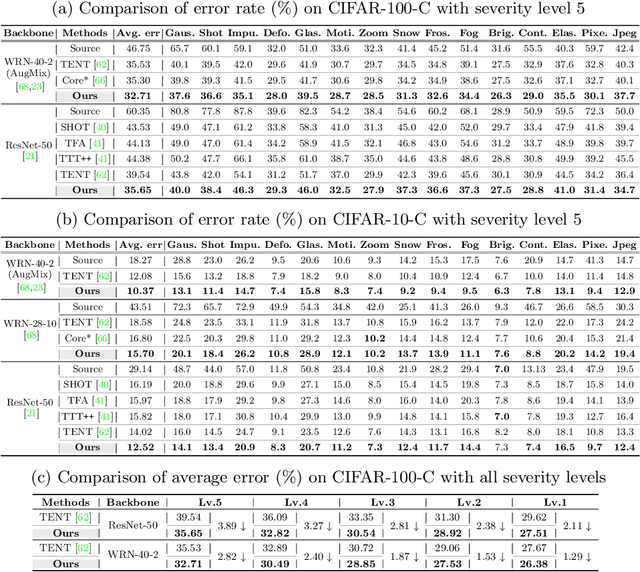

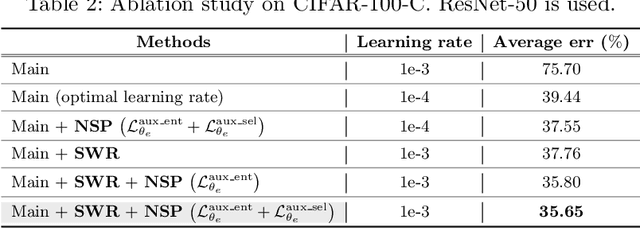
This paper proposes a novel test-time adaptation strategy that adjusts the model pre-trained on the source domain using only unlabeled online data from the target domain to alleviate the performance degradation due to the distribution shift between the source and target domains. Adapting the entire model parameters using the unlabeled online data may be detrimental due to the erroneous signals from an unsupervised objective. To mitigate this problem, we propose a shift-agnostic weight regularization that encourages largely updating the model parameters sensitive to distribution shift while slightly updating those insensitive to the shift, during test-time adaptation. This regularization enables the model to quickly adapt to the target domain without performance degradation by utilizing the benefit of a high learning rate. In addition, we present an auxiliary task based on nearest source prototypes to align the source and target features, which helps reduce the distribution shift and leads to further performance improvement. We show that our method exhibits state-of-the-art performance on various standard benchmarks and even outperforms its supervised counterpart.
QTI Submission to DCASE 2021: residual normalization for device-imbalanced acoustic scene classification with efficient design
Jun 28, 2022
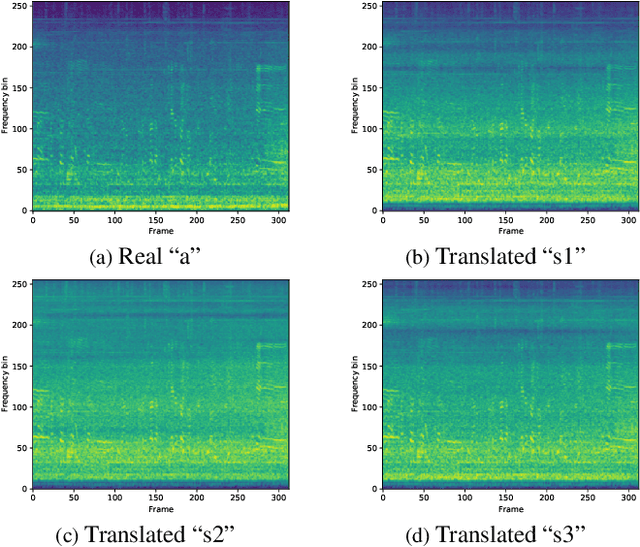
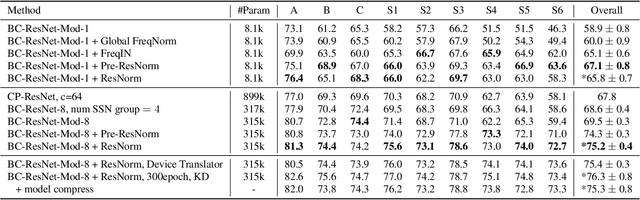
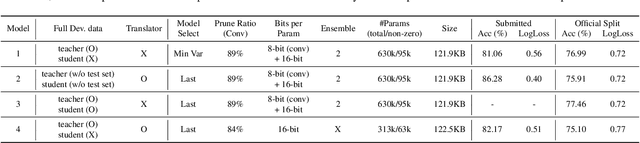
This technical report describes the details of our TASK1A submission of the DCASE2021 challenge. The goal of the task is to design an audio scene classification system for device-imbalanced datasets under the constraints of model complexity. This report introduces four methods to achieve the goal. First, we propose Residual Normalization, a novel feature normalization method that uses instance normalization with a shortcut path to discard unnecessary device-specific information without losing useful information for classification. Second, we design an efficient architecture, BC-ResNet-Mod, a modified version of the baseline architecture with a limited receptive field. Third, we exploit spectrogram-to-spectrogram translation from one to multiple devices to augment training data. Finally, we utilize three model compression schemes: pruning, quantization, and knowledge distillation to reduce model complexity. The proposed system achieves an average test accuracy of 76.3% in TAU Urban Acoustic Scenes 2020 Mobile, development dataset with 315k parameters, and average test accuracy of 75.3% after compression to 61.0KB of non-zero parameters.
Personalized Keyword Spotting through Multi-task Learning
Jun 28, 2022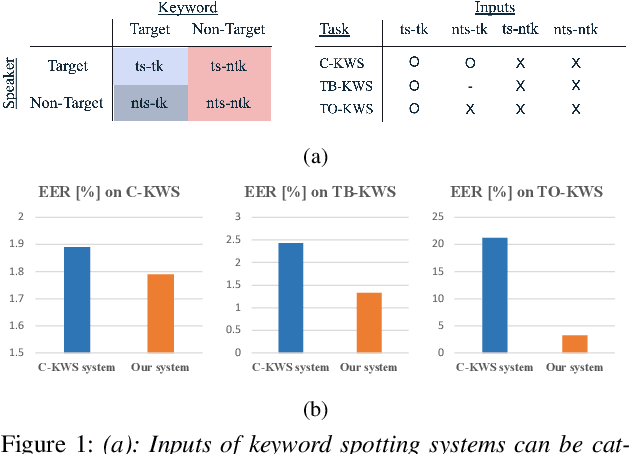
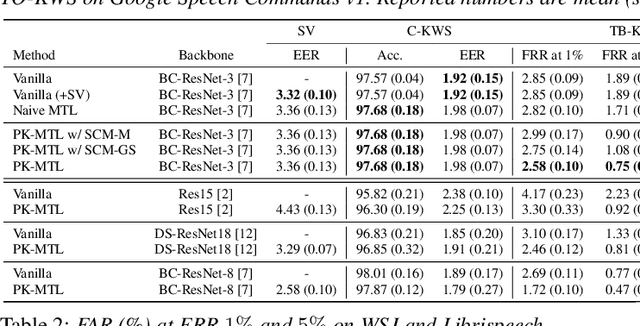
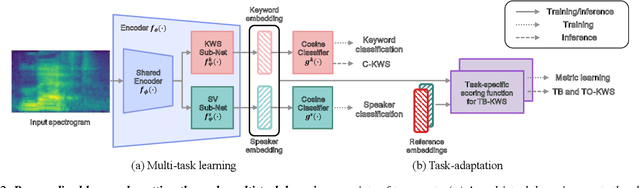
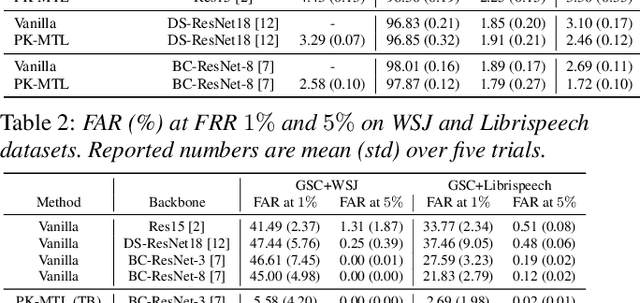
Keyword spotting (KWS) plays an essential role in enabling speech-based user interaction on smart devices, and conventional KWS (C-KWS) approaches have concentrated on detecting user-agnostic pre-defined keywords. However, in practice, most user interactions come from target users enrolled in the device which motivates to construct personalized keyword spotting. We design two personalized KWS tasks; (1) Target user Biased KWS (TB-KWS) and (2) Target user Only KWS (TO-KWS). To solve the tasks, we propose personalized keyword spotting through multi-task learning (PK-MTL) that consists of multi-task learning and task-adaptation. First, we introduce applying multi-task learning on keyword spotting and speaker verification to leverage user information to the keyword spotting system. Next, we design task-specific scoring functions to adapt to the personalized KWS tasks thoroughly. We evaluate our framework on conventional and personalized scenarios, and the results show that PK-MTL can dramatically reduce the false alarm rate, especially in various practical scenarios.